Release Notes¶
NumPy 1.13.0 Release Notes¶
This release supports Python 2.7 and 3.4 - 3.6.
Highlights¶
- Operations like
a + b + cwill reuse temporaries on some platforms, resulting in less memory use and faster execution.- Inplace operations check if inputs overlap outputs and create temporaries to avoid problems.
- New
__array_ufunc__attribute provides improved ability for classes to override default ufunc behavior.- New
np.blockfunction for creating blocked arrays.
New functions¶
- New
np.positiveufunc. - New
np.divmodufunc provides more efficient divmod. - New
np.isnatufunc tests for NaT special values. - New
np.heavisideufunc computes the Heaviside function. - New
np.isinfunction, improves onin1d. - New
np.blockfunction for creating blocked arrays. - New
PyArray_MapIterArrayCopyIfOverlapadded to NumPy C-API.
See below for details.
Deprecations¶
- Calling
np.fix,np.isposinf, andnp.isneginfwithf(x, y=out)is deprecated - the argument should be passed asf(x, out=out), which matches other ufunc-like interfaces. - Use of the C-API
NPY_CHARtype number deprecated since version 1.7 will now raise deprecation warnings at runtime. Extensions built with older f2py versions need to be recompiled to remove the warning. np.ma.argsort,np.ma.minimum.reduce, andnp.ma.maximum.reduceshould be called with an explicit axis argument when applied to arrays with more than 2 dimensions, as the default value of this argument (None) is inconsistent with the rest of numpy (-1,0, and0, respectively).np.ma.MaskedArray.miniis deprecated, as it almost duplicates the functionality ofnp.MaskedArray.min. Exactly equivalent behaviour can be obtained withnp.ma.minimum.reduce.- The single-argument form of
np.ma.minimumandnp.ma.maximumis deprecated.np.maximum.np.ma.minimum(x)should now be speltnp.ma.minimum.reduce(x), which is consistent with how this would be done withnp.minimum. - Calling
ndarray.conjugateon non-numeric dtypes is deprecated (it should match the behavior ofnp.conjugate, which throws an error). - Calling
expand_dimswhen theaxiskeyword does not satisfy-a.ndim - 1 <= axis <= a.ndim, whereais the array being reshaped, is deprecated.
Future Changes¶
- Assignment between structured arrays with different field names will change
in NumPy 1.14. Previously, fields in the dst would be set to the value of the
identically-named field in the src. In numpy 1.14 fields will instead be
assigned ‘by position’: The n-th field of the dst will be set to the n-th
field of the src array. Note that the
FutureWarningraised in NumPy 1.12 incorrectly reported this change as scheduled for NumPy 1.13 rather than NumPy 1.14.
Build System Changes¶
numpy.distutilsnow automatically determines C-file dependencies with GCC compatible compilers.
Compatibility notes¶
Error type changes¶
numpy.hstack()now throwsValueErrorinstead ofIndexErrorwhen input is empty.- Functions taking an axis argument, when that argument is out of range, now
throw
np.AxisErrorinstead of a mixture ofIndexErrorandValueError. For backwards compatibility,AxisErrorsubclasses both of these.
Tuple object dtypes¶
Support has been removed for certain obscure dtypes that were unintentionally
allowed, of the form (old_dtype, new_dtype), where either of the dtypes
is or contains the object dtype. As an exception, dtypes of the form
(object, [('name', object)]) are still supported due to evidence of
existing use.
DeprecationWarning to error¶
See Changes section for more detail.
partition, TypeError when non-integer partition index is used.NpyIter_AdvancedNew, ValueError whenoa_ndim == 0andop_axesis NULLnegative(bool_), TypeError when negative applied to booleans.subtract(bool_, bool_), TypeError when subtracting boolean from boolean.np.equal, np.not_equal, object identity doesn’t override failed comparison.np.equal, np.not_equal, object identity doesn’t override non-boolean comparison.- Deprecated boolean indexing behavior dropped. See Changes below for details.
- Deprecated
np.alterdot()andnp.restoredot()removed.
FutureWarning to changed behavior¶
See Changes section for more detail.
numpy.averagepreserves subclassesarray == Noneandarray != Nonedo element-wise comparison.np.equal, np.not_equal, object identity doesn’t override comparison result.
dtypes are now always true¶
Previously bool(dtype) would fall back to the default python
implementation, which checked if len(dtype) > 0. Since dtype objects
implement __len__ as the number of record fields, bool of scalar dtypes
would evaluate to False, which was unintuitive. Now bool(dtype) == True
for all dtypes.
__getslice__ and __setslice__ are no longer needed in ndarray subclasses¶
When subclassing np.ndarray in Python 2.7, it is no longer _necessary_ to
implement __*slice__ on the derived class, as __*item__ will intercept
these calls correctly.
Any code that did implement these will work exactly as before. Code that
invokes``ndarray.__getslice__`` (e.g. through super(...).__getslice__) will
now issue a DeprecationWarning - .__getitem__(slice(start, end)) should be
used instead.
Indexing MaskedArrays/Constants with ... (ellipsis) now returns MaskedArray¶
This behavior mirrors that of np.ndarray, and accounts for nested arrays in MaskedArrays of object dtype, and ellipsis combined with other forms of indexing.
C API changes¶
GUfuncs on empty arrays and NpyIter axis removal¶
It is now allowed to remove a zero-sized axis from NpyIter. Which may mean that code removing axes from NpyIter has to add an additional check when accessing the removed dimensions later on.
The largest followup change is that gufuncs are now allowed to have zero-sized inner dimensions. This means that a gufunc now has to anticipate an empty inner dimension, while this was never possible and an error raised instead.
For most gufuncs no change should be necessary. However, it is now possible
for gufuncs with a signature such as (..., N, M) -> (..., M) to return
a valid result if N=0 without further wrapping code.
PyArray_MapIterArrayCopyIfOverlap added to NumPy C-API¶
Similar to PyArray_MapIterArray but with an additional copy_if_overlap
argument. If copy_if_overlap != 0, checks if input has memory overlap with
any of the other arrays and make copies as appropriate to avoid problems if the
input is modified during the iteration. See the documentation for more complete
documentation.
New Features¶
__array_ufunc__ added¶
This is the renamed and redesigned __numpy_ufunc__. Any class, ndarray
subclass or not, can define this method or set it to None in order to
override the behavior of NumPy’s ufuncs. This works quite similarly to Python’s
__mul__ and other binary operation routines. See the documentation for a
more detailed description of the implementation and behavior of this new
option. The API is provisional, we do not yet guarantee backward compatibility
as modifications may be made pending feedback. See the NEP and
documentation for more details.
New positive ufunc¶
This ufunc corresponds to unary +, but unlike + on an ndarray it will raise an error if array values do not support numeric operations.
New divmod ufunc¶
This ufunc corresponds to the Python builtin divmod, and is used to implement
divmod when called on numpy arrays. np.divmod(x, y) calculates a result
equivalent to (np.floor_divide(x, y), np.remainder(x, y)) but is
approximately twice as fast as calling the functions separately.
np.isnat ufunc tests for NaT special datetime and timedelta values¶
The new ufunc np.isnat finds the positions of special NaT values
within datetime and timedelta arrays. This is analogous to np.isnan.
np.heaviside ufunc computes the Heaviside function¶
The new function np.heaviside(x, h0) (a ufunc) computes the Heaviside
function:
{ 0 if x < 0,
heaviside(x, h0) = { h0 if x == 0,
{ 1 if x > 0.
np.block function for creating blocked arrays¶
Add a new block function to the current stacking functions vstack,
hstack, and stack. This allows concatenation across multiple axes
simultaneously, with a similar syntax to array creation, but where elements
can themselves be arrays. For instance:
>>> A = np.eye(2) * 2
>>> B = np.eye(3) * 3
>>> np.block([
... [A, np.zeros((2, 3))],
... [np.ones((3, 2)), B ]
... ])
array([[ 2., 0., 0., 0., 0.],
[ 0., 2., 0., 0., 0.],
[ 1., 1., 3., 0., 0.],
[ 1., 1., 0., 3., 0.],
[ 1., 1., 0., 0., 3.]])
While primarily useful for block matrices, this works for arbitrary dimensions of arrays.
It is similar to Matlab’s square bracket notation for creating block matrices.
isin function, improving on in1d¶
The new function isin tests whether each element of an N-dimensonal
array is present anywhere within a second array. It is an enhancement
of in1d that preserves the shape of the first array.
Temporary elision¶
On platforms providing the backtrace function NumPy will try to avoid
creating temporaries in expression involving basic numeric types.
For example d = a + b + c is transformed to d = a + b; d += c which can
improve performance for large arrays as less memory bandwidth is required to
perform the operation.
axes argument for unique¶
In an N-dimensional array, the user can now choose the axis along which to look
for duplicate N-1-dimensional elements using numpy.unique. The original
behaviour is recovered if axis=None (default).
np.gradient now supports unevenly spaced data¶
Users can now specify a not-constant spacing for data.
In particular np.gradient can now take:
- A single scalar to specify a sample distance for all dimensions.
- N scalars to specify a constant sample distance for each dimension.
i.e.
dx,dy,dz, ... - N arrays to specify the coordinates of the values along each dimension of F. The length of the array must match the size of the corresponding dimension
- Any combination of N scalars/arrays with the meaning of 2. and 3.
This means that, e.g., it is now possible to do the following:
>>> f = np.array([[1, 2, 6], [3, 4, 5]], dtype=np.float)
>>> dx = 2.
>>> y = [1., 1.5, 3.5]
>>> np.gradient(f, dx, y)
[array([[ 1. , 1. , -0.5], [ 1. , 1. , -0.5]]),
array([[ 2. , 2. , 2. ], [ 2. , 1.7, 0.5]])]
Support for returning arrays of arbitrary dimensions in apply_along_axis¶
Previously, only scalars or 1D arrays could be returned by the function passed
to apply_along_axis. Now, it can return an array of any dimensionality
(including 0D), and the shape of this array replaces the axis of the array
being iterated over.
.ndim property added to dtype to complement .shape¶
For consistency with ndarray and broadcast, d.ndim is a shorthand
for len(d.shape).
Support for tracemalloc in Python 3.6¶
NumPy now supports memory tracing with tracemalloc module of Python 3.6 or
newer. Memory allocations from NumPy are placed into the domain defined by
numpy.lib.tracemalloc_domain.
Note that NumPy allocation will not show up in tracemalloc of earlier Python
versions.
NumPy may be built with relaxed stride checking debugging¶
Setting NPY_RELAXED_STRIDES_DEBUG=1 in the environment when relaxed stride checking is enabled will cause NumPy to be compiled with the affected strides set to the maximum value of npy_intp in order to help detect invalid usage of the strides in downstream projects. When enabled, invalid usage often results in an error being raised, but the exact type of error depends on the details of the code. TypeError and OverflowError have been observed in the wild.
It was previously the case that this option was disabled for releases and enabled in master and changing between the two required editing the code. It is now disabled by default but can be enabled for test builds.
Improvements¶
Ufunc behavior for overlapping inputs¶
Operations where ufunc input and output operands have memory overlap produced undefined results in previous NumPy versions, due to data dependency issues. In NumPy 1.13.0, results from such operations are now defined to be the same as for equivalent operations where there is no memory overlap.
Operations affected now make temporary copies, as needed to eliminate data dependency. As detecting these cases is computationally expensive, a heuristic is used, which may in rare cases result to needless temporary copies. For operations where the data dependency is simple enough for the heuristic to analyze, temporary copies will not be made even if the arrays overlap, if it can be deduced copies are not necessary. As an example,``np.add(a, b, out=a)`` will not involve copies.
To illustrate a previously undefined operation:
>>> x = np.arange(16).astype(float)
>>> np.add(x[1:], x[:-1], out=x[1:])
In NumPy 1.13.0 the last line is guaranteed to be equivalent to:
>>> np.add(x[1:].copy(), x[:-1].copy(), out=x[1:])
A similar operation with simple non-problematic data dependence is:
>>> x = np.arange(16).astype(float)
>>> np.add(x[1:], x[:-1], out=x[:-1])
It will continue to produce the same results as in previous NumPy versions, and will not involve unnecessary temporary copies.
The change applies also to in-place binary operations, for example:
>>> x = np.random.rand(500, 500)
>>> x += x.T
This statement is now guaranteed to be equivalent to x[...] = x + x.T,
whereas in previous NumPy versions the results were undefined.
Partial support for 64-bit f2py extensions with MinGW¶
Extensions that incorporate Fortran libraries can now be built using the free MinGW toolset, also under Python 3.5. This works best for extensions that only do calculations and uses the runtime modestly (reading and writing from files, for instance). Note that this does not remove the need for Mingwpy; if you make extensive use of the runtime, you will most likely run into issues. Instead, it should be regarded as a band-aid until Mingwpy is fully functional.
Extensions can also be compiled using the MinGW toolset using the runtime library from the (moveable) WinPython 3.4 distribution, which can be useful for programs with a PySide1/Qt4 front-end.
Performance improvements for packbits and unpackbits¶
The functions numpy.packbits with boolean input and numpy.unpackbits have
been optimized to be a significantly faster for contiguous data.
Fix for PPC long double floating point information¶
In previous versions of NumPy, the finfo function returned invalid
information about the double double format of the longdouble float type
on Power PC (PPC). The invalid values resulted from the failure of the NumPy
algorithm to deal with the variable number of digits in the significand
that are a feature of PPC long doubles. This release by-passes the failing
algorithm by using heuristics to detect the presence of the PPC double double
format. A side-effect of using these heuristics is that the finfo
function is faster than previous releases.
Better default repr for ndarray subclasses¶
Subclasses of ndarray with no repr specialization now correctly indent
their data and type lines.
More reliable comparisons of masked arrays¶
Comparisons of masked arrays were buggy for masked scalars and failed for
structured arrays with dimension higher than one. Both problems are now
solved. In the process, it was ensured that in getting the result for a
structured array, masked fields are properly ignored, i.e., the result is equal
if all fields that are non-masked in both are equal, thus making the behaviour
identical to what one gets by comparing an unstructured masked array and then
doing .all() over some axis.
np.matrix with booleans elements can now be created using the string syntax¶
np.matrix failed whenever one attempts to use it with booleans, e.g.,
np.matrix('True'). Now, this works as expected.
More linalg operations now accept empty vectors and matrices¶
All of the following functions in np.linalg now work when given input
arrays with a 0 in the last two dimensions: det, slogdet, pinv,
eigvals, eigvalsh, eig, eigh.
Bundled version of LAPACK is now 3.2.2¶
NumPy comes bundled with a minimal implementation of lapack for systems without
a lapack library installed, under the name of lapack_lite. This has been
upgraded from LAPACK 3.0.0 (June 30, 1999) to LAPACK 3.2.2 (June 30, 2010). See
the LAPACK changelogs for details on the all the changes this entails.
While no new features are exposed through numpy, this fixes some bugs
regarding “workspace” sizes, and in some places may use faster algorithms.
reduce of np.hypot.reduce and np.logical_xor allowed in more cases¶
This now works on empty arrays, returning 0, and can reduce over multiple axes.
Previously, a ValueError was thrown in these cases.
Better repr of object arrays¶
Object arrays that contain themselves no longer cause a recursion error.
Object arrays that contain list objects are now printed in a way that makes
clear the difference between a 2d object array, and a 1d object array of lists.
Changes¶
argsort on masked arrays takes the same default arguments as sort¶
By default, argsort now places the masked values at the end of the sorted
array, in the same way that sort already did. Additionally, the
end_with argument is added to argsort, for consistency with sort.
Note that this argument is not added at the end, so breaks any code that
passed fill_value as a positional argument.
average now preserves subclasses¶
For ndarray subclasses, numpy.average will now return an instance of the
subclass, matching the behavior of most other NumPy functions such as mean.
As a consequence, also calls that returned a scalar may now return a subclass
array scalar.
array == None and array != None do element-wise comparison¶
Previously these operations returned scalars False and True respectively.
np.equal, np.not_equal for object arrays ignores object identity¶
Previously, these functions always treated identical objects as equal. This had the effect of overriding comparison failures, comparison of objects that did not return booleans, such as np.arrays, and comparison of objects where the results differed from object identity, such as NaNs.
Boolean indexing changes¶
- Boolean array-likes (such as lists of python bools) are always treated as boolean indexes.
- Boolean scalars (including python
True) are legal boolean indexes and never treated as integers. - Boolean indexes must match the dimension of the axis that they index.
- Boolean indexes used on the lhs of an assignment must match the dimensions of the rhs.
- Boolean indexing into scalar arrays return a new 1-d array. This means that
array(1)[array(True)]givesarray([1])and not the original array.
np.random.multivariate_normal behavior with bad covariance matrix¶
It is now possible to adjust the behavior the function will have when dealing with the covariance matrix by using two new keyword arguments:
tolcan be used to specify a tolerance to use when checking that the covariance matrix is positive semidefinite.check_validcan be used to configure what the function will do in the presence of a matrix that is not positive semidefinite. Valid options areignore,warnandraise. The default value,warnkeeps the the behavior used on previous releases.
assert_array_less compares np.inf and -np.inf now¶
Previously, np.testing.assert_array_less ignored all infinite values. This
is not the expected behavior both according to documentation and intuitively.
Now, -inf < x < inf is considered True for any real number x and all
other cases fail.
assert_array_ and masked arrays assert_equal hide less warnings¶
Some warnings that were previously hidden by the assert_array_
functions are not hidden anymore. In most cases the warnings should be
correct and, should they occur, will require changes to the tests using
these functions.
For the masked array assert_equal version, warnings may occur when
comparing NaT. The function presently does not handle NaT or NaN
specifically and it may be best to avoid it at this time should a warning
show up due to this change.
offset attribute value in memmap objects¶
The offset attribute in a memmap object is now set to the
offset into the file. This is a behaviour change only for offsets
greater than mmap.ALLOCATIONGRANULARITY.
np.real and np.imag return scalars for scalar inputs¶
Previously, np.real and np.imag used to return array objects when
provided a scalar input, which was inconsistent with other functions like
np.angle and np.conj.
The polynomial convenience classes cannot be passed to ufuncs¶
The ABCPolyBase class, from which the convenience classes are derived, sets
__array_ufun__ = None in order of opt out of ufuncs. If a polynomial
convenience class instance is passed as an argument to a ufunc, a TypeError
will now be raised.
Output arguments to ufuncs can be tuples also for ufunc methods¶
For calls to ufuncs, it was already possible, and recommended, to use an
out argument with a tuple for ufuncs with multiple outputs. This has now
been extended to output arguments in the reduce, accumulate, and
reduceat methods. This is mostly for compatibility with __array_ufunc;
there are no ufuncs yet that have more than one output.
NumPy 1.12.1 Release Notes¶
NumPy 1.12.1 supports Python 2.7 and 3.4 - 3.6 and fixes bugs and regressions found in NumPy 1.12.0. In particular, the regression in f2py constant parsing is fixed. Wheels for Linux, Windows, and OSX can be found on pypi,
Contributors¶
A total of 10 people contributed to this release. People with a “+” by their names contributed a patch for the first time.
- Charles Harris
- Eric Wieser
- Greg Young
- Joerg Behrmann +
- John Kirkham
- Julian Taylor
- Marten van Kerkwijk
- Matthew Brett
- Shota Kawabuchi
- Jean Utke +
Fixes Backported¶
- #8483: BUG: Fix wrong future nat warning and equiv type logic error...
- #8489: BUG: Fix wrong masked median for some special cases
- #8490: DOC: Place np.average in inline code
- #8491: TST: Work around isfinite inconsistency on i386
- #8494: BUG: Guard against replacing constants without ‘_’ spec in f2py.
- #8524: BUG: Fix mean for float 16 non-array inputs for 1.12
- #8571: BUG: Fix calling python api with error set and minor leaks for...
- #8602: BUG: Make iscomplexobj compatible with custom dtypes again
- #8618: BUG: Fix undefined behaviour induced by bad __array_wrap__
- #8648: BUG: Fix MaskedArray.__setitem__
- #8659: BUG: PPC64el machines are POWER for Fortran in f2py
- #8665: BUG: Look up methods on MaskedArray in _frommethod
- #8674: BUG: Remove extra digit in binary_repr at limit
- #8704: BUG: Fix deepcopy regression for empty arrays.
- #8707: BUG: Fix ma.median for empty ndarrays
NumPy 1.12.0 Release Notes¶
This release supports Python 2.7 and 3.4 - 3.6.
Highlights¶
The NumPy 1.12.0 release contains a large number of fixes and improvements, but few that stand out above all others. That makes picking out the highlights somewhat arbitrary but the following may be of particular interest or indicate areas likely to have future consequences.
- Order of operations in
np.einsumcan now be optimized for large speed improvements. - New
signatureargument tonp.vectorizefor vectorizing with core dimensions. - The
keepdimsargument was added to many functions. - New context manager for testing warnings
- Support for BLIS in numpy.distutils
- Much improved support for PyPy (not yet finished)
Dropped Support¶
- Support for Python 2.6, 3.2, and 3.3 has been dropped.
Added Support¶
- Support for PyPy 2.7 v5.6.0 has been added. While not complete (nditer
updateifcopyis not supported yet), this is a milestone for PyPy’s C-API compatibility layer.
Build System Changes¶
- Library order is preserved, instead of being reordered to match that of the directories.
Deprecations¶
Assignment of ndarray object’s data attribute¶
Assigning the ‘data’ attribute is an inherently unsafe operation as pointed out in gh-7083. Such a capability will be removed in the future.
Unsafe int casting of the num attribute in linspace¶
np.linspace now raises DeprecationWarning when num cannot be safely
interpreted as an integer.
Insufficient bit width parameter to binary_repr¶
If a ‘width’ parameter is passed into binary_repr that is insufficient to
represent the number in base 2 (positive) or 2’s complement (negative) form,
the function used to silently ignore the parameter and return a representation
using the minimal number of bits needed for the form in question. Such behavior
is now considered unsafe from a user perspective and will raise an error in the
future.
Future Changes¶
- In 1.13 NAT will always compare False except for
NAT != NAT, which will be True. In short, NAT will behave like NaN - In 1.13
np.averagewill preserve subclasses, to match the behavior of most other numpy functions such as np.mean. In particular, this means calls which returned a scalar may return a 0-d subclass object instead.
Multiple-field manipulation of structured arrays¶
In 1.13 the behavior of structured arrays involving multiple fields will change in two ways:
First, indexing a structured array with multiple fields (eg,
arr[['f1', 'f3']]) will return a view into the original array in 1.13,
instead of a copy. Note the returned view will have extra padding bytes
corresponding to intervening fields in the original array, unlike the copy in
1.12, which will affect code such as arr[['f1', 'f3']].view(newdtype).
Second, for numpy versions 1.6 to 1.12 assignment between structured arrays occurs “by field name”: Fields in the destination array are set to the identically-named field in the source array or to 0 if the source does not have a field:
>>> a = np.array([(1,2),(3,4)], dtype=[('x', 'i4'), ('y', 'i4')])
>>> b = np.ones(2, dtype=[('z', 'i4'), ('y', 'i4'), ('x', 'i4')])
>>> b[:] = a
>>> b
array([(0, 2, 1), (0, 4, 3)],
dtype=[('z', '<i4'), ('y', '<i4'), ('x', '<i4')])
In 1.13 assignment will instead occur “by position”: The Nth field of the
destination will be set to the Nth field of the source regardless of field
name. The old behavior can be obtained by using indexing to reorder the fields
before
assignment, e.g., b[['x', 'y']] = a[['y', 'x']].
Compatibility notes¶
DeprecationWarning to error¶
- Indexing with floats raises
IndexError, e.g., a[0, 0.0]. - Indexing with non-integer array_like raises
IndexError, e.g.,a['1', '2'] - Indexing with multiple ellipsis raises
IndexError, e.g.,a[..., ...]. - Non-integers used as index values raise
TypeError, e.g., inreshape,take, and specifying reduce axis.
FutureWarning to changed behavior¶
np.fullnow returns an array of the fill-value’s dtype if no dtype is given, instead of defaulting to float.np.averagewill emit a warning if the argument is a subclass of ndarray, as the subclass will be preserved starting in 1.13. (see Future Changes)
power and ** raise errors for integer to negative integer powers¶
The previous behavior depended on whether numpy scalar integers or numpy integer arrays were involved.
For arrays
- Zero to negative integer powers returned least integral value.
- Both 1, -1 to negative integer powers returned correct values.
- The remaining integers returned zero when raised to negative integer powers.
For scalars
- Zero to negative integer powers returned least integral value.
- Both 1, -1 to negative integer powers returned correct values.
- The remaining integers sometimes returned zero, sometimes the correct float depending on the integer type combination.
All of these cases now raise a ValueError except for those integer
combinations whose common type is float, for instance uint64 and int8. It was
felt that a simple rule was the best way to go rather than have special
exceptions for the integer units. If you need negative powers, use an inexact
type.
Relaxed stride checking is the default¶
This will have some impact on code that assumed that F_CONTIGUOUS and
C_CONTIGUOUS were mutually exclusive and could be set to determine the
default order for arrays that are now both.
The np.percentile ‘midpoint’ interpolation method fixed for exact indices¶
The ‘midpoint’ interpolator now gives the same result as ‘lower’ and ‘higher’ when the two coincide. Previous behavior of ‘lower’ + 0.5 is fixed.
keepdims kwarg is passed through to user-class methods¶
numpy functions that take a keepdims kwarg now pass the value
through to the corresponding methods on ndarray sub-classes. Previously the
keepdims keyword would be silently dropped. These functions now have
the following behavior:
- If user does not provide
keepdims, no keyword is passed to the underlying method. - Any user-provided value of
keepdimsis passed through as a keyword argument to the method.
This will raise in the case where the method does not support a
keepdims kwarg and the user explicitly passes in keepdims.
The following functions are changed: sum, product,
sometrue, alltrue, any, all, amax, amin,
prod, mean, std, var, nanmin, nanmax,
nansum, nanprod, nanmean, nanmedian, nanvar,
nanstd
bitwise_and identity changed¶
The previous identity was 1, it is now -1. See entry in Improvements for more explanation.
ma.median warns and returns nan when unmasked invalid values are encountered¶
Similar to unmasked median the masked median ma.median now emits a Runtime warning and returns NaN in slices where an unmasked NaN is present.
Greater consistancy in assert_almost_equal¶
The precision check for scalars has been changed to match that for arrays. It is now:
abs(actual - desired) < 1.5 * 10**(-decimal)
Note that this is looser than previously documented, but agrees with the
previous implementation used in assert_array_almost_equal. Due to the
change in implementation some very delicate tests may fail that did not
fail before.
NoseTester behaviour of warnings during testing¶
When raise_warnings="develop" is given, all uncaught warnings will now
be considered a test failure. Previously only selected ones were raised.
Warnings which are not caught or raised (mostly when in release mode)
will be shown once during the test cycle similar to the default python
settings.
assert_warns and deprecated decorator more specific¶
The assert_warns function and context manager are now more specific
to the given warning category. This increased specificity leads to them
being handled according to the outer warning settings. This means that
no warning may be raised in cases where a wrong category warning is given
and ignored outside the context. Alternatively the increased specificity
may mean that warnings that were incorrectly ignored will now be shown
or raised. See also the new suppress_warnings context manager.
The same is true for the deprecated decorator.
C API¶
No changes.
New Features¶
Writeable keyword argument for as_strided¶
np.lib.stride_tricks.as_strided now has a writeable
keyword argument. It can be set to False when no write operation
to the returned array is expected to avoid accidental
unpredictable writes.
axes keyword argument for rot90¶
The axes keyword argument in rot90 determines the plane in which the
array is rotated. It defaults to axes=(0,1) as in the original function.
Generalized flip¶
flipud and fliplr reverse the elements of an array along axis=0 and
axis=1 respectively. The newly added flip function reverses the elements of
an array along any given axis.
np.count_nonzeronow has anaxisparameter, allowing non-zero counts to be generated on more than just a flattened array object.
BLIS support in numpy.distutils¶
Building against the BLAS implementation provided by the BLIS library is now
supported. See the [blis] section in site.cfg.example (in the root of
the numpy repo or source distribution).
Hook in numpy/__init__.py to run distribution-specific checks¶
Binary distributions of numpy may need to run specific hardware checks or load specific libraries during numpy initialization. For example, if we are distributing numpy with a BLAS library that requires SSE2 instructions, we would like to check the machine on which numpy is running does have SSE2 in order to give an informative error.
Add a hook in numpy/__init__.py to import a numpy/_distributor_init.py
file that will remain empty (bar a docstring) in the standard numpy source,
but that can be overwritten by people making binary distributions of numpy.
New nanfunctions nancumsum and nancumprod added¶
Nan-functions nancumsum and nancumprod have been added to
compute cumsum and cumprod by ignoring nans.
np.interp can now interpolate complex values¶
np.lib.interp(x, xp, fp) now allows the interpolated array fp
to be complex and will interpolate at complex128 precision.
New polynomial evaluation function polyvalfromroots added¶
The new function polyvalfromroots evaluates a polynomial at given points
from the roots of the polynomial. This is useful for higher order polynomials,
where expansion into polynomial coefficients is inaccurate at machine
precision.
New array creation function geomspace added¶
The new function geomspace generates a geometric sequence. It is similar
to logspace, but with start and stop specified directly:
geomspace(start, stop) behaves the same as
logspace(log10(start), log10(stop)).
New context manager for testing warnings¶
A new context manager suppress_warnings has been added to the testing
utils. This context manager is designed to help reliably test warnings.
Specifically to reliably filter/ignore warnings. Ignoring warnings
by using an “ignore” filter in Python versions before 3.4.x can quickly
result in these (or similar) warnings not being tested reliably.
The context manager allows to filter (as well as record) warnings similar
to the catch_warnings context, but allows for easier specificity.
Also printing warnings that have not been filtered or nesting the
context manager will work as expected. Additionally, it is possible
to use the context manager as a decorator which can be useful when
multiple tests give need to hide the same warning.
New masked array functions ma.convolve and ma.correlate added¶
These functions wrapped the non-masked versions, but propagate through masked values. There are two different propagation modes. The default causes masked values to contaminate the result with masks, but the other mode only outputs masks if there is no alternative.
New float_power ufunc¶
The new float_power ufunc is like the power function except all
computation is done in a minimum precision of float64. There was a long
discussion on the numpy mailing list of how to treat integers to negative
integer powers and a popular proposal was that the __pow__ operator should
always return results of at least float64 precision. The float_power
function implements that option. Note that it does not support object arrays.
np.loadtxt now supports a single integer as usecol argument¶
Instead of using usecol=(n,) to read the nth column of a file
it is now allowed to use usecol=n. Also the error message is
more user friendly when a non-integer is passed as a column index.
Improved automated bin estimators for histogram¶
Added ‘doane’ and ‘sqrt’ estimators to histogram via the bins
argument. Added support for range-restricted histograms with automated
bin estimation.
np.roll can now roll multiple axes at the same time¶
The shift and axis arguments to roll are now broadcast against each
other, and each specified axis is shifted accordingly.
The __complex__ method has been implemented for the ndarrays¶
Calling complex() on a size 1 array will now cast to a python
complex.
pathlib.Path objects now supported¶
The standard np.load, np.save, np.loadtxt, np.savez, and similar
functions can now take pathlib.Path objects as an argument instead of a
filename or open file object.
New bits attribute for np.finfo¶
This makes np.finfo consistent with np.iinfo which already has that
attribute.
New signature argument to np.vectorize¶
This argument allows for vectorizing user defined functions with core
dimensions, in the style of NumPy’s
generalized universal functions. This allows
for vectorizing a much broader class of functions. For example, an arbitrary
distance metric that combines two vectors to produce a scalar could be
vectorized with signature='(n),(n)->()'. See np.vectorize for full
details.
Emit py3kwarnings for division of integer arrays¶
To help people migrate their code bases from Python 2 to Python 3, the python interpreter has a handy option -3, which issues warnings at runtime. One of its warnings is for integer division:
$ python -3 -c "2/3"
-c:1: DeprecationWarning: classic int division
In Python 3, the new integer division semantics also apply to numpy arrays. With this version, numpy will emit a similar warning:
$ python -3 -c "import numpy as np; np.array(2)/np.array(3)"
-c:1: DeprecationWarning: numpy: classic int division
numpy.sctypes now includes bytes on Python3 too¶
Previously, it included str (bytes) and unicode on Python2, but only str (unicode) on Python3.
Improvements¶
bitwise_and identity changed¶
The previous identity was 1 with the result that all bits except the LSB were masked out when the reduce method was used. The new identity is -1, which should work properly on twos complement machines as all bits will be set to one.
Generalized Ufuncs will now unlock the GIL¶
Generalized Ufuncs, including most of the linalg module, will now unlock the Python global interpreter lock.
Caches in np.fft are now bounded in total size and item count¶
The caches in np.fft that speed up successive FFTs of the same length can no longer grow without bounds. They have been replaced with LRU (least recently used) caches that automatically evict no longer needed items if either the memory size or item count limit has been reached.
Improved handling of zero-width string/unicode dtypes¶
Fixed several interfaces that explicitly disallowed arrays with zero-width
string dtypes (i.e. dtype('S0') or dtype('U0'), and fixed several
bugs where such dtypes were not handled properly. In particular, changed
ndarray.__new__ to not implicitly convert dtype('S0') to
dtype('S1') (and likewise for unicode) when creating new arrays.
Integer ufuncs vectorized with AVX2¶
If the cpu supports it at runtime the basic integer ufuncs now use AVX2 instructions. This feature is currently only available when compiled with GCC.
Order of operations optimization in np.einsum¶
np.einsum now supports the optimize argument which will optimize the
order of contraction. For example, np.einsum would complete the chain dot
example np.einsum(‘ij,jk,kl->il’, a, b, c) in a single pass which would
scale like N^4; however, when optimize=True np.einsum will create
an intermediate array to reduce this scaling to N^3 or effectively
np.dot(a, b).dot(c). Usage of intermediate tensors to reduce scaling has
been applied to the general einsum summation notation. See np.einsum_path
for more details.
quicksort has been changed to an introsort¶
The quicksort kind of np.sort and np.argsort is now an introsort which
is regular quicksort but changing to a heapsort when not enough progress is
made. This retains the good quicksort performance while changing the worst case
runtime from O(N^2) to O(N*log(N)).
ediff1d improved performance and subclass handling¶
The ediff1d function uses an array instead on a flat iterator for the subtraction. When to_begin or to_end is not None, the subtraction is performed in place to eliminate a copy operation. A side effect is that certain subclasses are handled better, namely astropy.Quantity, since the complete array is created, wrapped, and then begin and end values are set, instead of using concatenate.
Improved precision of ndarray.mean for float16 arrays¶
The computation of the mean of float16 arrays is now carried out in float32 for improved precision. This should be useful in packages such as Theano where the precision of float16 is adequate and its smaller footprint is desirable.
Changes¶
All array-like methods are now called with keyword arguments in fromnumeric.py¶
Internally, many array-like methods in fromnumeric.py were being called with positional arguments instead of keyword arguments as their external signatures were doing. This caused a complication in the downstream ‘pandas’ library that encountered an issue with ‘numpy’ compatibility. Now, all array-like methods in this module are called with keyword arguments instead.
Operations on np.memmap objects return numpy arrays in most cases¶
Previously operations on a memmap object would misleadingly return a memmap
instance even if the result was actually not memmapped. For example,
arr + 1 or arr + arr would return memmap instances, although no memory
from the output array is memmapped. Version 1.12 returns ordinary numpy arrays
from these operations.
Also, reduction of a memmap (e.g. .sum(axis=None) now returns a numpy
scalar instead of a 0d memmap.
stacklevel of warnings increased¶
The stacklevel for python based warnings was increased so that most warnings
will report the offending line of the user code instead of the line the
warning itself is given. Passing of stacklevel is now tested to ensure that
new warnings will receive the stacklevel argument.
This causes warnings with the “default” or “module” filter to be shown once for every offending user code line or user module instead of only once. On python versions before 3.4, this can cause warnings to appear that were falsely ignored before, which may be surprising especially in test suits.
Contributors¶
A total of 139 people contributed to this release. People with a “+” by their names contributed a patch for the first time.
- Aditya Panchal +
- Ales Erjavec +
- Alex Griffing
- Alexandr Shadchin +
- Alistair Muldal
- Allan Haldane
- Amit Aronovitch +
- Andrei Kucharavy +
- Antony Lee
- Antti Kaihola +
- Arne de Laat +
- Auke Wiggers +
- AustereCuriosity +
- Badhri Narayanan Krishnakumar +
- Ben North +
- Ben Rowland +
- Bertrand Lefebvre
- Boxiang Sun
- CJ Carey
- Charles Harris
- Christoph Gohlke
- Daniel Ching +
- Daniel Rasmussen +
- Daniel Smith +
- David Schaich +
- Denis Alevi +
- Devin Jeanpierre +
- Dmitry Odzerikho
- Dongjoon Hyun +
- Edward Richards +
- Ekaterina Tuzova +
- Emilien Kofman +
- Endolith
- Eren Sezener +
- Eric Moore
- Eric Quintero +
- Eric Wieser +
- Erik M. Bray
- Frederic Bastien
- Friedrich Dunne +
- Gerrit Holl
- Golnaz Irannejad +
- Graham Markall +
- Greg Knoll +
- Greg Young
- Gustavo Serra Scalet +
- Ines Wichert +
- Irvin Probst +
- Jaime Fernandez
- James Sanders +
- Jan David Mol +
- Jan Schlüter
- Jeremy Tuloup +
- John Kirkham
- John Zwinck +
- Jonathan Helmus
- Joseph Fox-Rabinovitz
- Josh Wilson +
- Joshua Warner +
- Julian Taylor
- Ka Wo Chen +
- Kamil Rytarowski +
- Kelsey Jordahl +
- Kevin Deldycke +
- Khaled Ben Abdallah Okuda +
- Lion Krischer +
- Loïc Estève +
- Luca Mussi +
- Mads Ohm Larsen +
- Manoj Kumar +
- Mario Emmenlauer +
- Marshall Bockrath-Vandegrift +
- Marshall Ward +
- Marten van Kerkwijk
- Mathieu Lamarre +
- Matthew Brett
- Matthew Harrigan +
- Matthias Geier
- Matti Picus +
- Meet Udeshi +
- Michael Felt +
- Michael Goerz +
- Michael Martin +
- Michael Seifert +
- Mike Nolta +
- Nathaniel Beaver +
- Nathaniel J. Smith
- Naveen Arunachalam +
- Nick Papior
- Nikola Forró +
- Oleksandr Pavlyk +
- Olivier Grisel
- Oren Amsalem +
- Pauli Virtanen
- Pavel Potocek +
- Pedro Lacerda +
- Peter Creasey +
- Phil Elson +
- Philip Gura +
- Phillip J. Wolfram +
- Pierre de Buyl +
- Raghav RV +
- Ralf Gommers
- Ray Donnelly +
- Rehas Sachdeva
- Rob Malouf +
- Robert Kern
- Samuel St-Jean
- Sanchez Gonzalez Alvaro +
- Saurabh Mehta +
- Scott Sanderson +
- Sebastian Berg
- Shayan Pooya +
- Shota Kawabuchi +
- Simon Conseil
- Simon Gibbons
- Sorin Sbarnea +
- Stefan van der Walt
- Stephan Hoyer
- Steven J Kern +
- Stuart Archibald
- Tadeu Manoel +
- Takuya Akiba +
- Thomas A Caswell
- Tom Bird +
- Tony Kelman +
- Toshihiro Kamishima +
- Valentin Valls +
- Varun Nayyar
- Victor Stinner +
- Warren Weckesser
- Wendell Smith
- Wojtek Ruszczewski +
- Xavier Abellan Ecija +
- Yaroslav Halchenko
- Yash Shah +
- Yinon Ehrlich +
- Yu Feng +
- nevimov +
Pull requests merged¶
A total of 418 pull requests were merged for this release.
- #4073: BUG: change real output checking to test if all imaginary parts...
- #4619: BUG : np.sum silently drops keepdims for sub-classes of ndarray
- #5488: ENH: add contract: optimizing numpy’s einsum expression
- #5706: ENH: make some masked array methods behave more like ndarray...
- #5822: Allow many distributions to have a scale of 0.
- #6054: WIP: MAINT: Add deprecation warning to views of multi-field indexes
- #6298: Check lower base limit in base_repr.
- #6430: Fix issues with zero-width string fields
- #6656: ENH: usecols now accepts an int when only one column has to be...
- #6660: Added pathlib support for several functions
- #6872: ENH: linear interpolation of complex values in lib.interp
- #6997: MAINT: Simplify mtrand.pyx helpers
- #7003: BUG: Fix string copying for np.place
- #7026: DOC: Clarify behavior in np.random.uniform
- #7055: BUG: One Element Array Inputs Return Scalars in np.random
- #7063: REL: Update master branch after 1.11.x branch has been made.
- #7073: DOC: Update the 1.11.0 release notes.
- #7076: MAINT: Update the git .mailmap file.
- #7082: TST, DOC: Added Broadcasting Tests in test_random.py
- #7087: BLD: fix compilation on non glibc-Linuxes
- #7088: BUG: Have norm cast non-floating point arrays to 64-bit float...
- #7090: ENH: Added ‘doane’ and ‘sqrt’ estimators to np.histogram in numpy.function_base
- #7091: Revert “BLD: fix compilation on non glibc-Linuxes”
- #7092: BLD: fix compilation on non glibc-Linuxes
- #7099: TST: Suppressed warnings
- #7102: MAINT: Removed conditionals that are always false in datetime_strings.c
- #7105: DEP: Deprecate as_strided returning a writable array as default
- #7109: DOC: update Python versions requirements in the install docs
- #7114: MAINT: Fix typos in docs
- #7116: TST: Fixed f2py test for win32 virtualenv
- #7118: TST: Fixed f2py test for non-versioned python executables
- #7119: BUG: Fixed mingw.lib error
- #7125: DOC: Updated documentation wording and examples for np.percentile.
- #7129: BUG: Fixed ‘midpoint’ interpolation of np.percentile in odd cases.
- #7131: Fix setuptools sdist
- #7133: ENH: savez: temporary file alongside with target file and improve...
- #7134: MAINT: Fix some typos in a code string and comments
- #7141: BUG: Unpickled void scalars should be contiguous
- #7144: MAINT: Change call_fortran into callfortran in comments.
- #7145: BUG: Fixed regressions in np.piecewise in ref to #5737 and #5729.
- #7147: Temporarily disable __numpy_ufunc__
- #7148: ENH,TST: Bump stacklevel and add tests for warnings
- #7149: TST: Add missing suffix to temppath manager
- #7152: BUG: mode kwargs passed as unicode to np.pad raises an exception
- #7156: BUG: Reascertain that linspace respects ndarray subclasses in...
- #7167: DOC: Update Wikipedia references for mtrand.pyx
- #7171: TST: Fixed f2py test for Anaconda non-win32
- #7174: DOC: Fix broken pandas link in release notes
- #7177: ENH: added axis param for np.count_nonzero
- #7178: BUG: Fix binary_repr for negative numbers
- #7180: BUG: Fixed previous attempt to fix dimension mismatch in nanpercentile
- #7181: DOC: Updated minor typos in function_base.py and test_function_base.py
- #7191: DOC: add vstack, hstack, dstack reference to stack documentation.
- #7193: MAINT: Removed supurious assert in histogram estimators
- #7194: BUG: Raise a quieter MaskedArrayFutureWarning for mask changes.
- #7195: STY: Drop some trailing spaces in
numpy.ma.core. - #7196: Revert “DOC: add vstack, hstack, dstack reference to stack documentation.”
- #7197: TST: Pin virtualenv used on Travis CI.
- #7198: ENH: Unlock the GIL for gufuncs
- #7199: MAINT: Cleanup for histogram bin estimator selection
- #7201: Raise IOError on not a file in python2
- #7202: MAINT: Made iterable return a boolean
- #7209: TST: Bump
virtualenvto 14.0.6 - #7211: DOC: Fix fmin examples
- #7215: MAINT: Use PySlice_GetIndicesEx instead of custom reimplementation
- #7229: ENH: implement __complex__
- #7231: MRG: allow distributors to run custom init
- #7232: BLD: Switch order of test for lapack_mkl and openblas_lapack
- #7239: DOC: Removed residual merge markup from previous commit
- #7240: Change ‘pubic’ to ‘public’.
- #7241: MAINT: update doc/sphinxext to numpydoc 0.6.0, and fix up some...
- #7243: ENH: Adding support to the range keyword for estimation of the...
- #7246: DOC: metion writeable keyword in as_strided in release notes
- #7247: TST: Fail quickly on AppVeyor for superseded PR builds
- #7248: DOC: remove link to documentation wiki editor from HOWTO_DOCUMENT.
- #7250: DOC,REL: Update 1.11.0 notes.
- #7251: BUG: only benchmark complex256 if it exists
- #7252: Forward port a fix and enhancement from 1.11.x
- #7253: DOC: note in h/v/dstack points users to stack/concatenate
- #7254: BUG: Enforce dtype for randint singletons
- #7256: MAINT: Use is None or is not None instead of == None or...
- #7257: DOC: Fix mismatched variable names in docstrings.
- #7258: ENH: Make numpy floor_divide and remainder agree with Python...
- #7260: BUG/TST: Fix #7259, do not “force scalar” for already scalar...
- #7261: Added self to mailmap
- #7266: BUG: Segfault for classes with deceptive __len__
- #7268: ENH: add geomspace function
- #7274: BUG: Preserve array order in np.delete
- #7275: DEP: Warn about assigning ‘data’ attribute of ndarray
- #7276: DOC: apply_along_axis missing whitespace inserted (before colon)
- #7278: BUG: Make returned unravel_index arrays writeable
- #7279: TST: Fixed elements being shuffled
- #7280: MAINT: Remove redundant trailing semicolons.
- #7285: BUG: Make Randint Backwards Compatible with Pandas
- #7286: MAINT: Fix typos in docs/comments of ma and polynomial modules.
- #7292: Clarify error on repr failure in assert_equal.
- #7294: ENH: add support for BLIS to numpy.distutils
- #7295: DOC: understanding code and getting started section to dev doc
- #7296: Revert part of #3907 which incorrectly propogated MaskedArray...
- #7299: DOC: Fix mismatched variable names in docstrings.
- #7300: DOC: dev: stop recommending keeping local master updated with...
- #7301: DOC: Update release notes
- #7305: BUG: Remove data race in mtrand: two threads could mutate the...
- #7307: DOC: Missing some characters in link.
- #7308: BUG: Incrementing the wrong reference on return
- #7310: STY: Fix GitHub rendering of ordered lists >9
- #7311: ENH: Make _pointer_type_cache functional
- #7313: DOC: corrected grammatical error in quickstart doc
- #7325: BUG, MAINT: Improve fromnumeric.py interface for downstream compatibility
- #7328: DEP: Deprecated using a float index in linspace
- #7331: Add comment, TST: fix MemoryError on win32
- #7332: Check for no solution in np.irr Fixes #6744
- #7338: TST: Install
pytzin the CI. - #7340: DOC: Fixed math rendering in tensordot docs.
- #7341: TST: Add test for #6469
- #7344: DOC: Fix more typos in docs and comments.
- #7346: Generalized flip
- #7347: ENH Generalized rot90
- #7348: Maint: Removed extra space from ureduce
- #7349: MAINT: Hide nan warnings for masked internal MA computations
- #7350: BUG: MA ufuncs should set mask to False, not array([False])
- #7351: TST: Fix some MA tests to avoid looking at the .data attribute
- #7358: BUG: pull request related to the issue #7353
- #7359: Update 7314, DOC: Clarify valid integer range for random.seed...
- #7361: MAINT: Fix copy and paste oversight.
- #7363: ENH: Make no unshare mask future warnings less noisy
- #7366: TST: fix #6542, add tests to check non-iterable argument raises...
- #7373: ENH: Add bitwise_and identity
- #7378: added NumPy logo and separator
- #7382: MAINT: cleanup np.average
- #7385: DOC: note about wheels / windows wheels for pypi
- #7386: Added label icon to Travis status
- #7397: BUG: incorrect type for objects whose __len__ fails
- #7398: DOC: fix typo
- #7404: Use PyMem_RawMalloc on Python 3.4 and newer
- #7406: ENH ufunc called on memmap return a ndarray
- #7407: BUG: Fix decref before incref for in-place accumulate
- #7410: DOC: add nanprod to the list of math routines
- #7414: Tweak corrcoef
- #7415: DOC: Documention fixes
- #7416: BUG: Incorrect handling of range in histogram with automatic...
- #7418: DOC: Minor typo fix, hermefik -> hermefit.
- #7421: ENH: adds np.nancumsum and np.nancumprod
- #7423: BUG: Ongoing fixes to PR#7416
- #7430: DOC: Update 1.11.0-notes.
- #7433: MAINT: FutureWarning for changes to np.average subclass handling
- #7437: np.full now defaults to the filling value’s dtype.
- #7438: Allow rolling multiple axes at the same time.
- #7439: BUG: Do not try sequence repeat unless necessary
- #7442: MANT: Simplify diagonal length calculation logic
- #7445: BUG: reference count leak in bincount, fixes #6805
- #7446: DOC: ndarray typo fix
- #7447: BUG: scalar integer negative powers gave wrong results.
- #7448: DOC: array “See also” link to full and full_like instead of fill
- #7456: BUG: int overflow in reshape, fixes #7455, fixes #7293
- #7463: BUG: fix array too big error for wide dtypes.
- #7466: BUG: segfault inplace object reduceat, fixes #7465
- #7468: BUG: more on inplace reductions, fixes #615
- #7469: MAINT: Update git .mailmap
- #7472: MAINT: Update .mailmap.
- #7477: MAINT: Yet more .mailmap updates for recent contributors.
- #7481: BUG: Fix segfault in PyArray_OrderConverter
- #7482: BUG: Memory Leak in _GenericBinaryOutFunction
- #7489: Faster real_if_close.
- #7491: DOC: Update subclassing doc regarding downstream compatibility
- #7496: BUG: don’t use pow for integer power ufunc loops.
- #7504: DOC: remove “arr” from keepdims docstrings
- #7505: MAIN: fix to #7382, make scl in np.average writeable
- #7507: MAINT: Remove nose.SkipTest import.
- #7508: DOC: link frompyfunc and vectorize
- #7511: numpy.power(0, 0) should return 1
- #7515: BUG: MaskedArray.count treats negative axes incorrectly
- #7518: BUG: Extend glibc complex trig functions blacklist to glibc <...
- #7521: DOC: rephrase writeup of memmap changes
- #7522: BUG: Fixed iteration over additional bad commands
- #7526: DOC: Removed an extra :const:
- #7529: BUG: Floating exception with invalid axis in np.lexsort
- #7534: MAINT: Update setup.py to reflect supported python versions.
- #7536: MAINT: Always use PyCapsule instead of PyCObject in mtrand.pyx
- #7539: MAINT: Cleanup of random stuff
- #7549: BUG: allow graceful recovery for no Liux compiler
- #7562: BUG: Fix test_from_object_array_unicode (test_defchararray.TestBasic)…
- #7565: BUG: Fix test_ctypeslib and test_indexing for debug interpreter
- #7566: MAINT: use manylinux1 wheel for cython
- #7568: Fix a false positive OverflowError in Python 3.x when value above...
- #7579: DOC: clarify purpose of Attributes section
- #7584: BUG: fixes #7572, percent in path
- #7586: Make np.ma.take works on scalars
- #7587: BUG: linalg.norm(): Don’t convert object arrays to float
- #7598: Cast array size to int64 when loading from archive
- #7602: DOC: Remove isreal and iscomplex from ufunc list
- #7605: DOC: fix incorrect Gamma distribution parameterization comments
- #7609: BUG: Fix TypeError when raising TypeError
- #7611: ENH: expose test runner raise_warnings option
- #7614: BLD: Avoid using os.spawnve in favor of os.spawnv in exec_command
- #7618: BUG: distance arg of np.gradient must be scalar, fix docstring
- #7626: DOC: RST definition list fixes
- #7627: MAINT: unify tup processing, move tup use to after all PyTuple_SetItem...
- #7630: MAINT: add ifdef around PyDictProxy_Check macro
- #7631: MAINT: linalg: fix comment, simplify math
- #7634: BLD: correct C compiler customization in system_info.py Closes...
- #7635: BUG: ma.median alternate fix for #7592
- #7636: MAINT: clean up testing.assert_raises_regexp, 2.6-specific code...
- #7637: MAINT: clearer exception message when importing multiarray fails.
- #7639: TST: fix a set of test errors in master.
- #7643: DOC : minor changes to linspace docstring
- #7651: BUG: one to any power is still 1. Broken edgecase for int arrays
- #7655: BLD: Remove Intel compiler flag -xSSE4.2
- #7658: BUG: fix incorrect printing of 1D masked arrays
- #7659: BUG: Temporary fix for str(mvoid) for object field types
- #7664: BUG: Fix unicode with byte swap transfer and copyswap
- #7667: Restore histogram consistency
- #7668: ENH: Do not check the type of module.__dict__ explicit in test.
- #7669: BUG: boolean assignment no GIL release when transfer needs API
- #7673: DOC: Create Numpy 1.11.1 release notes.
- #7675: BUG: fix handling of right edge of final bin.
- #7678: BUG: Fix np.clip bug NaN handling for Visual Studio 2015
- #7679: MAINT: Fix up C++ comment in arraytypes.c.src.
- #7681: DOC: Update 1.11.1 release notes.
- #7686: ENH: Changing FFT cache to a bounded LRU cache
- #7688: DOC: fix broken genfromtxt examples in user guide. Closes gh-7662.
- #7689: BENCH: add correlate/convolve benchmarks.
- #7696: DOC: update wheel build / upload instructions
- #7699: BLD: preserve library order
- #7704: ENH: Add bits attribute to np.finfo
- #7712: BUG: Fix race condition with new FFT cache
- #7715: BUG: Remove memory leak in np.place
- #7719: BUG: Fix segfault in np.random.shuffle for arrays of different...
- #7723: Change mkl_info.dir_env_var from MKL to MKLROOT
- #7727: DOC: Corrections in Datetime Units-arrays.datetime.rst
- #7729: DOC: fix typo in savetxt docstring (closes #7620)
- #7733: Update 7525, DOC: Fix order=’A’ docs of np.array.
- #7734: Update 7542, ENH: Add polyrootval to numpy.polynomial
- #7735: BUG: fix issue on OS X with Python 3.x where npymath.ini was...
- #7739: DOC: Mention the changes of #6430 in the release notes.
- #7740: DOC: add reference to poisson rng
- #7743: Update 7476, DEP: deprecate Numeric-style typecodes, closes #2148
- #7744: DOC: Remove “ones_like” from ufuncs list (it is not)
- #7746: DOC: Clarify the effect of rcond in numpy.linalg.lstsq.
- #7747: Update 7672, BUG: Make sure we don’t divide by zero
- #7748: DOC: Update float32 mean example in docstring
- #7754: Update 7612, ENH: Add broadcast.ndim to match code elsewhere.
- #7757: Update 7175, BUG: Invalid read of size 4 in PyArray_FromFile
- #7759: BUG: Fix numpy.i support for numpy API < 1.7.
- #7760: ENH: Make assert_almost_equal & assert_array_almost_equal consistent.
- #7766: fix an English typo
- #7771: DOC: link geomspace from logspace
- #7773: DOC: Remove a redundant the
- #7777: DOC: Update Numpy 1.11.1 release notes.
- #7785: DOC: update wheel building procedure for release
- #7789: MRG: add note of 64-bit wheels on Windows
- #7791: f2py.compile issues (#7683)
- #7799: “lambda” is not allowed to use as keyword arguments in a sample...
- #7803: BUG: interpret ‘c’ PEP3118/struct type as ‘S1’.
- #7807: DOC: Misplaced parens in formula
- #7817: BUG: Make sure npy_mul_with_overflow_<type> detects overflow.
- #7818: numpy/distutils/misc_util.py fix for #7809: check that _tmpdirs...
- #7820: MAINT: Allocate fewer bytes for empty arrays.
- #7823: BUG: Fixed masked array behavior for scalar inputs to np.ma.atleast_*d
- #7834: DOC: Added an example
- #7839: Pypy fixes
- #7840: Fix ATLAS version detection
- #7842: Fix versionadded tags
- #7848: MAINT: Fix remaining uses of deprecated Python imp module.
- #7853: BUG: Make sure numpy globals keep identity after reload.
- #7863: ENH: turn quicksort into introsort
- #7866: Document runtests extra argv
- #7871: BUG: handle introsort depth limit properly
- #7879: DOC: fix typo in documentation of loadtxt (closes #7878)
- #7885: Handle NetBSD specific <sys/endian.h>
- #7889: DOC: #7881. Fix link to record arrays
- #7894: fixup-7790, BUG: construct ma.array from np.array which contains...
- #7898: Spelling and grammar fix.
- #7903: BUG: fix float16 type not being called due to wrong ordering
- #7908: BLD: Fixed detection for recent MKL versions
- #7911: BUG: fix for issue#7835 (ma.median of 1d)
- #7912: ENH: skip or avoid gc/objectmodel differences btwn pypy and cpython
- #7918: ENH: allow numpy.apply_along_axis() to work with ndarray subclasses
- #7922: ENH: Add ma.convolve and ma.correlate for #6458
- #7925: Monkey-patch _msvccompile.gen_lib_option like any other compilators
- #7931: BUG: Check for HAVE_LDOUBLE_DOUBLE_DOUBLE_LE in npy_math_complex.
- #7936: ENH: improve duck typing inside iscomplexobj
- #7937: BUG: Guard against buggy comparisons in generic quicksort.
- #7938: DOC: add cbrt to math summary page
- #7941: BUG: Make sure numpy globals keep identity after reload.
- #7943: DOC: #7927. Remove deprecated note for memmap relevant for Python...
- #7952: BUG: Use keyword arguments to initialize Extension base class.
- #7956: BLD: remove __NUMPY_SETUP__ from builtins at end of setup.py
- #7963: BUG: MSVCCompiler grows ‘lib’ & ‘include’ env strings exponentially.
- #7965: BUG: cannot modify tuple after use
- #7976: DOC: Fixed documented dimension of return value
- #7977: DOC: Create 1.11.2 release notes.
- #7979: DOC: Corrected allowed keywords in
add_installed_library - #7980: ENH: Add ability to runtime select ufunc loops, add AVX2 integer...
- #7985: Rebase 7763, ENH: Add new warning suppression/filtering context
- #7987: DOC: See also np.load and np.memmap in np.lib.format.open_memmap
- #7988: DOC: Include docstring for cbrt, spacing and fabs in documentation
- #7999: ENH: add inplace cases to fast ufunc loop macros
- #8006: DOC: Update 1.11.2 release notes.
- #8008: MAINT: Remove leftover imp module imports.
- #8009: DOC: Fixed three typos in the c-info.ufunc-tutorial
- #8011: DOC: Update 1.11.2 release notes.
- #8014: BUG: Fix fid.close() to use os.close(fid)
- #8016: BUG: Fix numpy.ma.median.
- #8018: BUG: Fixes return for np.ma.count if keepdims is True and axis...
- #8021: DOC: change all non-code instances of Numpy to NumPy
- #8027: ENH: Add platform indepedent lib dir to PYTHONPATH
- #8028: DOC: Update 1.11.2 release notes.
- #8030: BUG: fix np.ma.median with only one non-masked value and an axis...
- #8038: MAINT: Update error message in rollaxis.
- #8040: Update add_newdocs.py
- #8042: BUG: core: fix bug in NpyIter buffering with discontinuous arrays
- #8045: DOC: Update 1.11.2 release notes.
- #8050: remove refcount semantics, now a.resize() almost always requires...
- #8051: Clear signaling NaN exceptions
- #8054: ENH: add signature argument to vectorize for vectorizing like...
- #8057: BUG: lib: Simplify (and fix) pad’s handling of the pad_width
- #8061: BUG : financial.pmt modifies input (issue #8055)
- #8064: MAINT: Add PMIP files to .gitignore
- #8065: BUG: Assert fromfile ending earlier in pyx_processing
- #8066: BUG, TST: Fix python3-dbg bug in Travis script
- #8071: MAINT: Add Tempita to randint helpers
- #8075: DOC: Fix description of isinf in nan_to_num
- #8080: BUG: non-integers can end up in dtype offsets
- #8081: Update outdated Nose URL to nose.readthedocs.io
- #8083: ENH: Deprecation warnings for / integer division when running...
- #8084: DOC: Fix erroneous return type description for np.roots.
- #8087: BUG: financial.pmt modifies input #8055
- #8088: MAINT: Remove duplicate randint helpers code.
- #8093: MAINT: fix assert_raises_regex when used as a context manager
- #8096: ENH: Vendorize tempita.
- #8098: DOC: Enhance description/usage for np.linalg.eig*h
- #8103: Pypy fixes
- #8104: Fix test code on cpuinfo’s main function
- #8107: BUG: Fix array printing with precision=0.
- #8109: Fix bug in ravel_multi_index for big indices (Issue #7546)
- #8110: BUG: distutils: fix issue with rpath in fcompiler/gnu.py
- #8111: ENH: Add a tool for release authors and PRs.
- #8112: DOC: Fix “See also” links in linalg.
- #8114: BUG: core: add missing error check after PyLong_AsSsize_t
- #8121: DOC: Improve histogram2d() example.
- #8122: BUG: Fix broken pickle in MaskedArray when dtype is object (Return...
- #8124: BUG: Fixed build break
- #8125: Rebase, BUG: Fixed deepcopy of F-order object arrays.
- #8127: BUG: integers to a negative integer powers should error.
- #8141: improve configure checks for broken systems
- #8142: BUG: np.ma.mean and var should return scalar if no mask
- #8148: BUG: import full module path in npy_load_module
- #8153: MAINT: Expose void-scalar “base” attribute in python
- #8156: DOC: added example with empty indices for a scalar, #8138
- #8160: BUG: fix _array2string for structured array (issue #5692)
- #8164: MAINT: Update mailmap for NumPy 1.12.0
- #8165: Fixup 8152, BUG: assert_allclose(..., equal_nan=False) doesn’t...
- #8167: Fixup 8146, DOC: Clarify when PyArray_{Max, Min, Ptp} return...
- #8168: DOC: Minor spelling fix in genfromtxt() docstring.
- #8173: BLD: Enable build on AIX
- #8174: DOC: warn that dtype.descr is only for use in PEP3118
- #8177: MAINT: Add python 3.6 support to suppress_warnings
- #8178: MAINT: Fix ResourceWarning new in Python 3.6.
- #8180: FIX: protect stolen ref by PyArray_NewFromDescr in array_empty
- #8181: ENH: Improve announce to find github squash-merge commits.
- #8182: MAINT: Update .mailmap
- #8183: MAINT: Ediff1d performance
- #8184: MAINT: make assert_allclose behavior on nans match pre 1.12
- #8188: DOC: ‘highest’ is exclusive for randint()
- #8189: BUG: setfield should raise if arr is not writeable
- #8190: ENH: Add a float_power function with at least float64 precision.
- #8197: DOC: Add missing arguments to np.ufunc.outer
- #8198: DEP: Deprecate the keepdims argument to accumulate
- #8199: MAINT: change path to env in distutils.system_info. Closes gh-8195.
- #8200: BUG: Fix structured array format functions
- #8202: ENH: specialize name of dev package by interpreter
- #8205: DOC: change development instructions from SSH to HTTPS access.
- #8216: DOC: Patch doc errors for atleast_nd and frombuffer
- #8218: BUG: ediff1d should return subclasses
- #8219: DOC: Turn SciPy references into links.
- #8222: ENH: Make numpy.mean() do more precise computation
- #8227: BUG: Better check for invalid bounds in np.random.uniform.
- #8231: ENH: Refactor numpy ** operators for numpy scalar integer powers
- #8234: DOC: Clarified when a copy is made in numpy.asarray
- #8236: DOC: Fix documentation pull requests.
- #8238: MAINT: Update pavement.py
- #8239: ENH: Improve announce tool.
- #8240: REL: Prepare for 1.12.x branch
- #8243: BUG: Update operator ** tests for new behavior.
- #8246: REL: Reset strides for RELAXED_STRIDE_CHECKING for 1.12 releases.
- #8265: BUG: np.piecewise not working for scalars
- #8272: TST: Path test should resolve symlinks when comparing
- #8282: DOC: Update 1.12.0 release notes.
- #8286: BUG: Fix pavement.py write_release_task.
- #8296: BUG: Fix iteration over reversed subspaces in mapiter_@name@.
- #8304: BUG: Fix PyPy crash in PyUFunc_GenericReduction.
- #8319: BLD: blacklist powl (longdouble power function) on OS X.
- #8320: BUG: do not link to Accelerate if OpenBLAS, MKL or BLIS are found.
- #8322: BUG: fixed kind specifications for parameters
- #8336: BUG: fix packbits and unpackbits to correctly handle empty arrays
- #8338: BUG: fix test_api test that fails intermittently in python 3
- #8339: BUG: Fix ndarray.tofile large file corruption in append mode.
- #8359: BUG: Fix suppress_warnings (again) for Python 3.6.
- #8372: BUG: Fixes for ma.median and nanpercentile.
- #8373: BUG: correct letter case
- #8379: DOC: Update 1.12.0-notes.rst.
- #8390: ENH: retune apply_along_axis nanmedian cutoff in 1.12
- #8391: DEP: Fix escaped string characters deprecated in Python 3.6.
- #8394: DOC: create 1.11.3 release notes.
- #8399: BUG: Fix author search in announce.py
- #8402: DOC, MAINT: Update 1.12.0 notes and mailmap.
- #8418: BUG: Fix ma.median even elements for 1.12
- #8424: DOC: Fix tools and release notes to be more markdown compatible.
- #8427: BUG: Add a lock to assert_equal and other testing functions
- #8431: BUG: Fix apply_along_axis() for when func1d() returns a non-ndarray.
- #8432: BUG: Let linspace accept input that has an array_interface.
- #8437: TST: Update 3.6-dev tests to 3.6 after Python final release.
- #8439: DOC: Update 1.12.0 release notes.
- #8466: MAINT: Update mailmap entries.
- #8467: DOC: Back-port the missing part of gh-8464.
- #8476: DOC: Update 1.12.0 release notes.
- #8477: DOC: Update 1.12.0 release notes.
NumPy 1.11.3 Release Notes¶
Numpy 1.11.3 fixes a bug that leads to file corruption when very large files
opened in append mode are used in ndarray.tofile. It supports Python
versions 2.6 - 2.7 and 3.2 - 3.5. Wheels for Linux, Windows, and OS X can be
found on PyPI.
Contributors to maintenance/1.11.3¶
A total of 2 people contributed to this release. People with a “+” by their names contributed a patch for the first time.
- Charles Harris
- Pavel Potocek +
NumPy 1.11.2 Release Notes¶
Numpy 1.11.2 supports Python 2.6 - 2.7 and 3.2 - 3.5. It fixes bugs and regressions found in Numpy 1.11.1 and includes several build related improvements. Wheels for Linux, Windows, and OS X can be found on PyPI.
Pull Requests Merged¶
Fixes overridden by later merges and release notes updates are omitted.
- #7736 BUG: Many functions silently drop ‘keepdims’ kwarg.
- #7738 ENH: Add extra kwargs and update doc of many MA methods.
- #7778 DOC: Update Numpy 1.11.1 release notes.
- #7793 BUG: MaskedArray.count treats negative axes incorrectly.
- #7816 BUG: Fix array too big error for wide dtypes.
- #7821 BUG: Make sure npy_mul_with_overflow_<type> detects overflow.
- #7824 MAINT: Allocate fewer bytes for empty arrays.
- #7847 MAINT,DOC: Fix some imp module uses and update f2py.compile docstring.
- #7849 MAINT: Fix remaining uses of deprecated Python imp module.
- #7851 BLD: Fix ATLAS version detection.
- #7896 BUG: Construct ma.array from np.array which contains padding.
- #7904 BUG: Fix float16 type not being called due to wrong ordering.
- #7917 BUG: Production install of numpy should not require nose.
- #7919 BLD: Fixed MKL detection for recent versions of this library.
- #7920 BUG: Fix for issue #7835 (ma.median of 1d).
- #7932 BUG: Monkey-patch _msvccompile.gen_lib_option like other compilers.
- #7939 BUG: Check for HAVE_LDOUBLE_DOUBLE_DOUBLE_LE in npy_math_complex.
- #7953 BUG: Guard against buggy comparisons in generic quicksort.
- #7954 BUG: Use keyword arguments to initialize Extension base class.
- #7955 BUG: Make sure numpy globals keep identity after reload.
- #7972 BUG: MSVCCompiler grows ‘lib’ & ‘include’ env strings exponentially.
- #8005 BLD: Remove __NUMPY_SETUP__ from builtins at end of setup.py.
- #8010 MAINT: Remove leftover imp module imports.
- #8020 BUG: Fix return of np.ma.count if keepdims is True and axis is None.
- #8024 BUG: Fix numpy.ma.median.
- #8031 BUG: Fix np.ma.median with only one non-masked value.
- #8044 BUG: Fix bug in NpyIter buffering with discontinuous arrays.
NumPy 1.11.1 Release Notes¶
Numpy 1.11.1 supports Python 2.6 - 2.7 and 3.2 - 3.5. It fixes bugs and regressions found in Numpy 1.11.0 and includes several build related improvements. Wheels for Linux, Windows, and OSX can be found on pypi.
Fixes Merged¶
- #7506 BUG: Make sure numpy imports on python 2.6 when nose is unavailable.
- #7530 BUG: Floating exception with invalid axis in np.lexsort.
- #7535 BUG: Extend glibc complex trig functions blacklist to glibc < 2.18.
- #7551 BUG: Allow graceful recovery for no compiler.
- #7558 BUG: Constant padding expected wrong type in constant_values.
- #7578 BUG: Fix OverflowError in Python 3.x. in swig interface.
- #7590 BLD: Fix configparser.InterpolationSyntaxError.
- #7597 BUG: Make np.ma.take work on scalars.
- #7608 BUG: linalg.norm(): Don’t convert object arrays to float.
- #7638 BLD: Correct C compiler customization in system_info.py.
- #7654 BUG: ma.median of 1d array should return a scalar.
- #7656 BLD: Remove hardcoded Intel compiler flag -xSSE4.2.
- #7660 BUG: Temporary fix for str(mvoid) for object field types.
- #7665 BUG: Fix incorrect printing of 1D masked arrays.
- #7670 BUG: Correct initial index estimate in histogram.
- #7671 BUG: Boolean assignment no GIL release when transfer needs API.
- #7676 BUG: Fix handling of right edge of final histogram bin.
- #7680 BUG: Fix np.clip bug NaN handling for Visual Studio 2015.
- #7724 BUG: Fix segfaults in np.random.shuffle.
- #7731 MAINT: Change mkl_info.dir_env_var from MKL to MKLROOT.
- #7737 BUG: Fix issue on OS X with Python 3.x, npymath.ini not installed.
NumPy 1.11.0 Release Notes¶
This release supports Python 2.6 - 2.7 and 3.2 - 3.5 and contains a number of enhancements and improvements. Note also the build system changes listed below as they may have subtle effects.
No Windows (TM) binaries are provided for this release due to a broken toolchain. One of the providers of Python packages for Windows (TM) is your best bet.
Highlights¶
Details of these improvements can be found below.
- The datetime64 type is now timezone naive.
- A dtype parameter has been added to
randint. - Improved detection of two arrays possibly sharing memory.
- Automatic bin size estimation for
np.histogram. - Speed optimization of A @ A.T and dot(A, A.T).
- New function
np.moveaxisfor reordering array axes.
Build System Changes¶
- Numpy now uses
setuptoolsfor its builds instead of plain distutils. This fixes usage ofinstall_requires='numpy'in thesetup.pyfiles of projects that depend on Numpy (see gh-6551). It potentially affects the way that build/install methods for Numpy itself behave though. Please report any unexpected behavior on the Numpy issue tracker. - Bento build support and related files have been removed.
- Single file build support and related files have been removed.
Future Changes¶
The following changes are scheduled for Numpy 1.12.0.
- Support for Python 2.6, 3.2, and 3.3 will be dropped.
- Relaxed stride checking will become the default. See the 1.8.0 release notes for a more extended discussion of what this change implies.
- The behavior of the datetime64 “not a time” (NaT) value will be changed to match that of floating point “not a number” (NaN) values: all comparisons involving NaT will return False, except for NaT != NaT which will return True.
- Indexing with floats will raise IndexError, e.g., a[0, 0.0].
- Indexing with non-integer array_like will raise
IndexError, e.g.,a['1', '2'] - Indexing with multiple ellipsis will raise
IndexError, e.g.,a[..., ...]. - Non-integers used as index values will raise
TypeError, e.g., inreshape,take, and specifying reduce axis.
In a future release the following changes will be made.
- The
randfunction exposed innumpy.testingwill be removed. That function is left over from early Numpy and was implemented using the Python random module. The random number generators fromnumpy.randomshould be used instead. - The
ndarray.viewmethod will only allow c_contiguous arrays to be viewed using a dtype of different size causing the last dimension to change. That differs from the current behavior where arrays that are f_contiguous but not c_contiguous can be viewed as a dtype type of different size causing the first dimension to change. - Slicing a
MaskedArraywill return views of both data and mask. Currently the mask is copy-on-write and changes to the mask in the slice do not propagate to the original mask. See the FutureWarnings section below for details.
Compatibility notes¶
datetime64 changes¶
In prior versions of NumPy the experimental datetime64 type always stored times in UTC. By default, creating a datetime64 object from a string or printing it would convert from or to local time:
# old behavior
>>>> np.datetime64('2000-01-01T00:00:00')
numpy.datetime64('2000-01-01T00:00:00-0800') # note the timezone offset -08:00
A consensus of datetime64 users agreed that this behavior is undesirable
and at odds with how datetime64 is usually used (e.g., by pandas). For most use cases, a timezone naive datetime
type is preferred, similar to the datetime.datetime type in the Python
standard library. Accordingly, datetime64 no longer assumes that input is in
local time, nor does it print local times:
>>>> np.datetime64('2000-01-01T00:00:00')
numpy.datetime64('2000-01-01T00:00:00')
For backwards compatibility, datetime64 still parses timezone offsets, which it handles by converting to UTC. However, the resulting datetime is timezone naive:
>>> np.datetime64('2000-01-01T00:00:00-08')
DeprecationWarning: parsing timezone aware datetimes is deprecated;
this will raise an error in the future
numpy.datetime64('2000-01-01T08:00:00')
As a corollary to this change, we no longer prohibit casting between datetimes with date units and datetimes with time units. With timezone naive datetimes, the rule for casting from dates to times is no longer ambiguous.
linalg.norm return type changes¶
The return type of the linalg.norm function is now floating point without
exception. Some of the norm types previously returned integers.
polynomial fit changes¶
The various fit functions in the numpy polynomial package no longer accept non-integers for degree specification.
np.dot now raises TypeError instead of ValueError¶
This behaviour mimics that of other functions such as np.inner. If the two
arguments cannot be cast to a common type, it could have raised a TypeError
or ValueError depending on their order. Now, np.dot will now always
raise a TypeError.
FutureWarning to changed behavior¶
- In
np.lib.splitan empty array in the result always had dimension(0,)no matter the dimensions of the array being split. This has been changed so that the dimensions will be preserved. AFutureWarningfor this change has been in place since Numpy 1.9 but, due to a bug, sometimes no warning was raised and the dimensions were already preserved.
% and // operators¶
These operators are implemented with the remainder and floor_divide
functions respectively. Those functions are now based around fmod and are
computed together so as to be compatible with each other and with the Python
versions for float types. The results should be marginally more accurate or
outright bug fixes compared to the previous results, but they may
differ significantly in cases where roundoff makes a difference in the integer
returned by floor_divide. Some corner cases also change, for instance, NaN
is always returned for both functions when the divisor is zero,
divmod(1.0, inf) returns (0.0, 1.0) except on MSVC 2008, and
divmod(-1.0, inf) returns (-1.0, inf).
C API¶
Removed the check_return and inner_loop_selector members of
the PyUFuncObject struct (replacing them with reserved slots
to preserve struct layout). These were never used for anything, so
it’s unlikely that any third-party code is using them either, but we
mention it here for completeness.
object dtype detection for old-style classes¶
In python 2, objects which are instances of old-style user-defined classes no longer automatically count as ‘object’ type in the dtype-detection handler. Instead, as in python 3, they may potentially count as sequences, but only if they define both a __len__ and a __getitem__ method. This fixes a segfault and inconsistency between python 2 and 3.
New Features¶
np.histogramnow provides plugin estimators for automatically estimating the optimal number of bins. Passing one of [‘auto’, ‘fd’, ‘scott’, ‘rice’, ‘sturges’] as the argument to ‘bins’ results in the corresponding estimator being used.A benchmark suite using Airspeed Velocity has been added, converting the previous vbench-based one. You can run the suite locally via
python runtests.py --bench. For more details, seebenchmarks/README.rst.A new function
np.shares_memorythat can check exactly whether two arrays have memory overlap is added.np.may_share_memoryalso now has an option to spend more effort to reduce false positives.SkipTestandKnownFailureExceptionexception classes are exposed in thenumpy.testingnamespace. Raise them in a test function to mark the test to be skipped or mark it as a known failure, respectively.f2py.compilehas a newextensionkeyword parameter that allows the fortran extension to be specified for generated temp files. For instance, the files can be specifies to be*.f90. Theverboseargument is also activated, it was previously ignored.A
dtypeparameter has been added tonp.random.randintRandom ndarrays of the following types can now be generated:np.bool,np.int8,np.uint8,np.int16,np.uint16,np.int32,np.uint32,np.int64,np.uint64,np.int_ ``, ``np.intp
The specification is by precision rather than by C type. Hence, on some platforms
np.int64may be alonginstead oflong longeven if the specified dtype islong longbecause the two may have the same precision. The resulting type depends on which C type numpy uses for the given precision. The byteorder specification is also ignored, the generated arrays are always in native byte order.A new
np.moveaxisfunction allows for moving one or more array axes to a new position by explicitly providing source and destination axes. This function should be easier to use than the currentrollaxisfunction as well as providing more functionality.The
degparameter of the variousnumpy.polynomialfits has been extended to accept a list of the degrees of the terms to be included in the fit, the coefficients of all other terms being constrained to zero. The change is backward compatible, passing a scalardegwill behave as before.A divmod function for float types modeled after the Python version has been added to the npy_math library.
Improvements¶
np.gradient now supports an axis argument¶
The axis parameter was added to np.gradient for consistency. It
allows to specify over which axes the gradient is calculated.
np.lexsort now supports arrays with object data-type¶
The function now internally calls the generic npy_amergesort when the
type does not implement a merge-sort kind of argsort method.
np.ma.core.MaskedArray now supports an order argument¶
When constructing a new MaskedArray instance, it can be configured with
an order argument analogous to the one when calling np.ndarray. The
addition of this argument allows for the proper processing of an order
argument in several MaskedArray-related utility functions such as
np.ma.core.array and np.ma.core.asarray.
Memory and speed improvements for masked arrays¶
Creating a masked array with mask=True (resp. mask=False) now uses
np.ones (resp. np.zeros) to create the mask, which is faster and
avoid a big memory peak. Another optimization was done to avoid a memory
peak and useless computations when printing a masked array.
ndarray.tofile now uses fallocate on linux¶
The function now uses the fallocate system call to reserve sufficient disk space on file systems that support it.
Optimizations for operations of the form A.T @ A and A @ A.T¶
Previously, gemm BLAS operations were used for all matrix products. Now,
if the matrix product is between a matrix and its transpose, it will use
syrk BLAS operations for a performance boost. This optimization has been
extended to @, numpy.dot, numpy.inner, and numpy.matmul.
Note: Requires the transposed and non-transposed matrices to share data.
np.testing.assert_warns can now be used as a context manager¶
This matches the behavior of assert_raises.
Speed improvement for np.random.shuffle¶
np.random.shuffle is now much faster for 1d ndarrays.
Changes¶
Pyrex support was removed from numpy.distutils¶
The method build_src.generate_a_pyrex_source will remain available; it
has been monkeypatched by users to support Cython instead of Pyrex. It’s
recommended to switch to a better supported method of build Cython
extensions though.
np.broadcast can now be called with a single argument¶
The resulting object in that case will simply mimic iteration over a single array. This change obsoletes distinctions like
- if len(x) == 1:
- shape = x[0].shape
- else:
- shape = np.broadcast(*x).shape
Instead, np.broadcast can be used in all cases.
np.trace now respects array subclasses¶
This behaviour mimics that of other functions such as np.diagonal and
ensures, e.g., that for masked arrays np.trace(ma) and ma.trace() give
the same result.
np.dot now raises TypeError instead of ValueError¶
This behaviour mimics that of other functions such as np.inner. If the two
arguments cannot be cast to a common type, it could have raised a TypeError
or ValueError depending on their order. Now, np.dot will now always
raise a TypeError.
linalg.norm return type changes¶
The linalg.norm function now does all its computations in floating point
and returns floating results. This change fixes bugs due to integer overflow
and the failure of abs with signed integers of minimum value, e.g., int8(-128).
For consistancy, floats are used even where an integer might work.
Deprecations¶
Views of arrays in Fortran order¶
The F_CONTIGUOUS flag was used to signal that views using a dtype that
changed the element size would change the first index. This was always
problematical for arrays that were both F_CONTIGUOUS and C_CONTIGUOUS
because C_CONTIGUOUS took precedence. Relaxed stride checking results in
more such dual contiguous arrays and breaks some existing code as a result.
Note that this also affects changing the dtype by assigning to the dtype
attribute of an array. The aim of this deprecation is to restrict views to
C_CONTIGUOUS arrays at some future time. A work around that is backward
compatible is to use a.T.view(...).T instead. A parameter may also be
added to the view method to explicitly ask for Fortran order views, but
that will not be backward compatible.
Invalid arguments for array ordering¶
It is currently possible to pass in arguments for the order
parameter in methods like array.flatten or array.ravel
that were not one of the following: ‘C’, ‘F’, ‘A’, ‘K’ (note that
all of these possible values are both unicode and case insensitive).
Such behavior will not be allowed in future releases.
Random number generator in the testing namespace¶
The Python standard library random number generator was previously exposed
in the testing namespace as testing.rand. Using this generator is
not recommended and it will be removed in a future release. Use generators
from numpy.random namespace instead.
Random integer generation on a closed interval¶
In accordance with the Python C API, which gives preference to the half-open
interval over the closed one, np.random.random_integers is being
deprecated in favor of calling np.random.randint, which has been
enhanced with the dtype parameter as described under “New Features”.
However, np.random.random_integers will not be removed anytime soon.
FutureWarnings¶
Assigning to slices/views of MaskedArray¶
Currently a slice of a masked array contains a view of the original data and a
copy-on-write view of the mask. Consequently, any changes to the slice’s mask
will result in a copy of the original mask being made and that new mask being
changed rather than the original. For example, if we make a slice of the
original like so, view = original[:], then modifications to the data in one
array will affect the data of the other but, because the mask will be copied
during assignment operations, changes to the mask will remain local. A similar
situation occurs when explicitly constructing a masked array using
MaskedArray(data, mask), the returned array will contain a view of data
but the mask will be a copy-on-write view of mask.
In the future, these cases will be normalized so that the data and mask arrays
are treated the same way and modifications to either will propagate between
views. In 1.11, numpy will issue a MaskedArrayFutureWarning warning
whenever user code modifies the mask of a view that in the future may cause
values to propagate back to the original. To silence these warnings and make
your code robust against the upcoming changes, you have two options: if you
want to keep the current behavior, call masked_view.unshare_mask() before
modifying the mask. If you want to get the future behavior early, use
masked_view._sharedmask = False. However, note that setting the
_sharedmask attribute will break following explicit calls to
masked_view.unshare_mask().
NumPy 1.10.4 Release Notes¶
This release is a bugfix source release motivated by a segfault regression. No windows binaries are provided for this release, as there appear to be bugs in the toolchain we use to generate those files. Hopefully that problem will be fixed for the next release. In the meantime, we suggest using one of the providers of windows binaries.
Compatibility notes¶
- The trace function now calls the trace method on subclasses of ndarray, except for matrix, for which the current behavior is preserved. This is to help with the units package of AstroPy and hopefully will not cause problems.
Issues Fixed¶
- gh-6922 BUG: numpy.recarray.sort segfaults on Windows.
- gh-6937 BUG: busday_offset does the wrong thing with modifiedpreceding roll.
- gh-6949 BUG: Type is lost when slicing a subclass of recarray.
Merged PRs¶
The following PRs have been merged into 1.10.4. When the PR is a backport, the PR number for the original PR against master is listed.
- gh-6840 TST: Update travis testing script in 1.10.x
- gh-6843 BUG: Fix use of python 3 only FileNotFoundError in test_f2py.
- gh-6884 REL: Update pavement.py and setup.py to reflect current version.
- gh-6916 BUG: Fix test_f2py so it runs correctly in runtests.py.
- gh-6924 BUG: Fix segfault gh-6922.
- gh-6942 Fix datetime roll=’modifiedpreceding’ bug.
- gh-6943 DOC,BUG: Fix some latex generation problems.
- gh-6950 BUG trace is not subclass aware, np.trace(ma) != ma.trace().
- gh-6952 BUG recarray slices should preserve subclass.
NumPy 1.10.3 Release Notes¶
N/A this release did not happen due to various screwups involving PyPi.
NumPy 1.10.2 Release Notes¶
This release deals with a number of bugs that turned up in 1.10.1 and adds various build and release improvements.
Numpy 1.10.1 supports Python 2.6 - 2.7 and 3.2 - 3.5.
Compatibility notes¶
Relaxed stride checking is no longer the default¶
There were back compatibility problems involving views changing the dtype of multidimensional Fortran arrays that need to be dealt with over a longer timeframe.
Fix swig bug in numpy.i¶
Relaxed stride checking revealed a bug in array_is_fortran(a), that was
using PyArray_ISFORTRAN to check for Fortran contiguity instead of
PyArray_IS_F_CONTIGUOUS. You may want to regenerate swigged files using the
updated numpy.i
Deprecate views changing dimensions in fortran order¶
This deprecates assignment of a new descriptor to the dtype attribute of a non-C-contiguous array if it result in changing the shape. This effectively bars viewing a multidimensional Fortran array using a dtype that changes the element size along the first axis.
The reason for the deprecation is that, when relaxed strides checking is enabled, arrays that are both C and Fortran contiguous are always treated as C contiguous which breaks some code that depended the two being mutually exclusive for non-scalar arrays of ndim > 1. This deprecation prepares the way to always enable relaxed stride checking.
Issues Fixed¶
- gh-6019 Masked array repr fails for structured array with multi-dimensional column.
- gh-6462 Median of empty array produces IndexError.
- gh-6467 Performance regression for record array access.
- gh-6468 numpy.interp uses ‘left’ value even when x[0]==xp[0].
- gh-6475 np.allclose returns a memmap when one of its arguments is a memmap.
- gh-6491 Error in broadcasting stride_tricks array.
- gh-6495 Unrecognized command line option ‘-ffpe-summary’ in gfortran.
- gh-6497 Failure of reduce operation on recarrays.
- gh-6498 Mention change in default casting rule in 1.10 release notes.
- gh-6530 The partition function errors out on empty input.
- gh-6532 numpy.inner return wrong inaccurate value sometimes.
- gh-6563 Intent(out) broken in recent versions of f2py.
- gh-6569 Cannot run tests after ‘python setup.py build_ext -i’
- gh-6572 Error in broadcasting stride_tricks array component.
- gh-6575 BUG: Split produces empty arrays with wrong number of dimensions
- gh-6590 Fortran Array problem in numpy 1.10.
- gh-6602 Random __all__ missing choice and dirichlet.
- gh-6611 ma.dot no longer always returns a masked array in 1.10.
- gh-6618 NPY_FORTRANORDER in make_fortran() in numpy.i
- gh-6636 Memory leak in nested dtypes in numpy.recarray
- gh-6641 Subsetting recarray by fields yields a structured array.
- gh-6667 ma.make_mask handles ma.nomask input incorrectly.
- gh-6675 Optimized blas detection broken in master and 1.10.
- gh-6678 Getting unexpected error from: X.dtype = complex (or Y = X.view(complex))
- gh-6718 f2py test fail in pip installed numpy-1.10.1 in virtualenv.
- gh-6719 Error compiling Cython file: Pythonic division not allowed without gil.
- gh-6771 Numpy.rec.fromarrays losing dtype metadata between versions 1.9.2 and 1.10.1
- gh-6781 The travis-ci script in maintenance/1.10.x needs fixing.
- gh-6807 Windows testing errors for 1.10.2
Merged PRs¶
The following PRs have been merged into 1.10.2. When the PR is a backport, the PR number for the original PR against master is listed.
- gh-5773 MAINT: Hide testing helper tracebacks when using them with pytest.
- gh-6094 BUG: Fixed a bug with string representation of masked structured arrays.
- gh-6208 MAINT: Speedup field access by removing unneeded safety checks.
- gh-6460 BUG: Replacing the os.environ.clear by less invasive procedure.
- gh-6470 BUG: Fix AttributeError in numpy distutils.
- gh-6472 MAINT: Use Python 3.5 instead of 3.5-dev for travis 3.5 testing.
- gh-6474 REL: Update Paver script for sdist and auto-switch test warnings.
- gh-6478 BUG: Fix Intel compiler flags for OS X build.
- gh-6481 MAINT: LIBPATH with spaces is now supported Python 2.7+ and Win32.
- gh-6487 BUG: Allow nested use of parameters in definition of arrays in f2py.
- gh-6488 BUG: Extend common blocks rather than overwriting in f2py.
- gh-6499 DOC: Mention that default casting for inplace operations has changed.
- gh-6500 BUG: Recarrays viewed as subarrays don’t convert to np.record type.
- gh-6501 REL: Add “make upload” command for built docs, update “make dist”.
- gh-6526 BUG: Fix use of __doc__ in setup.py for -OO mode.
- gh-6527 BUG: Fix the IndexError when taking the median of an empty array.
- gh-6537 BUG: Make ma.atleast_* with scalar argument return arrays.
- gh-6538 BUG: Fix ma.masked_values does not shrink mask if requested.
- gh-6546 BUG: Fix inner product regression for non-contiguous arrays.
- gh-6553 BUG: Fix partition and argpartition error for empty input.
- gh-6556 BUG: Error in broadcast_arrays with as_strided array.
- gh-6558 MAINT: Minor update to “make upload” doc build command.
- gh-6562 BUG: Disable view safety checks in recarray.
- gh-6567 BUG: Revert some import * fixes in f2py.
- gh-6574 DOC: Release notes for Numpy 1.10.2.
- gh-6577 BUG: Fix for #6569, allowing build_ext –inplace
- gh-6579 MAINT: Fix mistake in doc upload rule.
- gh-6596 BUG: Fix swig for relaxed stride checking.
- gh-6606 DOC: Update 1.10.2 release notes.
- gh-6614 BUG: Add choice and dirichlet to numpy.random.__all__.
- gh-6621 BUG: Fix swig make_fortran function.
- gh-6628 BUG: Make allclose return python bool.
- gh-6642 BUG: Fix memleak in _convert_from_dict.
- gh-6643 ENH: make recarray.getitem return a recarray.
- gh-6653 BUG: Fix ma dot to always return masked array.
- gh-6668 BUG: ma.make_mask should always return nomask for nomask argument.
- gh-6686 BUG: Fix a bug in assert_string_equal.
- gh-6695 BUG: Fix removing tempdirs created during build.
- gh-6697 MAINT: Fix spurious semicolon in macro definition of PyArray_FROM_OT.
- gh-6698 TST: test np.rint bug for large integers.
- gh-6717 BUG: Readd fallback CBLAS detection on linux.
- gh-6721 BUG: Fix for #6719.
- gh-6726 BUG: Fix bugs exposed by relaxed stride rollback.
- gh-6757 BUG: link cblas library if cblas is detected.
- gh-6756 TST: only test f2py, not f2py2.7 etc, fixes #6718.
- gh-6747 DEP: Deprecate changing shape of non-C-contiguous array via descr.
- gh-6775 MAINT: Include from __future__ boilerplate in some files missing it.
- gh-6780 BUG: metadata is not copied to base_dtype.
- gh-6783 BUG: Fix travis ci testing for new google infrastructure.
- gh-6785 BUG: Quick and dirty fix for interp.
- gh-6813 TST,BUG: Make test_mvoid_multidim_print work for 32 bit systems.
- gh-6817 BUG: Disable 32-bit msvc9 compiler optimizations for npy_rint.
- gh-6819 TST: Fix test_mvoid_multidim_print failures on Python 2.x for Windows.
Initial support for mingwpy was reverted as it was causing problems for non-windows builds.
- gh-6536 BUG: Revert gh-5614 to fix non-windows build problems
A fix for np.lib.split was reverted because it resulted in “fixing” behavior that will be present in the Numpy 1.11 and that was already present in Numpy 1.9. See the discussion of the issue at gh-6575 for clarification.
- gh-6576 BUG: Revert gh-6376 to fix split behavior for empty arrays.
Relaxed stride checking was reverted. There were back compatibility problems involving views changing the dtype of multidimensional Fortran arrays that need to be dealt with over a longer timeframe.
- gh-6735 MAINT: Make no relaxed stride checking the default for 1.10.
Notes¶
A bug in the Numpy 1.10.1 release resulted in exceptions being raised for
RuntimeWarning and DeprecationWarning in projects depending on Numpy.
That has been fixed.
NumPy 1.10.1 Release Notes¶
This release deals with a few build problems that showed up in 1.10.0. Most users would not have seen these problems. The differences are:
- Compiling with msvc9 or msvc10 for 32 bit Windows now requires SSE2. This was the easiest fix for what looked to be some miscompiled code when SSE2 was not used. If you need to compile for 32 bit Windows systems without SSE2 support, mingw32 should still work.
- Make compiling with VS2008 python2.7 SDK easier
- Change Intel compiler options so that code will also be generated to support systems without SSE4.2.
- Some _config test functions needed an explicit integer return in order to avoid the openSUSE rpmlinter erring out.
- We ran into a problem with pipy not allowing reuse of filenames and a resulting proliferation of ..*.postN releases. Not only were the names getting out of hand, some packages were unable to work with the postN suffix.
Numpy 1.10.1 supports Python 2.6 - 2.7 and 3.2 - 3.5.
Commits:
45a3d84 DEP: Remove warning for full when dtype is set. 0c1a5df BLD: import setuptools to allow compile with VS2008 python2.7 sdk 04211c6 BUG: mask nan to 1 in ordered compare 826716f DOC: Document the reason msvc requires SSE2 on 32 bit platforms. 49fa187 BLD: enable SSE2 for 32-bit msvc 9 and 10 compilers dcbc4cc MAINT: remove Wreturn-type warnings from config checks d6564cb BLD: do not build exclusively for SSE4.2 processors 15cb66f BLD: do not build exclusively for SSE4.2 processors c38bc08 DOC: fix var. reference in percentile docstring 78497f4 DOC: Sync 1.10.0-notes.rst in 1.10.x branch with master.
NumPy 1.10.0 Release Notes¶
This release supports Python 2.6 - 2.7 and 3.2 - 3.5.
Highlights¶
- numpy.distutils now supports parallel compilation via the –parallel/-j argument passed to setup.py build
- numpy.distutils now supports additional customization via site.cfg to control compilation parameters, i.e. runtime libraries, extra linking/compilation flags.
- Addition of np.linalg.multi_dot: compute the dot product of two or more arrays in a single function call, while automatically selecting the fastest evaluation order.
- The new function np.stack provides a general interface for joining a sequence of arrays along a new axis, complementing np.concatenate for joining along an existing axis.
- Addition of nanprod to the set of nanfunctions.
- Support for the ‘@’ operator in Python 3.5.
Dropped Support¶
- The _dotblas module has been removed. CBLAS Support is now in Multiarray.
- The testcalcs.py file has been removed.
- The polytemplate.py file has been removed.
- npy_PyFile_Dup and npy_PyFile_DupClose have been removed from npy_3kcompat.h.
- splitcmdline has been removed from numpy/distutils/exec_command.py.
- try_run and get_output have been removed from numpy/distutils/command/config.py
- The a._format attribute is no longer supported for array printing.
- Keywords
skiprowsandmissingremoved from np.genfromtxt. - Keyword
old_behaviorremoved from np.correlate.
Future Changes¶
- In array comparisons like
arr1 == arr2, many corner cases involving strings or structured dtypes that used to return scalars now issueFutureWarningorDeprecationWarning, and in the future will be change to either perform elementwise comparisons or raise an error. - In
np.lib.splitan empty array in the result always had dimension(0,)no matter the dimensions of the array being split. In Numpy 1.11 that behavior will be changed so that the dimensions will be preserved. AFutureWarningfor this change has been in place since Numpy 1.9 but, due to a bug, sometimes no warning was raised and the dimensions were already preserved. - The SafeEval class will be removed in Numpy 1.11.
- The alterdot and restoredot functions will be removed in Numpy 1.11.
See below for more details on these changes.
Compatibility notes¶
Default casting rule change¶
Default casting for inplace operations has changed to 'same_kind'. For
instance, if n is an array of integers, and f is an array of floats, then
n += f will result in a TypeError, whereas in previous Numpy
versions the floats would be silently cast to ints. In the unlikely case
that the example code is not an actual bug, it can be updated in a backward
compatible way by rewriting it as np.add(n, f, out=n, casting='unsafe').
The old 'unsafe' default has been deprecated since Numpy 1.7.
numpy version string¶
The numpy version string for development builds has been changed from
x.y.z.dev-githash to x.y.z.dev0+githash (note the +) in order to comply
with PEP 440.
relaxed stride checking¶
NPY_RELAXED_STRIDE_CHECKING is now true by default.
UPDATE: In 1.10.2 the default value of NPY_RELAXED_STRIDE_CHECKING was changed to false for back compatibility reasons. More time is needed before it can be made the default. As part of the roadmap a deprecation of dimension changing views of f_contiguous not c_contiguous arrays was also added.
Concatenation of 1d arrays along any but axis=0 raises IndexError¶
Using axis != 0 has raised a DeprecationWarning since NumPy 1.7, it now raises an error.
np.ravel, np.diagonal and np.diag now preserve subtypes¶
There was inconsistent behavior between x.ravel() and np.ravel(x), as well as between x.diagonal() and np.diagonal(x), with the methods preserving subtypes while the functions did not. This has been fixed and the functions now behave like the methods, preserving subtypes except in the case of matrices. Matrices are special cased for backward compatibility and still return 1-D arrays as before. If you need to preserve the matrix subtype, use the methods instead of the functions.
rollaxis and swapaxes always return a view¶
Previously, a view was returned except when no change was made in the order of the axes, in which case the input array was returned. A view is now returned in all cases.
nonzero now returns base ndarrays¶
Previously, an inconsistency existed between 1-D inputs (returning a base ndarray) and higher dimensional ones (which preserved subclasses). Behavior has been unified, and the return will now be a base ndarray. Subclasses can still override this behavior by providing their own nonzero method.
C API¶
The changes to swapaxes also apply to the PyArray_SwapAxes C function, which now returns a view in all cases.
The changes to nonzero also apply to the PyArray_Nonzero C function, which now returns a base ndarray in all cases.
The dtype structure (PyArray_Descr) has a new member at the end to cache its hash value. This shouldn’t affect any well-written applications.
The change to the concatenation function DeprecationWarning also affects PyArray_ConcatenateArrays,
recarray field return types¶
Previously the returned types for recarray fields accessed by attribute and by index were inconsistent, and fields of string type were returned as chararrays. Now, fields accessed by either attribute or indexing will return an ndarray for fields of non-structured type, and a recarray for fields of structured type. Notably, this affect recarrays containing strings with whitespace, as trailing whitespace is trimmed from chararrays but kept in ndarrays of string type. Also, the dtype.type of nested structured fields is now inherited.
recarray views¶
Viewing an ndarray as a recarray now automatically converts the dtype to np.record. See new record array documentation. Additionally, viewing a recarray with a non-structured dtype no longer converts the result’s type to ndarray - the result will remain a recarray.
‘out’ keyword argument of ufuncs now accepts tuples of arrays¶
When using the ‘out’ keyword argument of a ufunc, a tuple of arrays, one per ufunc output, can be provided. For ufuncs with a single output a single array is also a valid ‘out’ keyword argument. Previously a single array could be provided in the ‘out’ keyword argument, and it would be used as the first output for ufuncs with multiple outputs, is deprecated, and will result in a DeprecationWarning now and an error in the future.
byte-array indices now raises an IndexError¶
Indexing an ndarray using a byte-string in Python 3 now raises an IndexError instead of a ValueError.
Masked arrays containing objects with arrays¶
For such (rare) masked arrays, getting a single masked item no longer returns a corrupted masked array, but a fully masked version of the item.
Median warns and returns nan when invalid values are encountered¶
Similar to mean, median and percentile now emits a Runtime warning and returns NaN in slices where a NaN is present. To compute the median or percentile while ignoring invalid values use the new nanmedian or nanpercentile functions.
Functions available from numpy.ma.testutils have changed¶
All functions from numpy.testing were once available from numpy.ma.testutils but not all of them were redefined to work with masked arrays. Most of those functions have now been removed from numpy.ma.testutils with a small subset retained in order to preserve backward compatibility. In the long run this should help avoid mistaken use of the wrong functions, but it may cause import problems for some.
New Features¶
Reading extra flags from site.cfg¶
Previously customization of compilation of dependency libraries and numpy itself was only accomblishable via code changes in the distutils package. Now numpy.distutils reads in the following extra flags from each group of the site.cfg:
runtime_library_dirs/rpath, sets runtime library directories to overrideLD_LIBRARY_PATH
extra_compile_args, add extra flags to the compilation of sourcesextra_link_args, add extra flags when linking libraries
This should, at least partially, complete user customization.
np.cbrt to compute cube root for real floats¶
np.cbrt wraps the C99 cube root function cbrt. Compared to np.power(x, 1./3.) it is well defined for negative real floats and a bit faster.
numpy.distutils now allows parallel compilation¶
By passing –parallel=n or -j n to setup.py build the compilation of extensions is now performed in n parallel processes. The parallelization is limited to files within one extension so projects using Cython will not profit because it builds extensions from single files.
genfromtxt has a new max_rows argument¶
A max_rows argument has been added to genfromtxt to limit the
number of rows read in a single call. Using this functionality, it is
possible to read in multiple arrays stored in a single file by making
repeated calls to the function.
New function np.broadcast_to for invoking array broadcasting¶
np.broadcast_to manually broadcasts an array to a given shape according to numpy’s broadcasting rules. The functionality is similar to broadcast_arrays, which in fact has been rewritten to use broadcast_to internally, but only a single array is necessary.
New context manager clear_and_catch_warnings for testing warnings¶
When Python emits a warning, it records that this warning has been emitted in
the module that caused the warning, in a module attribute
__warningregistry__. Once this has happened, it is not possible to emit
the warning again, unless you clear the relevant entry in
__warningregistry__. This makes is hard and fragile to test warnings,
because if your test comes after another that has already caused the warning,
you will not be able to emit the warning or test it. The context manager
clear_and_catch_warnings clears warnings from the module registry on entry
and resets them on exit, meaning that warnings can be re-raised.
cov has new fweights and aweights arguments¶
The fweights and aweights arguments add new functionality to
covariance calculations by applying two types of weighting to observation
vectors. An array of fweights indicates the number of repeats of each
observation vector, and an array of aweights provides their relative
importance or probability.
Support for the ‘@’ operator in Python 3.5+¶
Python 3.5 adds support for a matrix multiplication operator ‘@’ proposed
in PEP465. Preliminary support for that has been implemented, and an
equivalent function matmul has also been added for testing purposes and
use in earlier Python versions. The function is preliminary and the order
and number of its optional arguments can be expected to change.
New argument norm to fft functions¶
The default normalization has the direct transforms unscaled and the inverse
transforms are scaled by 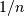 . It is possible to obtain unitary
transforms by setting the keyword argument
. It is possible to obtain unitary
transforms by setting the keyword argument norm to "ortho" (default is
None) so that both direct and inverse transforms will be scaled by
 .
.
Improvements¶
np.digitize using binary search¶
np.digitize is now implemented in terms of np.searchsorted. This means that a binary search is used to bin the values, which scales much better for larger number of bins than the previous linear search. It also removes the requirement for the input array to be 1-dimensional.
np.poly now casts integer inputs to float¶
np.poly will now cast 1-dimensional input arrays of integer type to double precision floating point, to prevent integer overflow when computing the monic polynomial. It is still possible to obtain higher precision results by passing in an array of object type, filled e.g. with Python ints.
np.interp can now be used with periodic functions¶
np.interp now has a new parameter period that supplies the period of the input data xp. In such case, the input data is properly normalized to the given period and one end point is added to each extremity of xp in order to close the previous and the next period cycles, resulting in the correct interpolation behavior.
np.pad supports more input types for pad_width and constant_values¶
constant_values parameters now accepts NumPy arrays and float values.
NumPy arrays are supported as input for pad_width, and an exception is
raised if its values are not of integral type.
np.argmax and np.argmin now support an out argument¶
The out parameter was added to np.argmax and np.argmin for consistency
with ndarray.argmax and ndarray.argmin. The new parameter behaves exactly
as it does in those methods.
More system C99 complex functions detected and used¶
All of the functions in complex.h are now detected. There are new
fallback implementations of the following functions.
- npy_ctan,
- npy_cacos, npy_casin, npy_catan
- npy_ccosh, npy_csinh, npy_ctanh,
- npy_cacosh, npy_casinh, npy_catanh
As a result of these improvements, there will be some small changes in returned values, especially for corner cases.
np.loadtxt support for the strings produced by the float.hex method¶
The strings produced by float.hex look like 0x1.921fb54442d18p+1,
so this is not the hex used to represent unsigned integer types.
np.isclose properly handles minimal values of integer dtypes¶
In order to properly handle minimal values of integer types, np.isclose will now cast to the float dtype during comparisons. This aligns its behavior with what was provided by np.allclose.
np.allclose uses np.isclose internally.¶
np.allclose now uses np.isclose internally and inherits the ability to
compare NaNs as equal by setting equal_nan=True. Subclasses, such as
np.ma.MaskedArray, are also preserved now.
np.genfromtxt now handles large integers correctly¶
np.genfromtxt now correctly handles integers larger than 2**31-1 on
32-bit systems and larger than 2**63-1 on 64-bit systems (it previously
crashed with an OverflowError in these cases). Integers larger than
2**63-1 are converted to floating-point values.
np.load, np.save have pickle backward compatibility flags¶
The functions np.load and np.save have additional keyword arguments for controlling backward compatibility of pickled Python objects. This enables Numpy on Python 3 to load npy files containing object arrays that were generated on Python 2.
MaskedArray support for more complicated base classes¶
Built-in assumptions that the baseclass behaved like a plain array are being
removed. In particular, setting and getting elements and ranges will respect
baseclass overrides of __setitem__ and __getitem__, and arithmetic
will respect overrides of __add__, __sub__, etc.
Changes¶
dotblas functionality moved to multiarray¶
The cblas versions of dot, inner, and vdot have been integrated into the multiarray module. In particular, vdot is now a multiarray function, which it was not before.
stricter check of gufunc signature compliance¶
Inputs to generalized universal functions are now more strictly checked against the function’s signature: all core dimensions are now required to be present in input arrays; core dimensions with the same label must have the exact same size; and output core dimension’s must be specified, either by a same label input core dimension or by a passed-in output array.
views returned from np.einsum are writeable¶
Views returned by np.einsum will now be writeable whenever the input array is writeable.
np.argmin skips NaT values¶
np.argmin now skips NaT values in datetime64 and timedelta64 arrays, making it consistent with np.min, np.argmax and np.max.
Deprecations¶
Array comparisons involving strings or structured dtypes¶
Normally, comparison operations on arrays perform elementwise comparisons and return arrays of booleans. But in some corner cases, especially involving strings are structured dtypes, NumPy has historically returned a scalar instead. For example:
### Current behaviour
np.arange(2) == "foo"
# -> False
np.arange(2) < "foo"
# -> True on Python 2, error on Python 3
np.ones(2, dtype="i4,i4") == np.ones(2, dtype="i4,i4,i4")
# -> False
Continuing work started in 1.9, in 1.10 these comparisons will now
raise FutureWarning or DeprecationWarning, and in the future
they will be modified to behave more consistently with other
comparison operations, e.g.:
### Future behaviour
np.arange(2) == "foo"
# -> array([False, False])
np.arange(2) < "foo"
# -> error, strings and numbers are not orderable
np.ones(2, dtype="i4,i4") == np.ones(2, dtype="i4,i4,i4")
# -> [False, False]
SafeEval¶
The SafeEval class in numpy/lib/utils.py is deprecated and will be removed in the next release.
alterdot, restoredot¶
The alterdot and restoredot functions no longer do anything, and are deprecated.
pkgload, PackageLoader¶
These ways of loading packages are now deprecated.
bias, ddof arguments to corrcoef¶
The values for the bias and ddof arguments to the corrcoef
function canceled in the division implied by the correlation coefficient and
so had no effect on the returned values.
We now deprecate these arguments to corrcoef and the masked array version
ma.corrcoef.
Because we are deprecating the bias argument to ma.corrcoef, we also
deprecate the use of the allow_masked argument as a positional argument,
as its position will change with the removal of bias. allow_masked
will in due course become a keyword-only argument.
dtype string representation changes¶
Since 1.6, creating a dtype object from its string representation, e.g.
'f4', would issue a deprecation warning if the size did not correspond
to an existing type, and default to creating a dtype of the default size
for the type. Starting with this release, this will now raise a TypeError.
The only exception is object dtypes, where both 'O4' and 'O8' will
still issue a deprecation warning. This platform-dependent representation
will raise an error in the next release.
In preparation for this upcoming change, the string representation of an
object dtype, i.e. np.dtype(object).str, no longer includes the item
size, i.e. will return '|O' instead of '|O4' or '|O8' as
before.
NumPy 1.9.2 Release Notes¶
This is a bugfix only release in the 1.9.x series.
Issues fixed¶
- #5316: fix too large dtype alignment of strings and complex types
- #5424: fix ma.median when used on ndarrays
- #5481: Fix astype for structured array fields of different byte order
- #5354: fix segfault when clipping complex arrays
- #5524: allow np.argpartition on non ndarrays
- #5612: Fixes ndarray.fill to accept full range of uint64
- #5155: Fix loadtxt with comments=None and a string None data
- #4476: Masked array view fails if structured dtype has datetime component
- #5388: Make RandomState.set_state and RandomState.get_state threadsafe
- #5390: make seed, randint and shuffle threadsafe
- #5374: Fixed incorrect assert_array_almost_equal_nulp documentation
- #5393: Add support for ATLAS > 3.9.33.
- #5313: PyArray_AsCArray caused segfault for 3d arrays
- #5492: handle out of memory in rfftf
- #4181: fix a few bugs in the random.pareto docstring
- #5359: minor changes to linspace docstring
- #4723: fix a compile issues on AIX
NumPy 1.9.1 Release Notes¶
This is a bugfix only release in the 1.9.x series.
Issues fixed¶
- gh-5184: restore linear edge behaviour of gradient to as it was in < 1.9. The second order behaviour is available via the edge_order keyword
- gh-4007: workaround Accelerate sgemv crash on OSX 10.9
- gh-5100: restore object dtype inference from iterable objects without len()
- gh-5163: avoid gcc-4.1.2 (red hat 5) miscompilation causing a crash
- gh-5138: fix nanmedian on arrays containing inf
- gh-5240: fix not returning out array from ufuncs with subok=False set
- gh-5203: copy inherited masks in MaskedArray.__array_finalize__
- gh-2317: genfromtxt did not handle filling_values=0 correctly
- gh-5067: restore api of npy_PyFile_DupClose in python2
- gh-5063: cannot convert invalid sequence index to tuple
- gh-5082: Segmentation fault with argmin() on unicode arrays
- gh-5095: don’t propagate subtypes from np.where
- gh-5104: np.inner segfaults with SciPy’s sparse matrices
- gh-5251: Issue with fromarrays not using correct format for unicode arrays
- gh-5136: Import dummy_threading if importing threading fails
- gh-5148: Make numpy import when run with Python flag ‘-OO’
- gh-5147: Einsum double contraction in particular order causes ValueError
- gh-479: Make f2py work with intent(in out)
- gh-5170: Make python2 .npy files readable in python3
- gh-5027: Use ‘ll’ as the default length specifier for long long
- gh-4896: fix build error with MSVC 2013 caused by C99 complex support
- gh-4465: Make PyArray_PutTo respect writeable flag
- gh-5225: fix crash when using arange on datetime without dtype set
- gh-5231: fix build in c99 mode
NumPy 1.9.0 Release Notes¶
This release supports Python 2.6 - 2.7 and 3.2 - 3.4.
Highlights¶
- Numerous performance improvements in various areas, most notably indexing and operations on small arrays are significantly faster. Indexing operations now also release the GIL.
- Addition of nanmedian and nanpercentile rounds out the nanfunction set.
Dropped Support¶
- The oldnumeric and numarray modules have been removed.
- The doc/pyrex and doc/cython directories have been removed.
- The doc/numpybook directory has been removed.
- The numpy/testing/numpytest.py file has been removed together with the importall function it contained.
Future Changes¶
- The numpy/polynomial/polytemplate.py file will be removed in NumPy 1.10.0.
- Default casting for inplace operations will change to ‘same_kind’ in Numpy 1.10.0. This will certainly break some code that is currently ignoring the warning.
- Relaxed stride checking will be the default in 1.10.0
- String version checks will break because, e.g., ‘1.9’ > ‘1.10’ is True. A NumpyVersion class has been added that can be used for such comparisons.
- The diagonal and diag functions will return writeable views in 1.10.0
- The S and/or a dtypes may be changed to represent Python strings instead of bytes, in Python 3 these two types are very different.
Compatibility notes¶
The diagonal and diag functions return readonly views.¶
In NumPy 1.8, the diagonal and diag functions returned readonly copies, in NumPy 1.9 they return readonly views, and in 1.10 they will return writeable views.
Special scalar float values don’t cause upcast to double anymore¶
In previous numpy versions operations involving floating point scalars
containing special values NaN, Inf and -Inf caused the result
type to be at least float64. As the special values can be represented
in the smallest available floating point type, the upcast is not performed
anymore.
For example the dtype of:
np.array([1.], dtype=np.float32) * float('nan')
now remains float32 instead of being cast to float64.
Operations involving non-special values have not been changed.
Percentile output changes¶
If given more than one percentile to compute numpy.percentile returns an
array instead of a list. A single percentile still returns a scalar. The
array is equivalent to converting the list returned in older versions
to an array via np.array.
If the overwrite_input option is used the input is only partially
instead of fully sorted.
ndarray.tofile exception type¶
All tofile exceptions are now IOError, some were previously
ValueError.
Invalid fill value exceptions¶
Two changes to numpy.ma.core._check_fill_value:
- When the fill value is a string and the array type is not one of ‘OSUV’, TypeError is raised instead of the default fill value being used.
- When the fill value overflows the array type, TypeError is raised instead of OverflowError.
Polynomial Classes no longer derived from PolyBase¶
This may cause problems with folks who depended on the polynomial classes being derived from PolyBase. They are now all derived from the abstract base class ABCPolyBase. Strictly speaking, there should be a deprecation involved, but no external code making use of the old baseclass could be found.
Using numpy.random.binomial may change the RNG state vs. numpy < 1.9¶
A bug in one of the algorithms to generate a binomial random variate has been fixed. This change will likely alter the number of random draws performed, and hence the sequence location will be different after a call to distribution.c::rk_binomial_btpe. Any tests which rely on the RNG being in a known state should be checked and/or updated as a result.
Random seed enforced to be a 32 bit unsigned integer¶
np.random.seed and np.random.RandomState now throw a ValueError
if the seed cannot safely be converted to 32 bit unsigned integers.
Applications that now fail can be fixed by masking the higher 32 bit values to
zero: seed = seed & 0xFFFFFFFF. This is what is done silently in older
versions so the random stream remains the same.
Argmin and argmax out argument¶
The out argument to np.argmin and np.argmax and their
equivalent C-API functions is now checked to match the desired output shape
exactly. If the check fails a ValueError instead of TypeError is
raised.
Einsum¶
Remove unnecessary broadcasting notation restrictions.
np.einsum('ijk,j->ijk', A, B) can also be written as
np.einsum('ij...,j->ij...', A, B) (ellipsis is no longer required on ‘j’)
Indexing¶
The NumPy indexing has seen a complete rewrite in this version. This makes most advanced integer indexing operations much faster and should have no other implications. However some subtle changes and deprecations were introduced in advanced indexing operations:
- Boolean indexing into scalar arrays will always return a new 1-d array.
This means that
array(1)[array(True)]givesarray([1])and not the original array. - Advanced indexing into one dimensional arrays used to have
(undocumented) special handling regarding repeating the value array in
assignments when the shape of the value array was too small or did not
match. Code using this will raise an error. For compatibility you can
use
arr.flat[index] = values, which uses the old code branch. (for examplea = np.ones(10); a[np.arange(10)] = [1, 2, 3]) - The iteration order over advanced indexes used to be always C-order.
In NumPy 1.9. the iteration order adapts to the inputs and is not
guaranteed (with the exception of a single advanced index which is
never reversed for compatibility reasons). This means that the result
is undefined if multiple values are assigned to the same element. An
example for this is
arr[[0, 0], [1, 1]] = [1, 2], which may setarr[0, 1]to either 1 or 2. - Equivalent to the iteration order, the memory layout of the advanced indexing result is adapted for faster indexing and cannot be predicted.
- All indexing operations return a view or a copy. No indexing operation
will return the original array object. (For example
arr[...]) - In the future Boolean array-likes (such as lists of python bools) will
always be treated as Boolean indexes and Boolean scalars (including
python
True) will be a legal boolean index. At this time, this is already the case for scalar arrays to allow the generalpositive = a[a > 0]to work whenais zero dimensional. - In NumPy 1.8 it was possible to use
array(True)andarray(False)equivalent to 1 and 0 if the result of the operation was a scalar. This will raise an error in NumPy 1.9 and, as noted above, treated as a boolean index in the future. - All non-integer array-likes are deprecated, object arrays of custom integer like objects may have to be cast explicitly.
- The error reporting for advanced indexing is more informative, however
the error type has changed in some cases. (Broadcasting errors of
indexing arrays are reported as
IndexError) - Indexing with more then one ellipsis (
...) is deprecated.
Non-integer reduction axis indexes are deprecated¶
Non-integer axis indexes to reduction ufuncs like add.reduce or sum are deprecated.
promote_types and string dtype¶
promote_types function now returns a valid string length when given an
integer or float dtype as one argument and a string dtype as another
argument. Previously it always returned the input string dtype, even if it
wasn’t long enough to store the max integer/float value converted to a
string.
can_cast and string dtype¶
can_cast function now returns False in “safe” casting mode for
integer/float dtype and string dtype if the string dtype length is not long
enough to store the max integer/float value converted to a string.
Previously can_cast in “safe” mode returned True for integer/float
dtype and a string dtype of any length.
astype and string dtype¶
The astype method now returns an error if the string dtype to cast to
is not long enough in “safe” casting mode to hold the max value of
integer/float array that is being casted. Previously the casting was
allowed even if the result was truncated.
npyio.recfromcsv keyword arguments change¶
npyio.recfromcsv no longer accepts the undocumented update keyword, which used to override the dtype keyword.
The doc/swig directory moved¶
The doc/swig directory has been moved to tools/swig.
The npy_3kcompat.h header changed¶
The unused simple_capsule_dtor function has been removed from
npy_3kcompat.h. Note that this header is not meant to be used outside
of numpy; other projects should be using their own copy of this file when
needed.
Negative indices in C-Api sq_item and sq_ass_item sequence methods¶
When directly accessing the sq_item or sq_ass_item PyObject slots
for item getting, negative indices will not be supported anymore.
PySequence_GetItem and PySequence_SetItem however fix negative
indices so that they can be used there.
NDIter¶
When NpyIter_RemoveAxis is now called, the iterator range will be reset.
When a multi index is being tracked and an iterator is not buffered, it is
possible to use NpyIter_RemoveAxis. In this case an iterator can shrink
in size. Because the total size of an iterator is limited, the iterator
may be too large before these calls. In this case its size will be set to -1
and an error issued not at construction time but when removing the multi
index, setting the iterator range, or getting the next function.
This has no effect on currently working code, but highlights the necessity of checking for an error return if these conditions can occur. In most cases the arrays being iterated are as large as the iterator so that such a problem cannot occur.
This change was already applied to the 1.8.1 release.
zeros_like for string dtypes now returns empty strings¶
To match the zeros function zeros_like now returns an array initialized with empty strings instead of an array filled with ‘0’.
New Features¶
Percentile supports more interpolation options¶
np.percentile now has the interpolation keyword argument to specify in
which way points should be interpolated if the percentiles fall between two
values. See the documentation for the available options.
Generalized axis support for median and percentile¶
np.median and np.percentile now support generalized axis arguments like
ufunc reductions do since 1.7. One can now say axis=(index, index) to pick a
list of axes for the reduction. The keepdims keyword argument was also
added to allow convenient broadcasting to arrays of the original shape.
Dtype parameter added to np.linspace and np.logspace¶
The returned data type from the linspace and logspace functions can
now be specified using the dtype parameter.
More general np.triu and np.tril broadcasting¶
For arrays with ndim exceeding 2, these functions will now apply to the
final two axes instead of raising an exception.
tobytes alias for tostring method¶
ndarray.tobytes and MaskedArray.tobytes have been added as aliases
for tostring which exports arrays as bytes. This is more consistent
in Python 3 where str and bytes are not the same.
Build system¶
Added experimental support for the ppc64le and OpenRISC architecture.
Compatibility to python numbers module¶
All numerical numpy types are now registered with the type hierarchy in
the python numbers module.
increasing parameter added to np.vander¶
The ordering of the columns of the Vandermonde matrix can be specified with this new boolean argument.
unique_counts parameter added to np.unique¶
The number of times each unique item comes up in the input can now be obtained as an optional return value.
Support for median and percentile in nanfunctions¶
The np.nanmedian and np.nanpercentile functions behave like
the median and percentile functions except that NaNs are ignored.
NumpyVersion class added¶
The class may be imported from numpy.lib and can be used for version comparison when the numpy version goes to 1.10.devel. For example:
>>> from numpy.lib import NumpyVersion
>>> if NumpyVersion(np.__version__) < '1.10.0'):
... print('Wow, that is an old NumPy version!')
Allow saving arrays with large number of named columns¶
The numpy storage format 1.0 only allowed the array header to have a total size of 65535 bytes. This can be exceeded by structured arrays with a large number of columns. A new format 2.0 has been added which extends the header size to 4 GiB. np.save will automatically save in 2.0 format if the data requires it, else it will always use the more compatible 1.0 format.
Full broadcasting support for np.cross¶
np.cross now properly broadcasts its two input arrays, even if they
have different number of dimensions. In earlier versions this would result
in either an error being raised, or wrong results computed.
Improvements¶
Better numerical stability for sum in some cases¶
Pairwise summation is now used in the sum method, but only along the fast axis and for groups of the values <= 8192 in length. This should also improve the accuracy of var and std in some common cases.
Percentile implemented in terms of np.partition¶
np.percentile has been implemented in terms of np.partition which
only partially sorts the data via a selection algorithm. This improves the
time complexity from O(nlog(n)) to O(n).
Performance improvement for np.array¶
The performance of converting lists containing arrays to arrays using
np.array has been improved. It is now equivalent in speed to
np.vstack(list).
Performance improvement for np.searchsorted¶
For the built-in numeric types, np.searchsorted no longer relies on the
data type’s compare function to perform the search, but is now
implemented by type specific functions. Depending on the size of the
inputs, this can result in performance improvements over 2x.
Optional reduced verbosity for np.distutils¶
Set numpy.distutils.system_info.system_info.verbosity = 0 and then
calls to numpy.distutils.system_info.get_info('blas_opt') will not
print anything on the output. This is mostly for other packages using
numpy.distutils.
Covariance check in np.random.multivariate_normal¶
A RuntimeWarning warning is raised when the covariance matrix is not
positive-semidefinite.
Polynomial Classes no longer template based¶
The polynomial classes have been refactored to use an abstract base class rather than a template in order to implement a common interface. This makes importing the polynomial package faster as the classes do not need to be compiled on import.
More GIL releases¶
Several more functions now release the Global Interpreter Lock allowing more
efficient parallelization using the threading module. Most notably the GIL is
now released for fancy indexing, np.where and the random module now
uses a per-state lock instead of the GIL.
MaskedArray support for more complicated base classes¶
Built-in assumptions that the baseclass behaved like a plain array are being
removed. In particalur, repr and str should now work more reliably.
C-API¶
Deprecations¶
Non-integer scalars for sequence repetition¶
Using non-integer numpy scalars to repeat python sequences is deprecated.
For example np.float_(2) * [1] will be an error in the future.
select input deprecations¶
The integer and empty input to select is deprecated. In the future only
boolean arrays will be valid conditions and an empty condlist will be
considered an input error instead of returning the default.
rank function¶
The rank function has been deprecated to avoid confusion with
numpy.linalg.matrix_rank.
Object array equality comparisons¶
In the future object array comparisons both == and np.equal will not make use of identity checks anymore. For example:
>>> a = np.array([np.array([1, 2, 3]), 1])
>>> b = np.array([np.array([1, 2, 3]), 1])
>>> a == b
will consistently return False (and in the future an error) even if the array in a and b was the same object.
The equality operator == will in the future raise errors like np.equal if broadcasting or element comparisons, etc. fails.
Comparison with arr == None will in the future do an elementwise comparison instead of just returning False. Code should be using arr is None.
All of these changes will give Deprecation- or FutureWarnings at this time.
C-API¶
The utility function npy_PyFile_Dup and npy_PyFile_DupClose are broken by the internal buffering python 3 applies to its file objects. To fix this two new functions npy_PyFile_Dup2 and npy_PyFile_DupClose2 are declared in npy_3kcompat.h and the old functions are deprecated. Due to the fragile nature of these functions it is recommended to instead use the python API when possible.
This change was already applied to the 1.8.1 release.
NumPy 1.8.2 Release Notes¶
This is a bugfix only release in the 1.8.x series.
Issues fixed¶
- gh-4836: partition produces wrong results for multiple selections in equal ranges
- gh-4656: Make fftpack._raw_fft threadsafe
- gh-4628: incorrect argument order to _copyto in in np.nanmax, np.nanmin
- gh-4642: Hold GIL for converting dtypes types with fields
- gh-4733: fix np.linalg.svd(b, compute_uv=False)
- gh-4853: avoid unaligned simd load on reductions on i386
- gh-4722: Fix seg fault converting empty string to object
- gh-4613: Fix lack of NULL check in array_richcompare
- gh-4774: avoid unaligned access for strided byteswap
- gh-650: Prevent division by zero when creating arrays from some buffers
- gh-4602: ifort has issues with optimization flag O2, use O1
NumPy 1.8.1 Release Notes¶
This is a bugfix only release in the 1.8.x series.
Issues fixed¶
- gh-4276: Fix mean, var, std methods for object arrays
- gh-4262: remove insecure mktemp usage
- gh-2385: absolute(complex(inf)) raises invalid warning in python3
- gh-4024: Sequence assignment doesn’t raise exception on shape mismatch
- gh-4027: Fix chunked reading of strings longer than BUFFERSIZE
- gh-4109: Fix object scalar return type of 0-d array indices
- gh-4018: fix missing check for memory allocation failure in ufuncs
- gh-4156: high order linalg.norm discards imaginary elements of complex arrays
- gh-4144: linalg: norm fails on longdouble, signed int
- gh-4094: fix NaT handling in _strided_to_strided_string_to_datetime
- gh-4051: fix uninitialized use in _strided_to_strided_string_to_datetime
- gh-4093: Loading compressed .npz file fails under Python 2.6.6
- gh-4138: segfault with non-native endian memoryview in python 3.4
- gh-4123: Fix missing NULL check in lexsort
- gh-4170: fix native-only long long check in memoryviews
- gh-4187: Fix large file support on 32 bit
- gh-4152: fromfile: ensure file handle positions are in sync in python3
- gh-4176: clang compatibility: Typos in conversion_utils
- gh-4223: Fetching a non-integer item caused array return
- gh-4197: fix minor memory leak in memoryview failure case
- gh-4206: fix build with single-threaded python
- gh-4220: add versionadded:: 1.8.0 to ufunc.at docstring
- gh-4267: improve handling of memory allocation failure
- gh-4267: fix use of capi without gil in ufunc.at
- gh-4261: Detect vendor versions of GNU Compilers
- gh-4253: IRR was returning nan instead of valid negative answer
- gh-4254: fix unnecessary byte order flag change for byte arrays
- gh-3263: numpy.random.shuffle clobbers mask of a MaskedArray
- gh-4270: np.random.shuffle not work with flexible dtypes
- gh-3173: Segmentation fault when ‘size’ argument to random.multinomial
- gh-2799: allow using unique with lists of complex
- gh-3504: fix linspace truncation for integer array scalar
- gh-4191: get_info(‘openblas’) does not read libraries key
- gh-3348: Access violation in _descriptor_from_pep3118_format
- gh-3175: segmentation fault with numpy.array() from bytearray
- gh-4266: histogramdd - wrong result for entries very close to last boundary
- gh-4408: Fix stride_stricks.as_strided function for object arrays
- gh-4225: fix log1p and exmp1 return for np.inf on windows compiler builds
- gh-4359: Fix infinite recursion in str.format of flex arrays
- gh-4145: Incorrect shape of broadcast result with the exponent operator
- gh-4483: Fix commutativity of {dot,multiply,inner}(scalar, matrix_of_objs)
- gh-4466: Delay npyiter size check when size may change
- gh-4485: Buffered stride was erroneously marked fixed
- gh-4354: byte_bounds fails with datetime dtypes
- gh-4486: segfault/error converting from/to high-precision datetime64 objects
- gh-4428: einsum(None, None, None, None) causes segfault
- gh-4134: uninitialized use for for size 1 object reductions
Changes¶
NDIter¶
When NpyIter_RemoveAxis is now called, the iterator range will be reset.
When a multi index is being tracked and an iterator is not buffered, it is
possible to use NpyIter_RemoveAxis. In this case an iterator can shrink
in size. Because the total size of an iterator is limited, the iterator
may be too large before these calls. In this case its size will be set to -1
and an error issued not at construction time but when removing the multi
index, setting the iterator range, or getting the next function.
This has no effect on currently working code, but highlights the necessity of checking for an error return if these conditions can occur. In most cases the arrays being iterated are as large as the iterator so that such a problem cannot occur.
Optional reduced verbosity for np.distutils¶
Set numpy.distutils.system_info.system_info.verbosity = 0 and then
calls to numpy.distutils.system_info.get_info('blas_opt') will not
print anything on the output. This is mostly for other packages using
numpy.distutils.
Deprecations¶
C-API¶
The utility function npy_PyFile_Dup and npy_PyFile_DupClose are broken by the internal buffering python 3 applies to its file objects. To fix this two new functions npy_PyFile_Dup2 and npy_PyFile_DupClose2 are declared in npy_3kcompat.h and the old functions are deprecated. Due to the fragile nature of these functions it is recommended to instead use the python API when possible.
NumPy 1.8.0 Release Notes¶
This release supports Python 2.6 -2.7 and 3.2 - 3.3.
Highlights¶
- New, no 2to3, Python 2 and Python 3 are supported by a common code base.
- New, gufuncs for linear algebra, enabling operations on stacked arrays.
- New, inplace fancy indexing for ufuncs with the
.atmethod. - New,
partitionfunction, partial sorting via selection for fast median. - New,
nanmean,nanvar, andnanstdfunctions skipping NaNs. - New,
fullandfull_likefunctions to create value initialized arrays. - New,
PyUFunc_RegisterLoopForDescr, better ufunc support for user dtypes. - Numerous performance improvements in many areas.
Dropped Support¶
Support for Python versions 2.4 and 2.5 has been dropped,
Support for SCons has been removed.
Future Changes¶
The Datetime64 type remains experimental in this release. In 1.9 there will probably be some changes to make it more useable.
The diagonal method currently returns a new array and raises a FutureWarning. In 1.9 it will return a readonly view.
Multiple field selection from an array of structured type currently returns a new array and raises a FutureWarning. In 1.9 it will return a readonly view.
The numpy/oldnumeric and numpy/numarray compatibility modules will be removed in 1.9.
Compatibility notes¶
The doc/sphinxext content has been moved into its own github repository, and is included in numpy as a submodule. See the instructions in doc/HOWTO_BUILD_DOCS.rst.txt for how to access the content.
The hash function of numpy.void scalars has been changed. Previously the pointer to the data was hashed as an integer. Now, the hash function uses the tuple-hash algorithm to combine the hash functions of the elements of the scalar, but only if the scalar is read-only.
Numpy has switched its build system to using ‘separate compilation’ by default. In previous releases this was supported, but not default. This should produce the same results as the old system, but if you’re trying to do something complicated like link numpy statically or using an unusual compiler, then it’s possible you will encounter problems. If so, please file a bug and as a temporary workaround you can re-enable the old build system by exporting the shell variable NPY_SEPARATE_COMPILATION=0.
For the AdvancedNew iterator the oa_ndim flag should now be -1 to indicate
that no op_axes and itershape are passed in. The oa_ndim == 0
case, now indicates a 0-D iteration and op_axes being NULL and the old
usage is deprecated. This does not effect the NpyIter_New or
NpyIter_MultiNew functions.
The functions nanargmin and nanargmax now return np.iinfo[‘intp’].min for the index in all-NaN slices. Previously the functions would raise a ValueError for array returns and NaN for scalar returns.
NPY_RELAXED_STRIDES_CHECKING¶
There is a new compile time environment variable
NPY_RELAXED_STRIDES_CHECKING. If this variable is set to 1, then
numpy will consider more arrays to be C- or F-contiguous – for
example, it becomes possible to have a column vector which is
considered both C- and F-contiguous simultaneously. The new definition
is more accurate, allows for faster code that makes fewer unnecessary
copies, and simplifies numpy’s code internally. However, it may also
break third-party libraries that make too-strong assumptions about the
stride values of C- and F-contiguous arrays. (It is also currently
known that this breaks Cython code using memoryviews, which will be
fixed in Cython.) THIS WILL BECOME THE DEFAULT IN A FUTURE RELEASE, SO
PLEASE TEST YOUR CODE NOW AGAINST NUMPY BUILT WITH:
NPY_RELAXED_STRIDES_CHECKING=1 python setup.py install
You can check whether NPY_RELAXED_STRIDES_CHECKING is in effect by running:
np.ones((10, 1), order="C").flags.f_contiguous
This will be True if relaxed strides checking is enabled, and
False otherwise. The typical problem we’ve seen so far is C code
that works with C-contiguous arrays, and assumes that the itemsize can
be accessed by looking at the last element in the PyArray_STRIDES(arr)
array. When relaxed strides are in effect, this is not true (and in
fact, it never was true in some corner cases). Instead, use
PyArray_ITEMSIZE(arr).
For more information check the “Internal memory layout of an ndarray” section in the documentation.
Binary operations with non-arrays as second argument¶
Binary operations of the form <array-or-subclass> * <non-array-subclass>
where <non-array-subclass> declares an __array_priority__ higher than
that of <array-or-subclass> will now unconditionally return
NotImplemented, giving <non-array-subclass> a chance to handle the
operation. Previously, NotImplemented would only be returned if
<non-array-subclass> actually implemented the reversed operation, and after
a (potentially expensive) array conversion of <non-array-subclass> had been
attempted. (bug, pull request)
Function median used with overwrite_input only partially sorts array¶
If median is used with overwrite_input option the input array will now only be partially sorted instead of fully sorted.
Fix to financial.npv¶
The npv function had a bug. Contrary to what the documentation stated, it
summed from indexes 1 to M instead of from 0 to M - 1. The
fix changes the returned value. The mirr function called the npv function,
but worked around the problem, so that was also fixed and the return value
of the mirr function remains unchanged.
Runtime warnings when comparing NaN numbers¶
Comparing NaN floating point numbers now raises the invalid runtime
warning. If a NaN is expected the warning can be ignored using np.errstate.
E.g.:
with np.errstate(invalid='ignore'):
operation()
New Features¶
Support for linear algebra on stacked arrays¶
The gufunc machinery is now used for np.linalg, allowing operations on stacked arrays and vectors. For example:
>>> a
array([[[ 1., 1.],
[ 0., 1.]],
[[ 1., 1.],
[ 0., 1.]]])
>>> np.linalg.inv(a)
array([[[ 1., -1.],
[ 0., 1.]],
[[ 1., -1.],
[ 0., 1.]]])
In place fancy indexing for ufuncs¶
The function at has been added to ufunc objects to allow in place
ufuncs with no buffering when fancy indexing is used. For example, the
following will increment the first and second items in the array, and will
increment the third item twice: numpy.add.at(arr, [0, 1, 2, 2], 1)
This is what many have mistakenly thought arr[[0, 1, 2, 2]] += 1 would do,
but that does not work as the incremented value of arr[2] is simply copied
into the third slot in arr twice, not incremented twice.
New functions partition and argpartition¶
New functions to partially sort arrays via a selection algorithm.
A partition by index k moves the k smallest element to the front of
an array. All elements before k are then smaller or equal than the value
in position k and all elements following k are then greater or equal
than the value in position k. The ordering of the values within these
bounds is undefined.
A sequence of indices can be provided to sort all of them into their sorted
position at once iterative partitioning.
This can be used to efficiently obtain order statistics like median or
percentiles of samples.
partition has a linear time complexity of O(n) while a full sort has
O(n log(n)).
New functions nanmean, nanvar and nanstd¶
New nan aware statistical functions are added. In these functions the results are what would be obtained if nan values were omitted from all computations.
New functions full and full_like¶
New convenience functions to create arrays filled with a specific value; complementary to the existing zeros and zeros_like functions.
IO compatibility with large files¶
Large NPZ files >2GB can be loaded on 64-bit systems.
Building against OpenBLAS¶
It is now possible to build numpy against OpenBLAS by editing site.cfg.
New constant¶
Euler’s constant is now exposed in numpy as euler_gamma.
New modes for qr¶
New modes ‘complete’, ‘reduced’, and ‘raw’ have been added to the qr factorization and the old ‘full’ and ‘economic’ modes are deprecated. The ‘reduced’ mode replaces the old ‘full’ mode and is the default as was the ‘full’ mode, so backward compatibility can be maintained by not specifying the mode.
The ‘complete’ mode returns a full dimensional factorization, which can be useful for obtaining a basis for the orthogonal complement of the range space. The ‘raw’ mode returns arrays that contain the Householder reflectors and scaling factors that can be used in the future to apply q without needing to convert to a matrix. The ‘economic’ mode is simply deprecated, there isn’t much use for it and it isn’t any more efficient than the ‘raw’ mode.
New invert argument to in1d¶
The function in1d now accepts a invert argument which, when True, causes the returned array to be inverted.
Advanced indexing using np.newaxis¶
It is now possible to use np.newaxis/None together with index
arrays instead of only in simple indices. This means that
array[np.newaxis, [0, 1]] will now work as expected and select the first
two rows while prepending a new axis to the array.
C-API¶
New ufuncs can now be registered with builtin input types and a custom output type. Before this change, NumPy wouldn’t be able to find the right ufunc loop function when the ufunc was called from Python, because the ufunc loop signature matching logic wasn’t looking at the output operand type. Now the correct ufunc loop is found, as long as the user provides an output argument with the correct output type.
runtests.py¶
A simple test runner script runtests.py was added. It also builds Numpy via
setup.py build and can be used to run tests easily during development.
Improvements¶
IO performance improvements¶
Performance in reading large files was improved by chunking (see also IO compatibility).
Performance improvements to pad¶
The pad function has a new implementation, greatly improving performance for all inputs except mode= (retained for backwards compatibility). Scaling with dimensionality is dramatically improved for rank >= 4.
Performance improvements to isnan, isinf, isfinite and byteswap¶
isnan, isinf, isfinite and byteswap have been improved to take advantage of compiler builtins to avoid expensive calls to libc. This improves performance of these operations by about a factor of two on gnu libc systems.
Performance improvements via SSE2 vectorization¶
Several functions have been optimized to make use of SSE2 CPU SIMD instructions.
- Float32 and float64:
- base math (add, subtract, divide, multiply)
- sqrt
- minimum/maximum
- absolute
- Bool:
- logical_or
- logical_and
- logical_not
This improves performance of these operations up to 4x/2x for float32/float64 and up to 10x for bool depending on the location of the data in the CPU caches. The performance gain is greatest for in-place operations.
In order to use the improved functions the SSE2 instruction set must be enabled at compile time. It is enabled by default on x86_64 systems. On x86_32 with a capable CPU it must be enabled by passing the appropriate flag to the CFLAGS build variable (-msse2 with gcc).
Performance improvements to median¶
median is now implemented in terms of partition instead of sort which reduces its time complexity from O(n log(n)) to O(n). If used with the overwrite_input option the array will now only be partially sorted instead of fully sorted.
Overrideable operand flags in ufunc C-API¶
When creating a ufunc, the default ufunc operand flags can be overridden via the new op_flags attribute of the ufunc object. For example, to set the operand flag for the first input to read/write:
PyObject *ufunc = PyUFunc_FromFuncAndData(...); ufunc->op_flags[0] = NPY_ITER_READWRITE;
This allows a ufunc to perform an operation in place. Also, global nditer flags can be overridden via the new iter_flags attribute of the ufunc object. For example, to set the reduce flag for a ufunc:
ufunc->iter_flags = NPY_ITER_REDUCE_OK;
Changes¶
General¶
The function np.take now allows 0-d arrays as indices.
The separate compilation mode is now enabled by default.
Several changes to np.insert and np.delete:
- Previously, negative indices and indices that pointed past the end of the array were simply ignored. Now, this will raise a Future or Deprecation Warning. In the future they will be treated like normal indexing treats them – negative indices will wrap around, and out-of-bound indices will generate an error.
- Previously, boolean indices were treated as if they were integers (always referring to either the 0th or 1st item in the array). In the future, they will be treated as masks. In this release, they raise a FutureWarning warning of this coming change.
- In Numpy 1.7. np.insert already allowed the syntax np.insert(arr, 3, [1,2,3]) to insert multiple items at a single position. In Numpy 1.8. this is also possible for np.insert(arr, [3], [1, 2, 3]).
Padded regions from np.pad are now correctly rounded, not truncated.
C-API Array Additions¶
Four new functions have been added to the array C-API.
- PyArray_Partition
- PyArray_ArgPartition
- PyArray_SelectkindConverter
- PyDataMem_NEW_ZEROED
C-API Ufunc Additions¶
One new function has been added to the ufunc C-API that allows to register an inner loop for user types using the descr.
- PyUFunc_RegisterLoopForDescr
C-API Developer Improvements¶
The PyArray_Type instance creation function tp_new now
uses tp_basicsize to determine how much memory to allocate.
In previous releases only sizeof(PyArrayObject) bytes of
memory were allocated, often requiring C-API subtypes to
reimplement tp_new.
Deprecations¶
The ‘full’ and ‘economic’ modes of qr factorization are deprecated.
General¶
The use of non-integer for indices and most integer arguments has been deprecated. Previously float indices and function arguments such as axes or shapes were truncated to integers without warning. For example arr.reshape(3., -1) or arr[0.] will trigger a deprecation warning in NumPy 1.8., and in some future version of NumPy they will raise an error.
Authors¶
This release contains work by the following people who contributed at least one patch to this release. The names are in alphabetical order by first name:
- 87
- Adam Ginsburg +
- Adam Griffiths +
- Alexander Belopolsky +
- Alex Barth +
- Alex Ford +
- Andreas Hilboll +
- Andreas Kloeckner +
- Andreas Schwab +
- Andrew Horton +
- argriffing +
- Arink Verma +
- Bago Amirbekian +
- Bartosz Telenczuk +
- bebert218 +
- Benjamin Root +
- Bill Spotz +
- Bradley M. Froehle
- Carwyn Pelley +
- Charles Harris
- Chris
- Christian Brueffer +
- Christoph Dann +
- Christoph Gohlke
- Dan Hipschman +
- Daniel +
- Dan Miller +
- daveydave400 +
- David Cournapeau
- David Warde-Farley
- Denis Laxalde
- dmuellner +
- Edward Catmur +
- Egor Zindy +
- endolith
- Eric Firing
- Eric Fode
- Eric Moore +
- Eric Price +
- Fazlul Shahriar +
- Félix Hartmann +
- Fernando Perez
- Frank B +
- Frank Breitling +
- Frederic
- Gabriel
- GaelVaroquaux
- Guillaume Gay +
- Han Genuit
- HaroldMills +
- hklemm +
- jamestwebber +
- Jason Madden +
- Jay Bourque
- jeromekelleher +
- Jesús Gómez +
- jmozmoz +
- jnothman +
- Johannes Schönberger +
- John Benediktsson +
- John Salvatier +
- John Stechschulte +
- Jonathan Waltman +
- Joon Ro +
- Jos de Kloe +
- Joseph Martinot-Lagarde +
- Josh Warner (Mac) +
- Jostein Bø Fløystad +
- Juan Luis Cano Rodríguez +
- Julian Taylor +
- Julien Phalip +
- K.-Michael Aye +
- Kumar Appaiah +
- Lars Buitinck
- Leon Weber +
- Luis Pedro Coelho
- Marcin Juszkiewicz
- Mark Wiebe
- Marten van Kerkwijk +
- Martin Baeuml +
- Martin Spacek
- Martin Teichmann +
- Matt Davis +
- Matthew Brett
- Maximilian Albert +
- m-d-w +
- Michael Droettboom
- mwtoews +
- Nathaniel J. Smith
- Nicolas Scheffer +
- Nils Werner +
- ochoadavid +
- Ondřej Čertík
- ovillellas +
- Paul Ivanov
- Pauli Virtanen
- peterjc
- Ralf Gommers
- Raul Cota +
- Richard Hattersley +
- Robert Costa +
- Robert Kern
- Rob Ruana +
- Ronan Lamy
- Sandro Tosi
- Sascha Peilicke +
- Sebastian Berg
- Skipper Seabold
- Stefan van der Walt
- Steve +
- Takafumi Arakaki +
- Thomas Robitaille +
- Tomas Tomecek +
- Travis E. Oliphant
- Valentin Haenel
- Vladimir Rutsky +
- Warren Weckesser
- Yaroslav Halchenko
- Yury V. Zaytsev +
A total of 119 people contributed to this release. People with a “+” by their names contributed a patch for the first time.
NumPy 1.7.2 Release Notes¶
This is a bugfix only release in the 1.7.x series. It supports Python 2.4 - 2.7 and 3.1 - 3.3 and is the last series that supports Python 2.4 - 2.5.
Issues fixed¶
- gh-3153: Do not reuse nditer buffers when not filled enough
- gh-3192: f2py crashes with UnboundLocalError exception
- gh-442: Concatenate with axis=None now requires equal number of array elements
- gh-2485: Fix for astype(‘S’) string truncate issue
- gh-3312: bug in count_nonzero
- gh-2684: numpy.ma.average casts complex to float under certain conditions
- gh-2403: masked array with named components does not behave as expected
- gh-2495: np.ma.compress treated inputs in wrong order
- gh-576: add __len__ method to ma.mvoid
- gh-3364: reduce performance regression of mmap slicing
- gh-3421: fix non-swapping strided copies in GetStridedCopySwap
- gh-3373: fix small leak in datetime metadata initialization
- gh-2791: add platform specific python include directories to search paths
- gh-3168: fix undefined function and add integer divisions
- gh-3301: memmap does not work with TemporaryFile in python3
- gh-3057: distutils.misc_util.get_shared_lib_extension returns wrong debug extension
- gh-3472: add module extensions to load_library search list
- gh-3324: Make comparison function (gt, ge, ...) respect __array_priority__
- gh-3497: np.insert behaves incorrectly with argument ‘axis=-1’
- gh-3541: make preprocessor tests consistent in halffloat.c
- gh-3458: array_ass_boolean_subscript() writes ‘non-existent’ data to array
- gh-2892: Regression in ufunc.reduceat with zero-sized index array
- gh-3608: Regression when filling struct from tuple
- gh-3701: add support for Python 3.4 ast.NameConstant
- gh-3712: do not assume that GIL is enabled in xerbla
- gh-3712: fix LAPACK error handling in lapack_litemodule
- gh-3728: f2py fix decref on wrong object
- gh-3743: Hash changed signature in Python 3.3
- gh-3793: scalar int hashing broken on 64 bit python3
- gh-3160: SandboxViolation easyinstalling 1.7.0 on Mac OS X 10.8.3
- gh-3871: npy_math.h has invalid isinf for Solaris with SUNWspro12.2
- gh-2561: Disable check for oldstyle classes in python3
- gh-3900: Ensure NotImplemented is passed on in MaskedArray ufunc’s
- gh-2052: del scalar subscript causes segfault
- gh-3832: fix a few uninitialized uses and memleaks
- gh-3971: f2py changed string.lowercase to string.ascii_lowercase for python3
- gh-3480: numpy.random.binomial raised ValueError for n == 0
- gh-3992: hypot(inf, 0) shouldn’t raise a warning, hypot(inf, inf) wrong result
- gh-4018: Segmentation fault dealing with very large arrays
- gh-4094: fix NaT handling in _strided_to_strided_string_to_datetime
- gh-4051: fix uninitialized use in _strided_to_strided_string_to_datetime
- gh-4123: lexsort segfault
- gh-4141: Fix a few issues that show up with python 3.4b1
NumPy 1.7.1 Release Notes¶
This is a bugfix only release in the 1.7.x series. It supports Python 2.4 - 2.7 and 3.1 - 3.3 and is the last series that supports Python 2.4 - 2.5.
Issues fixed¶
- gh-2973: Fix 1 is printed during numpy.test()
- gh-2983: BUG: gh-2969: Backport memory leak fix 80b3a34.
- gh-3007: Backport gh-3006
- gh-2984: Backport fix complex polynomial fit
- gh-2982: BUG: Make nansum work with booleans.
- gh-2985: Backport large sort fixes
- gh-3039: Backport object take
- gh-3105: Backport nditer fix op axes initialization
- gh-3108: BUG: npy-pkg-config ini files were missing after Bento build.
- gh-3124: BUG: PyArray_LexSort allocates too much temporary memory.
- gh-3131: BUG: Exported f2py_size symbol prevents linking multiple f2py modules.
- gh-3117: Backport gh-2992
- gh-3135: DOC: Add mention of PyArray_SetBaseObject stealing a reference
- gh-3134: DOC: Fix typo in fft docs (the indexing variable is ‘m’, not ‘n’).
- gh-3136: Backport #3128
NumPy 1.7.0 Release Notes¶
This release includes several new features as well as numerous bug fixes and refactorings. It supports Python 2.4 - 2.7 and 3.1 - 3.3 and is the last release that supports Python 2.4 - 2.5.
Highlights¶
where=parameter to ufuncs (allows the use of boolean arrays to choose where a computation should be done)vectorizeimprovements (added ‘excluded’ and ‘cache’ keyword, general cleanup and bug fixes)numpy.random.choice(random sample generating function)
Compatibility notes¶
In a future version of numpy, the functions np.diag, np.diagonal, and the diagonal method of ndarrays will return a view onto the original array, instead of producing a copy as they do now. This makes a difference if you write to the array returned by any of these functions. To facilitate this transition, numpy 1.7 produces a FutureWarning if it detects that you may be attempting to write to such an array. See the documentation for np.diagonal for details.
Similar to np.diagonal above, in a future version of numpy, indexing a record array by a list of field names will return a view onto the original array, instead of producing a copy as they do now. As with np.diagonal, numpy 1.7 produces a FutureWarning if it detects that you may be attempting to write to such an array. See the documentation for array indexing for details.
In a future version of numpy, the default casting rule for UFunc out= parameters will be changed from ‘unsafe’ to ‘same_kind’. (This also applies to in-place operations like a += b, which is equivalent to np.add(a, b, out=a).) Most usages which violate the ‘same_kind’ rule are likely bugs, so this change may expose previously undetected errors in projects that depend on NumPy. In this version of numpy, such usages will continue to succeed, but will raise a DeprecationWarning.
Full-array boolean indexing has been optimized to use a different, optimized code path. This code path should produce the same results, but any feedback about changes to your code would be appreciated.
Attempting to write to a read-only array (one with arr.flags.writeable
set to False) used to raise either a RuntimeError, ValueError, or
TypeError inconsistently, depending on which code path was taken. It now
consistently raises a ValueError.
The <ufunc>.reduce functions evaluate some reductions in a different order than in previous versions of NumPy, generally providing higher performance. Because of the nature of floating-point arithmetic, this may subtly change some results, just as linking NumPy to a different BLAS implementations such as MKL can.
If upgrading from 1.5, then generally in 1.6 and 1.7 there have been substantial code added and some code paths altered, particularly in the areas of type resolution and buffered iteration over universal functions. This might have an impact on your code particularly if you relied on accidental behavior in the past.
New features¶
Reduction UFuncs Generalize axis= Parameter¶
Any ufunc.reduce function call, as well as other reductions like sum, prod, any, all, max and min support the ability to choose a subset of the axes to reduce over. Previously, one could say axis=None to mean all the axes or axis=# to pick a single axis. Now, one can also say axis=(#,#) to pick a list of axes for reduction.
Reduction UFuncs New keepdims= Parameter¶
There is a new keepdims= parameter, which if set to True, doesn’t throw away the reduction axes but instead sets them to have size one. When this option is set, the reduction result will broadcast correctly to the original operand which was reduced.
Datetime support¶
Note
The datetime API is experimental in 1.7.0, and may undergo changes in future versions of NumPy.
There have been a lot of fixes and enhancements to datetime64 compared to NumPy 1.6:
- the parser is quite strict about only accepting ISO 8601 dates, with a few convenience extensions
- converts between units correctly
- datetime arithmetic works correctly
- business day functionality (allows the datetime to be used in contexts where only certain days of the week are valid)
The notes in doc/source/reference/arrays.datetime.rst (also available in the online docs at arrays.datetime.html) should be consulted for more details.
Custom formatter for printing arrays¶
See the new formatter parameter of the numpy.set_printoptions
function.
New function numpy.random.choice¶
A generic sampling function has been added which will generate samples from a given array-like. The samples can be with or without replacement, and with uniform or given non-uniform probabilities.
New function isclose¶
Returns a boolean array where two arrays are element-wise equal within a tolerance. Both relative and absolute tolerance can be specified.
Preliminary multi-dimensional support in the polynomial package¶
Axis keywords have been added to the integration and differentiation functions and a tensor keyword was added to the evaluation functions. These additions allow multi-dimensional coefficient arrays to be used in those functions. New functions for evaluating 2-D and 3-D coefficient arrays on grids or sets of points were added together with 2-D and 3-D pseudo-Vandermonde matrices that can be used for fitting.
Ability to pad rank-n arrays¶
A pad module containing functions for padding n-dimensional arrays has been added. The various private padding functions are exposed as options to a public ‘pad’ function. Example:
pad(a, 5, mode='mean')
Current modes are constant, edge, linear_ramp, maximum,
mean, median, minimum, reflect, symmetric, wrap, and
<function>.
New argument to searchsorted¶
The function searchsorted now accepts a ‘sorter’ argument that is a permutation array that sorts the array to search.
Build system¶
Added experimental support for the AArch64 architecture.
C API¶
New function PyArray_RequireWriteable provides a consistent interface
for checking array writeability – any C code which works with arrays whose
WRITEABLE flag is not known to be True a priori, should make sure to call
this function before writing.
NumPy C Style Guide added (doc/C_STYLE_GUIDE.rst.txt).
Changes¶
General¶
The function np.concatenate tries to match the layout of its input arrays. Previously, the layout did not follow any particular reason, and depended in an undesirable way on the particular axis chosen for concatenation. A bug was also fixed which silently allowed out of bounds axis arguments.
The ufuncs logical_or, logical_and, and logical_not now follow Python’s behavior with object arrays, instead of trying to call methods on the objects. For example the expression (3 and ‘test’) produces the string ‘test’, and now np.logical_and(np.array(3, ‘O’), np.array(‘test’, ‘O’)) produces ‘test’ as well.
The .base attribute on ndarrays, which is used on views to ensure that the
underlying array owning the memory is not deallocated prematurely, now
collapses out references when you have a view-of-a-view. For example:
a = np.arange(10)
b = a[1:]
c = b[1:]
In numpy 1.6, c.base is b, and c.base.base is a. In numpy 1.7,
c.base is a.
To increase backwards compatibility for software which relies on the old
behaviour of .base, we only ‘skip over’ objects which have exactly the same
type as the newly created view. This makes a difference if you use ndarray
subclasses. For example, if we have a mix of ndarray and matrix objects
which are all views on the same original ndarray:
a = np.arange(10)
b = np.asmatrix(a)
c = b[0, 1:]
d = c[0, 1:]
then d.base will be b. This is because d is a matrix object,
and so the collapsing process only continues so long as it encounters other
matrix objects. It considers c, b, and a in that order, and
b is the last entry in that list which is a matrix object.
Casting Rules¶
Casting rules have undergone some changes in corner cases, due to the NA-related work. In particular for combinations of scalar+scalar:
- the longlong type (q) now stays longlong for operations with any other number (? b h i l q p B H I), previously it was cast as int_ (l). The ulonglong type (Q) now stays as ulonglong instead of uint (L).
- the timedelta64 type (m) can now be mixed with any integer type (b h i l q p B H I L Q P), previously it raised TypeError.
For array + scalar, the above rules just broadcast except the case when the array and scalars are unsigned/signed integers, then the result gets converted to the array type (of possibly larger size) as illustrated by the following examples:
>>> (np.zeros((2,), dtype=np.uint8) + np.int16(257)).dtype
dtype('uint16')
>>> (np.zeros((2,), dtype=np.int8) + np.uint16(257)).dtype
dtype('int16')
>>> (np.zeros((2,), dtype=np.int16) + np.uint32(2**17)).dtype
dtype('int32')
Whether the size gets increased depends on the size of the scalar, for example:
>>> (np.zeros((2,), dtype=np.uint8) + np.int16(255)).dtype
dtype('uint8')
>>> (np.zeros((2,), dtype=np.uint8) + np.int16(256)).dtype
dtype('uint16')
Also a complex128 scalar + float32 array is cast to complex64.
In NumPy 1.7 the datetime64 type (M) must be constructed by explicitly
specifying the type as the second argument (e.g. np.datetime64(2000, 'Y')).
Deprecations¶
General¶
Specifying a custom string formatter with a _format array attribute is
deprecated. The new formatter keyword in numpy.set_printoptions or
numpy.array2string can be used instead.
The deprecated imports in the polynomial package have been removed.
concatenate now raises DepractionWarning for 1D arrays if axis != 0.
Versions of numpy < 1.7.0 ignored axis argument value for 1D arrays. We
allow this for now, but in due course we will raise an error.
C-API¶
Direct access to the fields of PyArrayObject* has been deprecated. Direct access has been recommended against for many releases. Expect similar deprecations for PyArray_Descr* and other core objects in the future as preparation for NumPy 2.0.
The macros in old_defines.h are deprecated and will be removed in the next major release (>= 2.0). The sed script tools/replace_old_macros.sed can be used to replace these macros with the newer versions.
You can test your code against the deprecated C API by #defining NPY_NO_DEPRECATED_API to the target version number, for example NPY_1_7_API_VERSION, before including any NumPy headers.
The NPY_CHAR member of the NPY_TYPES enum is deprecated and will be
removed in NumPy 1.8. See the discussion at
gh-2801 for more details.
NumPy 1.6.2 Release Notes¶
This is a bugfix release in the 1.6.x series. Due to the delay of the NumPy 1.7.0 release, this release contains far more fixes than a regular NumPy bugfix release. It also includes a number of documentation and build improvements.
Issues fixed¶
numpy.core¶
- #2063: make unique() return consistent index
- #1138: allow creating arrays from empty buffers or empty slices
- #1446: correct note about correspondence vstack and concatenate
- #1149: make argmin() work for datetime
- #1672: fix allclose() to work for scalar inf
- #1747: make np.median() work for 0-D arrays
- #1776: make complex division by zero to yield inf properly
- #1675: add scalar support for the format() function
- #1905: explicitly check for NaNs in allclose()
- #1952: allow floating ddof in std() and var()
- #1948: fix regression for indexing chararrays with empty list
- #2017: fix type hashing
- #2046: deleting array attributes causes segfault
- #2033: a**2.0 has incorrect type
- #2045: make attribute/iterator_element deletions not segfault
- #2021: fix segfault in searchsorted()
- #2073: fix float16 __array_interface__ bug
numpy.lib¶
- #2048: break reference cycle in NpzFile
- #1573: savetxt() now handles complex arrays
- #1387: allow bincount() to accept empty arrays
- #1899: fixed histogramdd() bug with empty inputs
- #1793: fix failing npyio test under py3k
- #1936: fix extra nesting for subarray dtypes
- #1848: make tril/triu return the same dtype as the original array
- #1918: use Py_TYPE to access ob_type, so it works also on Py3
numpy.distutils¶
- #1261: change compile flag on AIX from -O5 to -O3
- #1377: update HP compiler flags
- #1383: provide better support for C++ code on HPUX
- #1857: fix build for py3k + pip
- BLD: raise a clearer warning in case of building without cleaning up first
- BLD: follow build_ext coding convention in build_clib
- BLD: fix up detection of Intel CPU on OS X in system_info.py
- BLD: add support for the new X11 directory structure on Ubuntu & co.
- BLD: add ufsparse to the libraries search path.
- BLD: add ‘pgfortran’ as a valid compiler in the Portland Group
- BLD: update version match regexp for IBM AIX Fortran compilers.
numpy.random¶
- BUG: Use npy_intp instead of long in mtrand
Changes¶
numpy.f2py¶
- ENH: Introduce new options extra_f77_compiler_args and extra_f90_compiler_args
- BLD: Improve reporting of fcompiler value
- BUG: Fix f2py test_kind.py test
numpy.poly¶
- ENH: Add some tests for polynomial printing
- ENH: Add companion matrix functions
- DOC: Rearrange the polynomial documents
- BUG: Fix up links to classes
- DOC: Add version added to some of the polynomial package modules
- DOC: Document xxxfit functions in the polynomial package modules
- BUG: The polynomial convenience classes let different types interact
- DOC: Document the use of the polynomial convenience classes
- DOC: Improve numpy reference documentation of polynomial classes
- ENH: Improve the computation of polynomials from roots
- STY: Code cleanup in polynomial [*]fromroots functions
- DOC: Remove references to cast and NA, which were added in 1.7
NumPy 1.6.1 Release Notes¶
This is a bugfix only release in the 1.6.x series.
Issues Fixed¶
- #1834: einsum fails for specific shapes
- #1837: einsum throws nan or freezes python for specific array shapes
- #1838: object <-> structured type arrays regression
- #1851: regression for SWIG based code in 1.6.0
- #1863: Buggy results when operating on array copied with astype()
- #1870: Fix corner case of object array assignment
- #1843: Py3k: fix error with recarray
- #1885: nditer: Error in detecting double reduction loop
- #1874: f2py: fix –include_paths bug
- #1749: Fix ctypes.load_library()
- #1895/1896: iter: writeonly operands weren’t always being buffered correctly
NumPy 1.6.0 Release Notes¶
This release includes several new features as well as numerous bug fixes and improved documentation. It is backward compatible with the 1.5.0 release, and supports Python 2.4 - 2.7 and 3.1 - 3.2.
Highlights¶
- Re-introduction of datetime dtype support to deal with dates in arrays.
- A new 16-bit floating point type.
- A new iterator, which improves performance of many functions.
New features¶
New 16-bit floating point type¶
This release adds support for the IEEE 754-2008 binary16 format, available as
the data type numpy.half. Within Python, the type behaves similarly to
float or double, and C extensions can add support for it with the exposed
half-float API.
New iterator¶
A new iterator has been added, replacing the functionality of the existing iterator and multi-iterator with a single object and API. This iterator works well with general memory layouts different from C or Fortran contiguous, and handles both standard NumPy and customized broadcasting. The buffering, automatic data type conversion, and optional output parameters, offered by ufuncs but difficult to replicate elsewhere, are now exposed by this iterator.
Legendre, Laguerre, Hermite, HermiteE polynomials in numpy.polynomial¶
Extend the number of polynomials available in the polynomial package. In
addition, a new window attribute has been added to the classes in
order to specify the range the domain maps to. This is mostly useful
for the Laguerre, Hermite, and HermiteE polynomials whose natural domains
are infinite and provides a more intuitive way to get the correct mapping
of values without playing unnatural tricks with the domain.
Fortran assumed shape array and size function support in numpy.f2py¶
F2py now supports wrapping Fortran 90 routines that use assumed shape arrays. Before such routines could be called from Python but the corresponding Fortran routines received assumed shape arrays as zero length arrays which caused unpredicted results. Thanks to Lorenz Hüdepohl for pointing out the correct way to interface routines with assumed shape arrays.
In addition, f2py supports now automatic wrapping of Fortran routines
that use two argument size function in dimension specifications.
Other new functions¶
numpy.ravel_multi_index : Converts a multi-index tuple into
an array of flat indices, applying boundary modes to the indices.
numpy.einsum : Evaluate the Einstein summation convention. Using the
Einstein summation convention, many common multi-dimensional array operations
can be represented in a simple fashion. This function provides a way compute
such summations.
numpy.count_nonzero : Counts the number of non-zero elements in an array.
numpy.result_type and numpy.min_scalar_type : These functions expose
the underlying type promotion used by the ufuncs and other operations to
determine the types of outputs. These improve upon the numpy.common_type
and numpy.mintypecode which provide similar functionality but do
not match the ufunc implementation.
Changes¶
default error handling¶
The default error handling has been change from print to warn for
all except for underflow, which remains as ignore.
numpy.distutils¶
Several new compilers are supported for building Numpy: the Portland Group Fortran compiler on OS X, the PathScale compiler suite and the 64-bit Intel C compiler on Linux.
numpy.testing¶
The testing framework gained numpy.testing.assert_allclose, which provides
a more convenient way to compare floating point arrays than
assert_almost_equal, assert_approx_equal and assert_array_almost_equal.
C API¶
In addition to the APIs for the new iterator and half data type, a number
of other additions have been made to the C API. The type promotion
mechanism used by ufuncs is exposed via PyArray_PromoteTypes,
PyArray_ResultType, and PyArray_MinScalarType. A new enumeration
NPY_CASTING has been added which controls what types of casts are
permitted. This is used by the new functions PyArray_CanCastArrayTo
and PyArray_CanCastTypeTo. A more flexible way to handle
conversion of arbitrary python objects into arrays is exposed by
PyArray_GetArrayParamsFromObject.
Deprecated features¶
The “normed” keyword in numpy.histogram is deprecated. Its functionality
will be replaced by the new “density” keyword.
Removed features¶
numpy.fft¶
The functions refft, refft2, refftn, irefft, irefft2, irefftn, which were aliases for the same functions without the ‘e’ in the name, were removed.
numpy.memmap¶
The sync() and close() methods of memmap were removed. Use flush() and “del memmap” instead.
numpy.lib¶
The deprecated functions numpy.unique1d, numpy.setmember1d,
numpy.intersect1d_nu and numpy.lib.ufunclike.log2 were removed.
numpy.ma¶
Several deprecated items were removed from the numpy.ma module:
* ``numpy.ma.MaskedArray`` "raw_data" method
* ``numpy.ma.MaskedArray`` constructor "flag" keyword
* ``numpy.ma.make_mask`` "flag" keyword
* ``numpy.ma.allclose`` "fill_value" keyword
numpy.distutils¶
The numpy.get_numpy_include function was removed, use numpy.get_include
instead.
NumPy 1.5.0 Release Notes¶
Highlights¶
Python 3 compatibility¶
This is the first NumPy release which is compatible with Python 3. Support for Python 3 and Python 2 is done from a single code base. Extensive notes on changes can be found at http://projects.scipy.org/numpy/browser/trunk/doc/Py3K.txt.
Note that the Numpy testing framework relies on nose, which does not have a Python 3 compatible release yet. A working Python 3 branch of nose can be found at http://bitbucket.org/jpellerin/nose3/ however.
Porting of SciPy to Python 3 is expected to be completed soon.
New features¶
Warning on casting complex to real¶
Numpy now emits a numpy.ComplexWarning when a complex number is cast
into a real number. For example:
>>> x = np.array([1,2,3])
>>> x[:2] = np.array([1+2j, 1-2j])
ComplexWarning: Casting complex values to real discards the imaginary part
The cast indeed discards the imaginary part, and this may not be the intended behavior in all cases, hence the warning. This warning can be turned off in the standard way:
>>> import warnings
>>> warnings.simplefilter("ignore", np.ComplexWarning)
Dot method for ndarrays¶
Ndarrays now have the dot product also as a method, which allows writing chains of matrix products as
>>> a.dot(b).dot(c)
instead of the longer alternative
>>> np.dot(a, np.dot(b, c))
linalg.slogdet function¶
The slogdet function returns the sign and logarithm of the determinant of a matrix. Because the determinant may involve the product of many small/large values, the result is often more accurate than that obtained by simple multiplication.
new header¶
The new header file ndarraytypes.h contains the symbols from ndarrayobject.h that do not depend on the PY_ARRAY_UNIQUE_SYMBOL and NO_IMPORT/_ARRAY macros. Broadly, these symbols are types, typedefs, and enumerations; the array function calls are left in ndarrayobject.h. This allows users to include array-related types and enumerations without needing to concern themselves with the macro expansions and their side- effects.
Changes¶
polynomial.polynomial¶
- The polyint and polyder functions now check that the specified number integrations or derivations is a non-negative integer. The number 0 is a valid value for both functions.
- A degree method has been added to the Polynomial class.
- A trimdeg method has been added to the Polynomial class. It operates like truncate except that the argument is the desired degree of the result, not the number of coefficients.
- Polynomial.fit now uses None as the default domain for the fit. The default Polynomial domain can be specified by using [] as the domain value.
- Weights can be used in both polyfit and Polynomial.fit
- A linspace method has been added to the Polynomial class to ease plotting.
- The polymulx function was added.
polynomial.chebyshev¶
- The chebint and chebder functions now check that the specified number integrations or derivations is a non-negative integer. The number 0 is a valid value for both functions.
- A degree method has been added to the Chebyshev class.
- A trimdeg method has been added to the Chebyshev class. It operates like truncate except that the argument is the desired degree of the result, not the number of coefficients.
- Chebyshev.fit now uses None as the default domain for the fit. The default Chebyshev domain can be specified by using [] as the domain value.
- Weights can be used in both chebfit and Chebyshev.fit
- A linspace method has been added to the Chebyshev class to ease plotting.
- The chebmulx function was added.
- Added functions for the Chebyshev points of the first and second kind.
histogram¶
After a two years transition period, the old behavior of the histogram function has been phased out, and the “new” keyword has been removed.
correlate¶
The old behavior of correlate was deprecated in 1.4.0, the new behavior (the usual definition for cross-correlation) is now the default.
NumPy 1.4.0 Release Notes¶
This minor includes numerous bug fixes, as well as a few new features. It is backward compatible with 1.3.0 release.
Highlights¶
- New datetime dtype support to deal with dates in arrays
- Faster import time
- Extended array wrapping mechanism for ufuncs
- New Neighborhood iterator (C-level only)
- C99-like complex functions in npymath
New features¶
Extended array wrapping mechanism for ufuncs¶
An __array_prepare__ method has been added to ndarray to provide subclasses greater flexibility to interact with ufuncs and ufunc-like functions. ndarray already provided __array_wrap__, which allowed subclasses to set the array type for the result and populate metadata on the way out of the ufunc (as seen in the implementation of MaskedArray). For some applications it is necessary to provide checks and populate metadata on the way in. __array_prepare__ is therefore called just after the ufunc has initialized the output array but before computing the results and populating it. This way, checks can be made and errors raised before operations which may modify data in place.
Automatic detection of forward incompatibilities¶
Previously, if an extension was built against a version N of NumPy, and used on a system with NumPy M < N, the import_array was successful, which could cause crashes because the version M does not have a function in N. Starting from NumPy 1.4.0, this will cause a failure in import_array, so the error will be caught early on.
New iterators¶
A new neighborhood iterator has been added to the C API. It can be used to iterate over the items in a neighborhood of an array, and can handle boundaries conditions automatically. Zero and one padding are available, as well as arbitrary constant value, mirror and circular padding.
New polynomial support¶
New modules chebyshev and polynomial have been added. The new polynomial module is not compatible with the current polynomial support in numpy, but is much like the new chebyshev module. The most noticeable difference to most will be that coefficients are specified from low to high power, that the low level functions do not work with the Chebyshev and Polynomial classes as arguments, and that the Chebyshev and Polynomial classes include a domain. Mapping between domains is a linear substitution and the two classes can be converted one to the other, allowing, for instance, a Chebyshev series in one domain to be expanded as a polynomial in another domain. The new classes should generally be used instead of the low level functions, the latter are provided for those who wish to build their own classes.
The new modules are not automatically imported into the numpy namespace, they must be explicitly brought in with an “import numpy.polynomial” statement.
New C API¶
The following C functions have been added to the C API:
- PyArray_GetNDArrayCFeatureVersion: return the API version of the loaded numpy.
- PyArray_Correlate2 - like PyArray_Correlate, but implements the usual definition of correlation. Inputs are not swapped, and conjugate is taken for complex arrays.
- PyArray_NeighborhoodIterNew - a new iterator to iterate over a neighborhood of a point, with automatic boundaries handling. It is documented in the iterators section of the C-API reference, and you can find some examples in the multiarray_test.c.src file in numpy.core.
New ufuncs¶
The following ufuncs have been added to the C API:
- copysign - return the value of the first argument with the sign copied from the second argument.
- nextafter - return the next representable floating point value of the first argument toward the second argument.
New defines¶
The alpha processor is now defined and available in numpy/npy_cpu.h. The failed detection of the PARISC processor has been fixed. The defines are:
- NPY_CPU_HPPA: PARISC
- NPY_CPU_ALPHA: Alpha
Testing¶
- deprecated decorator: this decorator may be used to avoid cluttering testing output while testing DeprecationWarning is effectively raised by the decorated test.
- assert_array_almost_equal_nulps: new method to compare two arrays of floating point values. With this function, two values are considered close if there are not many representable floating point values in between, thus being more robust than assert_array_almost_equal when the values fluctuate a lot.
- assert_array_max_ulp: raise an assertion if there are more than N representable numbers between two floating point values.
- assert_warns: raise an AssertionError if a callable does not generate a warning of the appropriate class, without altering the warning state.
Reusing npymath¶
In 1.3.0, we started putting portable C math routines in npymath library, so that people can use those to write portable extensions. Unfortunately, it was not possible to easily link against this library: in 1.4.0, support has been added to numpy.distutils so that 3rd party can reuse this library. See coremath documentation for more information.
Improved set operations¶
In previous versions of NumPy some set functions (intersect1d, setxor1d, setdiff1d and setmember1d) could return incorrect results if the input arrays contained duplicate items. These now work correctly for input arrays with duplicates. setmember1d has been renamed to in1d, as with the change to accept arrays with duplicates it is no longer a set operation, and is conceptually similar to an elementwise version of the Python operator ‘in’. All of these functions now accept the boolean keyword assume_unique. This is False by default, but can be set True if the input arrays are known not to contain duplicates, which can increase the functions’ execution speed.
Improvements¶
numpy import is noticeably faster (from 20 to 30 % depending on the platform and computer)
The sort functions now sort nans to the end.
- Real sort order is [R, nan]
- Complex sort order is [R + Rj, R + nanj, nan + Rj, nan + nanj]
Complex numbers with the same nan placements are sorted according to the non-nan part if it exists.
The type comparison functions have been made consistent with the new sort order of nans. Searchsorted now works with sorted arrays containing nan values.
Complex division has been made more resistant to overflow.
Complex floor division has been made more resistant to overflow.
Deprecations¶
The following functions are deprecated:
- correlate: it takes a new keyword argument old_behavior. When True (the default), it returns the same result as before. When False, compute the conventional correlation, and take the conjugate for complex arrays. The old behavior will be removed in NumPy 1.5, and raises a DeprecationWarning in 1.4.
- unique1d: use unique instead. unique1d raises a deprecation warning in 1.4, and will be removed in 1.5.
- intersect1d_nu: use intersect1d instead. intersect1d_nu raises a deprecation warning in 1.4, and will be removed in 1.5.
- setmember1d: use in1d instead. setmember1d raises a deprecation warning in 1.4, and will be removed in 1.5.
The following raise errors:
- When operating on 0-d arrays,
numpy.maxand other functions accept onlyaxis=0,axis=-1andaxis=None. Using an out-of-bounds axes is an indication of a bug, so Numpy raises an error for these cases now.- Specifying
axis > MAX_DIMSis no longer allowed; Numpy raises now an error instead of behaving similarly as foraxis=None.
Internal changes¶
Use C99 complex functions when available¶
The numpy complex types are now guaranteed to be ABI compatible with C99 complex type, if available on the platform. Moreover, the complex ufunc now use the platform C99 functions instead of our own.
split multiarray and umath source code¶
The source code of multiarray and umath has been split into separate logic compilation units. This should make the source code more amenable for newcomers.
Separate compilation¶
By default, every file of multiarray (and umath) is merged into one for compilation as was the case before, but if NPY_SEPARATE_COMPILATION env variable is set to a non-negative value, experimental individual compilation of each file is enabled. This makes the compile/debug cycle much faster when working on core numpy.
Separate core math library¶
New functions which have been added:
- npy_copysign
- npy_nextafter
- npy_cpack
- npy_creal
- npy_cimag
- npy_cabs
- npy_cexp
- npy_clog
- npy_cpow
- npy_csqr
- npy_ccos
- npy_csin
NumPy 1.3.0 Release Notes¶
This minor includes numerous bug fixes, official python 2.6 support, and several new features such as generalized ufuncs.
Highlights¶
Python 2.6 support¶
Python 2.6 is now supported on all previously supported platforms, including windows.
Generalized ufuncs¶
There is a general need for looping over not only functions on scalars but also over functions on vectors (or arrays), as explained on http://scipy.org/scipy/numpy/wiki/GeneralLoopingFunctions. We propose to realize this concept by generalizing the universal functions (ufuncs), and provide a C implementation that adds ~500 lines to the numpy code base. In current (specialized) ufuncs, the elementary function is limited to element-by-element operations, whereas the generalized version supports “sub-array” by “sub-array” operations. The Perl vector library PDL provides a similar functionality and its terms are re-used in the following.
Each generalized ufunc has information associated with it that states what the “core” dimensionality of the inputs is, as well as the corresponding dimensionality of the outputs (the element-wise ufuncs have zero core dimensions). The list of the core dimensions for all arguments is called the “signature” of a ufunc. For example, the ufunc numpy.add has signature “(),()->()” defining two scalar inputs and one scalar output.
Another example is (see the GeneralLoopingFunctions page) the function inner1d(a,b) with a signature of “(i),(i)->()”. This applies the inner product along the last axis of each input, but keeps the remaining indices intact. For example, where a is of shape (3,5,N) and b is of shape (5,N), this will return an output of shape (3,5). The underlying elementary function is called 3*5 times. In the signature, we specify one core dimension “(i)” for each input and zero core dimensions “()” for the output, since it takes two 1-d arrays and returns a scalar. By using the same name “i”, we specify that the two corresponding dimensions should be of the same size (or one of them is of size 1 and will be broadcasted).
The dimensions beyond the core dimensions are called “loop” dimensions. In the above example, this corresponds to (3,5).
The usual numpy “broadcasting” rules apply, where the signature determines how the dimensions of each input/output object are split into core and loop dimensions:
While an input array has a smaller dimensionality than the corresponding number of core dimensions, 1’s are pre-pended to its shape. The core dimensions are removed from all inputs and the remaining dimensions are broadcasted; defining the loop dimensions. The output is given by the loop dimensions plus the output core dimensions.
Experimental Windows 64 bits support¶
Numpy can now be built on windows 64 bits (amd64 only, not IA64), with both MS compilers and mingw-w64 compilers:
This is highly experimental: DO NOT USE FOR PRODUCTION USE. See INSTALL.txt, Windows 64 bits section for more information on limitations and how to build it by yourself.
New features¶
Formatting issues¶
Float formatting is now handled by numpy instead of the C runtime: this enables locale independent formatting, more robust fromstring and related methods. Special values (inf and nan) are also more consistent across platforms (nan vs IND/NaN, etc...), and more consistent with recent python formatting work (in 2.6 and later).
Nan handling in max/min¶
The maximum/minimum ufuncs now reliably propagate nans. If one of the arguments is a nan, then nan is returned. This affects np.min/np.max, amin/amax and the array methods max/min. New ufuncs fmax and fmin have been added to deal with non-propagating nans.
Nan handling in sign¶
The ufunc sign now returns nan for the sign of anan.
New ufuncs¶
- fmax - same as maximum for integer types and non-nan floats. Returns the non-nan argument if one argument is nan and returns nan if both arguments are nan.
- fmin - same as minimum for integer types and non-nan floats. Returns the non-nan argument if one argument is nan and returns nan if both arguments are nan.
- deg2rad - converts degrees to radians, same as the radians ufunc.
- rad2deg - converts radians to degrees, same as the degrees ufunc.
- log2 - base 2 logarithm.
- exp2 - base 2 exponential.
- trunc - truncate floats to nearest integer towards zero.
- logaddexp - add numbers stored as logarithms and return the logarithm of the result.
- logaddexp2 - add numbers stored as base 2 logarithms and return the base 2 logarithm of the result.
Masked arrays¶
Several new features and bug fixes, including:
- structured arrays should now be fully supported by MaskedArray (r6463, r6324, r6305, r6300, r6294...)
- Minor bug fixes (r6356, r6352, r6335, r6299, r6298)
- Improved support for __iter__ (r6326)
- made baseclass, sharedmask and hardmask accessible to the user (but read-only)
- doc update
gfortran support on windows¶
Gfortran can now be used as a fortran compiler for numpy on windows, even when the C compiler is Visual Studio (VS 2005 and above; VS 2003 will NOT work). Gfortran + Visual studio does not work on windows 64 bits (but gcc + gfortran does). It is unclear whether it will be possible to use gfortran and visual studio at all on x64.
Arch option for windows binary¶
Automatic arch detection can now be bypassed from the command line for the superpack installed:
numpy-1.3.0-superpack-win32.exe /arch=nosse
will install a numpy which works on any x86, even if the running computer supports SSE set.
Deprecated features¶
Histogram¶
The semantics of histogram has been modified to fix long-standing issues with outliers handling. The main changes concern
- the definition of the bin edges, now including the rightmost edge, and
- the handling of upper outliers, now ignored rather than tallied in the rightmost bin.
The previous behavior is still accessible using new=False, but this is deprecated, and will be removed entirely in 1.4.0.
Documentation changes¶
A lot of documentation has been added. Both user guide and references can be built from sphinx.
New C API¶
Multiarray API¶
The following functions have been added to the multiarray C API:
- PyArray_GetEndianness: to get runtime endianness
Ufunc API¶
The following functions have been added to the ufunc API:
- PyUFunc_FromFuncAndDataAndSignature: to declare a more general ufunc (generalized ufunc).
New defines¶
New public C defines are available for ARCH specific code through numpy/npy_cpu.h:
- NPY_CPU_X86: x86 arch (32 bits)
- NPY_CPU_AMD64: amd64 arch (x86_64, NOT Itanium)
- NPY_CPU_PPC: 32 bits ppc
- NPY_CPU_PPC64: 64 bits ppc
- NPY_CPU_SPARC: 32 bits sparc
- NPY_CPU_SPARC64: 64 bits sparc
- NPY_CPU_S390: S390
- NPY_CPU_IA64: ia64
- NPY_CPU_PARISC: PARISC
New macros for CPU endianness has been added as well (see internal changes below for details):
- NPY_BYTE_ORDER: integer
- NPY_LITTLE_ENDIAN/NPY_BIG_ENDIAN defines
Those provide portable alternatives to glibc endian.h macros for platforms without it.
Portable NAN, INFINITY, etc...¶
npy_math.h now makes available several portable macro to get NAN, INFINITY:
- NPY_NAN: equivalent to NAN, which is a GNU extension
- NPY_INFINITY: equivalent to C99 INFINITY
- NPY_PZERO, NPY_NZERO: positive and negative zero respectively
Corresponding single and extended precision macros are available as well. All references to NAN, or home-grown computation of NAN on the fly have been removed for consistency.
Internal changes¶
numpy.core math configuration revamp¶
This should make the porting to new platforms easier, and more robust. In particular, the configuration stage does not need to execute any code on the target platform, which is a first step toward cross-compilation.
http://projects.scipy.org/numpy/browser/trunk/doc/neps/math_config_clean.txt
umath refactor¶
A lot of code cleanup for umath/ufunc code (charris).
Improvements to build warnings¶
Numpy can now build with -W -Wall without warnings
http://projects.scipy.org/numpy/browser/trunk/doc/neps/warnfix.txt
Separate core math library¶
The core math functions (sin, cos, etc... for basic C types) have been put into a separate library; it acts as a compatibility layer, to support most C99 maths functions (real only for now). The library includes platform-specific fixes for various maths functions, such as using those versions should be more robust than using your platform functions directly. The API for existing functions is exactly the same as the C99 math functions API; the only difference is the npy prefix (npy_cos vs cos).
The core library will be made available to any extension in 1.4.0.
CPU arch detection¶
npy_cpu.h defines numpy specific CPU defines, such as NPY_CPU_X86, etc... Those are portable across OS and toolchains, and set up when the header is parsed, so that they can be safely used even in the case of cross-compilation (the values is not set when numpy is built), or for multi-arch binaries (e.g. fat binaries on Max OS X).
npy_endian.h defines numpy specific endianness defines, modeled on the glibc endian.h. NPY_BYTE_ORDER is equivalent to BYTE_ORDER, and one of NPY_LITTLE_ENDIAN or NPY_BIG_ENDIAN is defined. As for CPU archs, those are set when the header is parsed by the compiler, and as such can be used for cross-compilation and multi-arch binaries.