SIMD Optimizations¶
NumPy provides a set of macros that define Universal Intrinsics to abstract out typical platform-specific intrinsics so SIMD code needs to be written only once. There are three layers:
Code is written using the universal intrinsic macros, with guards that will enable use of the macros only when the compiler recognizes them. In NumPy, these are used to construct multiple ufunc loops. Current policy is to create three loops: One loop is the default and uses no intrinsics. One uses the minimum intrinsics required on the architecture. And the third is written using the maximum set of intrinsics possible.
At compile time, a distutils command is used to define the minimum and maximum features to support, based on user choice and compiler support. The appropriate macros are overlayed with the platform / architecture intrinsics, and the three loops are compiled.
At runtime import, the CPU is probed for the set of supported intrinsic features. A mechanism is used to grab the pointer to the most appropriate function, and this will be the one called for the function.
Build options for compilation¶
--cpu-baseline: minimal set of required optimizations. Default value isminwhich provides the minimum CPU features that can safely run on a wide range of platforms within the processor family.--cpu-dispatch: dispatched set of additional optimizations. The default value ismax -xop -fma4which enables all CPU features, except for AMD legacy features(in case of X86).
The command arguments are available in build, build_clib, and
build_ext.
if build_clib or build_ext are not specified by the user, the arguments of
build will be used instead, which also holds the default values.
Optimization names can be CPU features or groups of features that gather several features or special options to perform a series of procedures.
The following tables show the current supported optimizations sorted from the lowest to the highest interest.
x86 - CPU feature names¶
Name |
Implies |
|---|---|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
x86 - Group names¶
Name |
Gather |
Implies |
|---|---|---|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
IBM/POWER big-endian - CPU feature names¶
Name |
Implies |
|---|---|
|
|
|
|
|
|
IBM/POWER little-endian - CPU feature names¶
Name |
Implies |
|---|---|
|
|
|
|
|
|
ARMv7/A32 - CPU feature names¶
Name |
Implies |
|---|---|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
ARMv8/A64 - CPU feature names¶
Name |
Implies |
|---|---|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
While the above tables are based on the GCC Compiler, the following tables showing the differences in the other compilers:
x86::Intel Compiler - CPU feature names¶
Name |
Implies |
|---|---|
|
|
|
|
|
|
Note
The following features aren’t supported by x86::Intel Compiler: XOP FMA4
x86::Microsoft Visual C/C++ - CPU feature names¶
Name |
Implies |
|---|---|
|
|
|
|
|
|
|
|
Note
The following features aren’t supported by x86::Microsoft Visual C/C++: AVX512_KNL AVX512_KNM
Special options¶
NONE: enable no featuresNATIVE: Enables all CPU features that supported by the currentmachine, this operation is based on the compiler flags (
-march=native, -xHost, /QxHost)
MIN: Enables the minimum CPU features that can safely run on a wide range of platforms:For Arch
Returns
x86SSESSE2x8664-bit modeSSESSE2SSE3IBM/POWERbig-endian modeNONEIBM/POWERlittle-endian modeVSXVSX2ARMHFNONEARM64AARCH64NEONNEON_FP16NEON_VFPV4ASIMDMAX: Enables all supported CPU features by the Compiler and platform.Operators-/+: remove or add features, useful with optionsMAX,MINandNATIVE.
NOTES¶
CPU features and other options are case-insensitive.
The order of the requsted optimizations doesn’t matter.
Either commas or spaces can be used as a separator, e.g.
--cpu-dispatch= “avx2 avx512f” or--cpu-dispatch= “avx2, avx512f” both work, but the arguments must be enclosed in quotes.The operand
+is only added for nominal reasons, For example:--cpu-baseline= "min avx2"is equivalent to--cpu-baseline="min + avx2".--cpu-baseline="min,avx2"is equivalent to--cpu-baseline`="min,+avx2"If the CPU feature is not supported by the user platform or compiler, it will be skipped rather than raising a fatal error.
Any specified CPU feature to
--cpu-dispatchwill be skipped if it’s part of CPU baseline featuresThe
--cpu-baselineargument force-enables implied features, e.g.--cpu-baseline=”sse42” is equivalent to--cpu-baseline=”sse sse2 sse3 ssse3 sse41 popcnt sse42”The value of
--cpu-baselinewill be treated as “native” if compiler native flag-march=nativeor-xHostorQxHostis enabled through environment variableCFLAGSThe validation process for the requsted optimizations when it comes to
--cpu-baselineisn’t strict. For example, if the user requestedAVX2but the compiler doesn’t support it then we just skip it and return the maximum optimization that the compiler can handle depending on the implied features ofAVX2, let us assumeAVX.The user should always check the final report through the build log to verify the enabled features.
Special cases¶
Interrelated CPU features: Some exceptional conditions force us to link some features together when it come to certain compilers or architectures, resulting in the impossibility of building them separately. These conditions can be divided into two parts, as follows:
Architectural compatibility: The need to align certain CPU features that are assured to be supported by successive generations of the same architecture, for example:
On ppc64le VSX(ISA 2.06) and VSX2(ISA 2.07) both imply one another since the first generation that supports little-endian mode is Power-8`(ISA 2.07)`
On AArch64 NEON FP16 VFPV4 ASIMD implies each other since they are part of the hardware baseline.
Compilation compatibility: Not all C/C++ compilers provide independent support for all CPU features. For example, Intel’s compiler doesn’t provide separated flags for AVX2 and FMA3, it makes sense since all Intel CPUs that comes with AVX2 also support FMA3 and vice versa, but this approach is incompatible with other x86 CPUs from AMD or VIA. Therefore, there are differences in the depiction of CPU features between the C/C++ compilers, as shown in the tables above.
Behaviors and Errors¶
Usage and Examples¶
Report and Trace¶
Understanding CPU Dispatching, How the NumPy dispatcher works?¶
NumPy dispatcher is based on multi-source compiling, which means taking a certain source and compiling it multiple times with different compiler flags and also with different C definitions that affect the code paths to enable certain instruction-sets for each compiled object depending on the required optimizations, then combining the returned objects together.
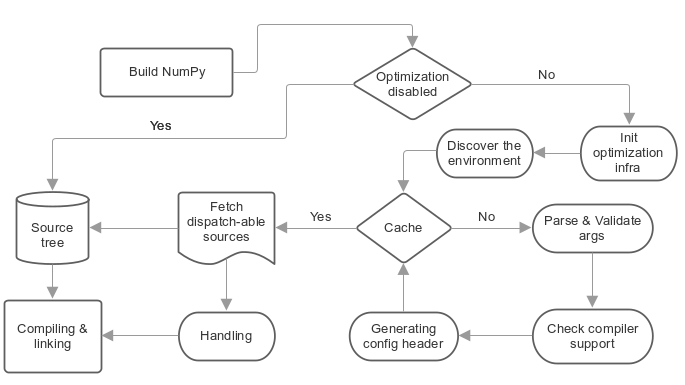
This mechanism should support all compilers and it doesn’t require any compiler-specific extension, but at the same time it is adds a few steps to normal compilation that are explained as follows:
1- Configuration¶
Configuring the required optimization by the user before starting to build the source files via the two command arguments as explained above:
--cpu-baseline: minimal set of required optimizations.--cpu-dispatch: dispatched set of additional optimizations.
2- Discovering the environment¶
In this part, we check the compiler and platform architecture and cache some of the intermediary results to speed up rebuilding.
3- Validating the requested optimizations¶
By testing them against the compiler, and seeing what the compiler can support according to the requested optimizations.
4- Generating the main configuration header¶
The generated header _cpu_dispatch.h contains all the definitions and
headers of instruction-sets for the required optimizations that have been
validated during the previous step.
It also contains extra C definitions that are used for defining NumPy’s
Python-level module attributes __cpu_baseline__ and __cpu_dispaٍtch__.
What is in this header?
The example header was dynamically generated by gcc on an X86 machine.
The compiler supports --cpu-baseline="sse sse2 sse3" and
--cpu-dispatch="ssse3 sse41", and the result is below.
// The header should be located at numpy/numpy/core/src/common/_cpu_dispatch.h
/**NOTE
** C definitions prefixed with "NPY_HAVE_" represent
** the required optimzations.
**
** C definitions prefixed with 'NPY__CPU_TARGET_' are protected and
** shouldn't be used by any NumPy C sources.
*/
/******* baseline features *******/
/** SSE **/
#define NPY_HAVE_SSE 1
#include <xmmintrin.h>
/** SSE2 **/
#define NPY_HAVE_SSE2 1
#include <emmintrin.h>
/** SSE3 **/
#define NPY_HAVE_SSE3 1
#include <pmmintrin.h>
/******* dispatch-able features *******/
#ifdef NPY__CPU_TARGET_SSSE3
/** SSSE3 **/
#define NPY_HAVE_SSSE3 1
#include <tmmintrin.h>
#endif
#ifdef NPY__CPU_TARGET_SSE41
/** SSE41 **/
#define NPY_HAVE_SSE41 1
#include <smmintrin.h>
#endif
Baseline features are the minimal set of required optimizations configured
via --cpu-baseline. They have no preprocessor guards and they’re
always on, which means they can be used in any source.
Does this mean NumPy’s infrastructure passes the compiler’s flags of baseline features to all sources?
Definitely, yes. But the dispatch-able sources are treated differently.
What if the user specifies certain baseline features during the build but at runtime the machine doesn’t support even these features? Will the compiled code be called via one of these definitions, or maybe the compiler itself auto-generated/vectorized certain piece of code based on the provided command line compiler flags?
During the loading of the NumPy module, there’s a validation step which detects this behavior. It will raise a Python runtime error to inform the user. This is to prevent the CPU reaching an illegal instruction error causing a segfault.
Dispatch-able features are our dispatched set of additional optimizations
that were configured via --cpu-dispatch. They are not activated by
default and are always guarded by other C definitions prefixed with
NPY__CPU_TARGET_. C definitions NPY__CPU_TARGET_ are only
enabled within dispatch-able sources.
5- Dispatch-able sources and configuration statements¶
Dispatch-able sources are special C files that can be compiled multiple
times with different compiler flags and also with different C
definitions. These affect code paths to enable certain
instruction-sets for each compiled object according to “the
configuration statements” that must be declared between a C
comment(/**/) and start with a special mark @targets at the
top of each dispatch-able source. At the same time, dispatch-able
sources will be treated as normal C sources if the optimization was
disabled by the command argument --disable-optimization .
What are configuration statements?
Configuration statements are sort of keywords combined together to determine the required optimization for the dispatch-able source.
Example:
/*@targets avx2 avx512f vsx2 vsx3 asimd asimdhp */
// C code
The keywords mainly represent the additional optimizations configured
through --cpu-dispatch, but it can also represent other options such as:
Target groups: pre-configured configuration statements used for managing the required optimizations from outside the dispatch-able source.
Policies: collections of options used for changing the default behaviors or forcing the compilers to perform certain things.
“baseline”: a unique keyword represents the minimal optimizations that configured through
--cpu-baseline
Numpy’s infrastructure handles dispatch-able sources in four steps:
(A) Recognition: Just like source templates and F2PY, the dispatch-able sources requires a special extension
*.dispatch.cto mark C dispatch-able source files, and for C++*.dispatch.cppor*.dispatch.cxxNOTE: C++ not supported yet.(B) Parsing and validating: In this step, the dispatch-able sources that had been filtered by the previous step are parsed and validated by the configuration statements for each one of them one by one in order to determine the required optimizations.
(C) Wrapping: This is the approach taken by NumPy’s infrastructure, which has proved to be sufficiently flexible in order to compile a single source multiple times with different C definitions and flags that affect the code paths. The process is achieved by creating a temporary C source for each required optimization that related to the additional optimization, which contains the declarations of the C definitions and includes the involved source via the C directive #include. For more clarification take a look at the following code for AVX512F :
/* * this definition is used by NumPy utilities as suffixes for the * exported symbols */ #define NPY__CPU_TARGET_CURRENT AVX512F /* * The following definitions enable * definitions of the dispatch-able features that are defined within the main * configuration header. These are definitions for the implied features. */ #define NPY__CPU_TARGET_SSE #define NPY__CPU_TARGET_SSE2 #define NPY__CPU_TARGET_SSE3 #define NPY__CPU_TARGET_SSSE3 #define NPY__CPU_TARGET_SSE41 #define NPY__CPU_TARGET_POPCNT #define NPY__CPU_TARGET_SSE42 #define NPY__CPU_TARGET_AVX #define NPY__CPU_TARGET_F16C #define NPY__CPU_TARGET_FMA3 #define NPY__CPU_TARGET_AVX2 #define NPY__CPU_TARGET_AVX512F // our dispatch-able source #include "/the/absuolate/path/of/hello.dispatch.c"
(D) Dispatch-able configuration header: The infrastructure generates a config header for each dispatch-able source, this header mainly contains two abstract C macros used for identifying the generated objects, so they can be used for runtime dispatching certain symbols from the generated objects by any C source. It is also used for forward declarations.
The generated header takes the name of the dispatch-able source after excluding the extension and replace it with ‘.h’, for example assume we have a dispatch-able source called hello.dispatch.c and contains the following:
// hello.dispatch.c /*@targets baseline sse42 avx512f */ #include <stdio.h> #include "numpy/utils.h" // NPY_CAT, NPY_TOSTR #ifndef NPY__CPU_TARGET_CURRENT // wrapping the dispatch-able source only happens to the addtional optimizations // but if the keyword 'baseline' provided within the configuration statments, // the infrastructure will add extra compiling for the dispatch-able source by // passing it as-is to the compiler without any changes. #define CURRENT_TARGET(X) X #define NPY__CPU_TARGET_CURRENT baseline // for printing only #else // since we reach to this point, that's mean we're dealing with // the addtional optimizations, so it could be SSE42 or AVX512F #define CURRENT_TARGET(X) NPY_CAT(NPY_CAT(X, _), NPY__CPU_TARGET_CURRENT) #endif // Macro 'CURRENT_TARGET' adding the current target as suffux to the exported symbols, // to avoid linking duplications, NumPy already has a macro called // 'NPY_CPU_DISPATCH_CURFX' similar to it, located at // numpy/numpy/core/src/common/npy_cpu_dispatch.h // NOTE: we tend to not adding suffixes to the baseline exported symbols void CURRENT_TARGET(simd_whoami)(const char *extra_info) { printf("I'm " NPY_TOSTR(NPY__CPU_TARGET_CURRENT) ", %s\n", extra_info); }
Now assume you attached hello.dispatch.c to the source tree, then the infrastructure should generate a temporary config header called hello.dispatch.h that can be reached by any source in the source tree, and it should contain the following code :
#ifndef NPY__CPU_DISPATCH_EXPAND_ // To expand the macro calls in this header #define NPY__CPU_DISPATCH_EXPAND_(X) X #endif // Undefining the following macros, due to the possibility of including config headers // multiple times within the same source and since each config header represents // different required optimizations according to the specified configuration // statements in the dispatch-able source that derived from it. #undef NPY__CPU_DISPATCH_BASELINE_CALL #undef NPY__CPU_DISPATCH_CALL // nothing strange here, just a normal preprocessor callback // enabled only if 'baseline' spesfied withiin the configration statments #define NPY__CPU_DISPATCH_BASELINE_CALL(CB, ...) \ NPY__CPU_DISPATCH_EXPAND_(CB(__VA_ARGS__)) // 'NPY__CPU_DISPATCH_CALL' is an abstract macro is used for dispatching // the required optimizations that specified within the configuration statements. // // @param CHK, Expected a macro that can be used to detect CPU features // in runtime, which takes a CPU feature name without string quotes and // returns the testing result in a shape of boolean value. // NumPy already has macro called "NPY_CPU_HAVE", which fit this requirment. // // @param CB, a callback macro that expected to be called multiple times depending // on the required optimizations, the callback should receive the following arguments: // 1- The pending calls of @param CHK filled up with the required CPU features, // that need to be tested first in runtime before executing call belong to // the compiled object. // 2- The required optimization name, same as in 'NPY__CPU_TARGET_CURRENT' // 3- Extra arguments in the macro itself // // By default the callback calls are sorted depending on the highest interest // unless the policy "$keep_sort" was in place within the configuration statements // see "Dive into the CPU dispatcher" for more clarification. #define NPY__CPU_DISPATCH_CALL(CHK, CB, ...) \ NPY__CPU_DISPATCH_EXPAND_(CB((CHK(AVX512F)), AVX512F, __VA_ARGS__)) \ NPY__CPU_DISPATCH_EXPAND_(CB((CHK(SSE)&&CHK(SSE2)&&CHK(SSE3)&&CHK(SSSE3)&&CHK(SSE41)), SSE41, __VA_ARGS__))
An example of using the config header in light of the above:
// NOTE: The following macros are only defined for demonstration purposes only. // NumPy already has a collections of macros located at // numpy/numpy/core/src/common/npy_cpu_dispatch.h, that covers all dispatching // and declarations scenarios. #include "numpy/npy_cpu_features.h" // NPY_CPU_HAVE #include "numpy/utils.h" // NPY_CAT, NPY_EXPAND // An example for setting a macro that calls all the exported symbols at once // after checking if they're supported by the running machine. #define DISPATCH_CALL_ALL(FN, ARGS) \ NPY__CPU_DISPATCH_CALL(NPY_CPU_HAVE, DISPATCH_CALL_ALL_CB, FN, ARGS) \ NPY__CPU_DISPATCH_BASELINE_CALL(DISPATCH_CALL_BASELINE_ALL_CB, FN, ARGS) // The preprocessor callbacks. // The same suffixes as we define it in the dispatch-able source. #define DISPATCH_CALL_ALL_CB(CHECK, TARGET_NAME, FN, ARGS) \ if (CHECK) { NPY_CAT(NPY_CAT(FN, _), TARGET_NAME) ARGS; } #define DISPATCH_CALL_BASELINE_ALL_CB(FN, ARGS) \ FN NPY_EXPAND(ARGS); // An example for setting a macro that calls the exported symbols of highest // interest optimization, after checking if they're supported by the running machine. #define DISPATCH_CALL_HIGH(FN, ARGS) \ if (0) {} \ NPY__CPU_DISPATCH_CALL(NPY_CPU_HAVE, DISPATCH_CALL_HIGH_CB, FN, ARGS) \ NPY__CPU_DISPATCH_BASELINE_CALL(DISPATCH_CALL_BASELINE_HIGH_CB, FN, ARGS) // The preprocessor callbacks // The same suffixes as we define it in the dispatch-able source. #define DISPATCH_CALL_HIGH_CB(CHECK, TARGET_NAME, FN, ARGS) \ else if (CHECK) { NPY_CAT(NPY_CAT(FN, _), TARGET_NAME) ARGS; } #define DISPATCH_CALL_BASELINE_HIGH_CB(FN, ARGS) \ else { FN NPY_EXPAND(ARGS); } // NumPy has a macro called 'NPY_CPU_DISPATCH_DECLARE' can be used // for forward declrations any kind of prototypes based on // 'NPY__CPU_DISPATCH_CALL' and 'NPY__CPU_DISPATCH_BASELINE_CALL'. // However in this example, we just handle it manually. void simd_whoami(const char *extra_info); void simd_whoami_AVX512F(const char *extra_info); void simd_whoami_SSE41(const char *extra_info); void trigger_me(void) { // bring the auto-gernreated config header // which contains config macros 'NPY__CPU_DISPATCH_CALL' and // 'NPY__CPU_DISPATCH_BASELINE_CALL'. // it highely recomaned to include the config header before exectuing // the dispatching macros in case if there's another header in the scope. #include "hello.dispatch.h" DISPATCH_CALL_ALL(simd_whoami, ("all")) DISPATCH_CALL_HIGH(simd_whoami, ("the highest interest")) // An example of including multiple config headers in the same source // #include "hello2.dispatch.h" // DISPATCH_CALL_HIGH(another_function, ("the highest interest")) }