Priorities¶
fname = "data/2021/numpy_survey_results.tsv"
column_names = [
'website', 'performance', 'reliability', 'packaging', 'new_features',
'documentation', 'other'
]
priorities_dtype = np.dtype({
"names": column_names,
"formats": ['U1'] * len(column_names),
})
data = np.loadtxt(
fname, delimiter='\t', skiprows=3, dtype=priorities_dtype,
usecols=range(58, 65), comments=None, encoding='UTF-16'
)
# Discard empty data
num_respondents = data.shape[0]
unstructured = data.view(np.dtype('(7,)U1'))
data = data[~np.any(unstructured == '', axis=1)]
glue('2021_num_prioritizers', gluval(data.shape[0], num_respondents), display=False)
We asked survey respondents to share their priorities for NumPy to get a sense of the needs/desires of the NumPy community. Users were asked to rank the following categories in order of priority:
for category in sorted(column_names[:-1]):
print(f" - {category.replace('_', ' ').capitalize()}")
- Documentation
- New features
- Packaging
- Performance
- Reliability
- Website
A write-in category (Other) was also included so that participants could
share priorities beyond those listed above.
Overview¶
Of the 522 survey participants, 362 (69%) shared their priorities for NumPy moving forward.
To get a sense of the overall relative “importance” of each of the categories, the following figure summarizes the score for each category as determined by the Borda counting procedure for ranked-choice voting.
# Unstructured, numerical data
raw = data.view(np.dtype('U1')).reshape(-1, len(column_names)).astype(int)
borda = len(column_names) + 1 - raw
relative_score = np.sum(borda, axis=0)
relative_score = 100 * relative_score / relative_score.sum()
# Prettify labels for plotting
labels = np.array([l.replace('_', ' ').capitalize() for l in column_names])
I = np.argsort(relative_score)
labels, relative_score = labels[I], relative_score[I]
fig, ax = plt.subplots(figsize=(12, 8))
ax.barh(np.arange(len(relative_score)), relative_score, tick_label=labels)
ax.set_xlabel('Relative Borda score (%)')
ax.set_title("Overall Importance Score");
fig.tight_layout()
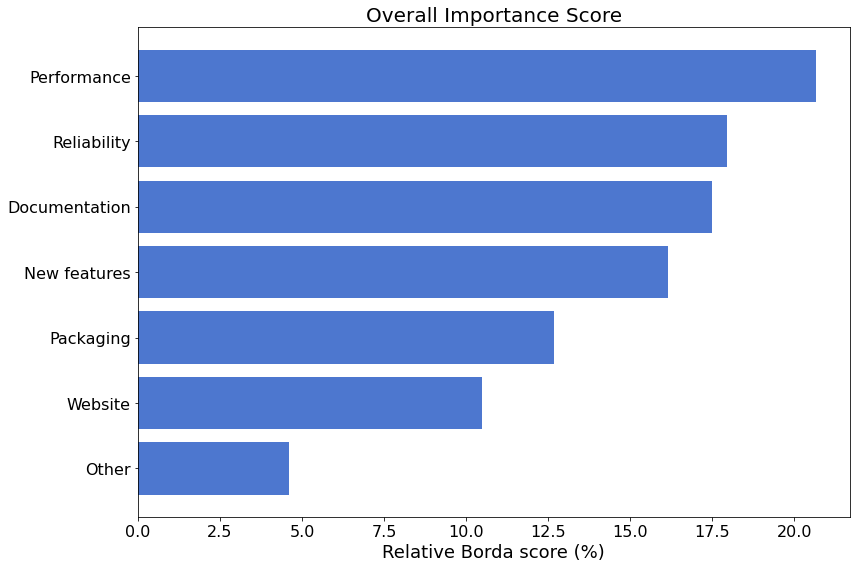
In Top Priorities we will take a closer look at how things are prioritized.
Top Priorities¶
The following figure shows the breakdown of the top priority items.
# Prettify labels for plotting
labels = np.array([l.replace('_', ' ').capitalize() for l in column_names])
# Collate top-priority data
cnts = np.sum(raw == 1, axis=0)
I = np.argsort(cnts)
labels, cnts = labels[I], cnts[I]
fig, ax = plt.subplots(figsize=(12, 8))
ax.barh(np.arange(cnts.shape[0]), 100 * cnts / cnts.sum(), tick_label=labels)
ax.set_title('Distribution of Top Priority')
ax.set_xlabel('Percent of Responses')
fig.tight_layout()
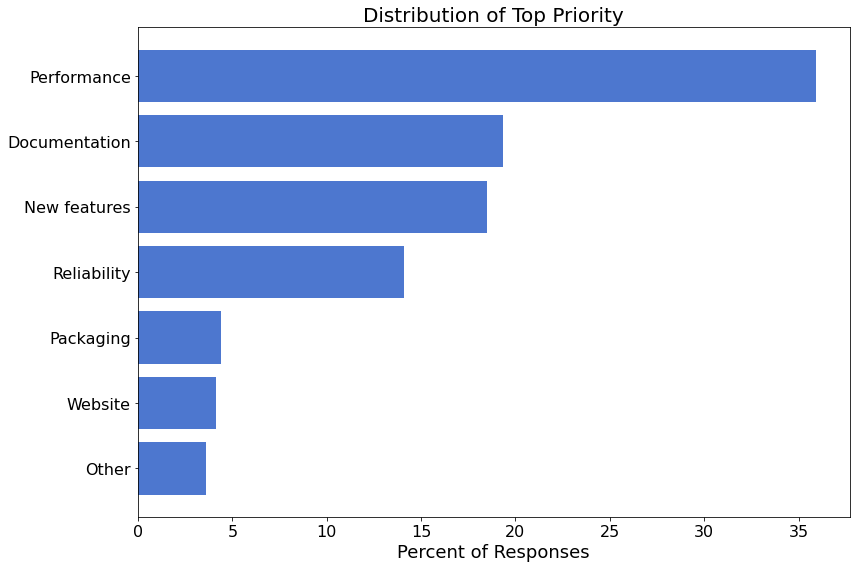
Details¶
We asked respondents who shared their priorities to provide specifics on their top two priorities. For example, if a user ranked “Performance” as a top priority, they were asked to share any specific thoughts on how performance could be improved. The responses for each of the categories are provided below.
categories = {
"docs", "newfeatures", "other", "packaging", "performance", "reliability",
"website",
}
# Load the text responses for each category
response_dict = {}
for category in categories:
responses = np.loadtxt(
f"data/2021/{category}_comments_master.tsv", delimiter='\t', skiprows=1,
usecols=0, dtype='U', comments=None
)
responses = responses[responses != '']
response_dict[category] = responses
# Generate nicely-formatted lists
for category, responses in response_dict.items():
gen_mdlist(responses, f"{category}_comments_list.md")
# Register number of responses in each category
for k, v in response_dict.items():
glue(f"2021_num_{k}_comments", v.shape[0], display=False)
Documentation¶
69 participants shared their thoughts on how documentation could be improved.
Click to expand!
Comments |
|---|
Recently I found out that documentation of matrix-multiplication-like functions is less than extensive |
Examples, examples everywhere! |
Share in more languages, here in latam we use a lot in research field, specially at universities. Create community events where people can propose new ways to do things. Numpy is more than just a library, it’s potential can connect research with software engineering. |
Documentation on your test cases would be nice. Other than that maybe some more examples on your docs |
More examples, tutorial. I’m not familiar with the deep mathematics of many algorithm, but often feel while reading the documentation, that a high level of mathematical knowledge is required besides the programming one to figure out how the given method should be used on what kind of data. |
More tutorials, how-to, cookbook, exemples |
The documentation is mostly clear. Some more usage examples for the methods would be welcomed. Often I find myself going to stackoverflow, or similar pages, in order to find usage examples, since the ones present in the documentation can sometimes be very limited. |
The survey forced me to select some priority order and hence I think performance, reliability and documentation are for my work the most important ones. In my experience numpy is fast, reliable and has clear documentation.” |
More advanced and complex examples. Tutorials for people without numerical math / programming background. |
Add more usage examples. Make some examples “with context”. For example how the operations are or can be used in the context. |
Keep it updated and add many examples |
Links in the documentation to tutorials and examples show off how powerful numpy is. I see all these crazy functions in the docs but as a novice, I’m not sure how or why I would use them. |
Better explanations. Namely, of algos, and friction points of beginner vs intermediate NumPy users (eg striding, handling batches, so on). |
examples using structured arrays |
Some parts of the documentation are old. |
The documentation is already good! But a little more communication about upcoming releases / roadmap for deprecations could be nice to have. |
Some documentation is little short for beginners and it took some time to understand the usage of certain methods, maybe a documentation with a ‘beginners mode’ containing easier description and lots of examples could help, however most of the times I find hints on stackoverflow. |
Use cases. (This comment was submitted in Japanese.) |
individual pages are normally quite good but the overall organization can be confusing at times. |
More examples in documentation. |
Examples and explanation. When is to correct to use one feature over another. How to make your numpy code faster. How to manage memory or system resources. How to use the GPU or parallelize calculations. |
Explain to to use Units for variables with the calculations.” |
Clean up documentation structure and cohesiveness |
More concrete examples. Tips and tricks. |
More explicit documentation, more detailed and provided examples. (This comment was submitted in French.) |
Can’t find a comprehensive list of all the functions and how their parameters work. The dir() function spews out hundreds of functions. Should be a PDF or website that documents each function with its parameters. Also group them by functionality. Ideally have examples. The pandas docs seem much better. |
code examples (also graphical), document every use case |
The documentation on dtype casting is incomplete and largely missing from the user guide. It would make NumPy more newcomer friendly to have the casting rules (including for assignments to an ndarray) explained clearly. Examples of some of the commonly unexpected casting behaviors should be included too. |
The user guide is missing examples of ndarrays with 0 in their shape. These show up quite a bit (at least in my experience), and broadcasting with them should be explained more clearly to newcomers. |
There are a lot of more-or-less redundant functions in NumPy. A section of the documentation containing NumPy idioms (or even a ‘cookbook’) would be helpful at clearing up things like when to use ravel vs. reshape(-1) vs. flatten(). |
Provide a comprehensive how-to on using NumPy for linear algebra manipulations on ndarrays. It’s a little tricky to figure out the mappings from normal linear algebra notation to 1d and 2d ndarray operations (e.g., adding a newaxis to form the outer product of two vectors represented as 1d ndarrays).” |
The documentation should be more detailed and well organized. |
When we look for information through a search engine we too often come across documents that do not correspond to the current version of Numpy; you would need a centralized doc corresponding to the most recent version (like what exists for Matlab for example). (This comment was submitted in French.) |
More examples and section-wise documentation will help learners |
Task focused tutorials/sample code. scikit-learn.org does this well. |
The documentation should explain how to write larger software with NumPy and not just some formulas. |
Write proper documentation that easy to read especially for students/beginners. |
More verbose with respect to examples and tutorials on top of the technicalities. |
Documentation recently has actually improved greatly! My selfish documentation/packaging interest is trying to determine how to properly include saved numpy/sparse matrices as part of a pip-installable library. |
More detailed examples and explanations, especially concerning Fourier transforms. |
help for conversion matlab to python” |
Ensure there are multiple examples per docstring and give more verbose descriptions. |
NumPy would benefit from user guides, like scikit-learn has. Guides that explain how to use tools to accomplish a task (instead of just code documentation) would make NumPy more approachable and invite kn new users (or inspire old users to use features in new ways). |
Expanding the documentation to register clearly the methods that are implemented, with their respective sources. |
Writing more examples of Numpy usage. |
eliminate “import numpy as np” |
add examples |
Add a few (more) quick-start and/or ‘how-to’ guides. Make sure that all sample code in the documentation is easily downloadable from the website. |
I have trouble finding the right methods for doing what I need to do |
Update docstrings and error messages to be clearer to interpret |
More concise API reference with aim to precisely present available routines and their syntax |
More sample code showing typical usage. |
Help programmers understand how to maximize their ways to get portable reproducible results and long term stability/repeatability/reproducibility of their programs. |
As an example, make it easier to find the release notes on the website (without need a Google search); make those notes clear, concise, and understandable to scientific domain experts that aren’t software engineers; and minimize the programming details they need to understand just to keep old programs running (distraction from their work).” |
As pointed out recently, the “User Guide” portion is a bit of a hodgepodge of unstructured material while much of the real user documentation is in the “API Reference”, which is pretty well-structured but ends up trying to do multiple jobs at once. |
We’re always in need of more docs, tutorials and blog posts with problem solving. |
use cases for numpy (ex: when to use std lib list for np.array()), curriculum for teaching numpy for beginners, |
The documentation hides implementation details and in particular tries to mask the interfaces to external codes, which is a major drawback. |
Enrichment of sample code. Japanese support for documents. (This comment was submitted in Japanese.) |
There are no instructions (that I found) on the Numpy docs referring to how to link Numpy against different backends. In some functions, keywords accepting strings referring to different methods are listed but not clearly explained. |
having more examples not as showing how api works but more of performance based examples and examples on how to leverage low level types which are there in numpy |
Tutorials with less expected academic knowledge |
Scalar types, scalar arrays, and C extensions |
- Discoverability of functions. Sometimes I know what I want to do but I don’t know what it might be called or what subpackage it might be in. Not sure how to solve this concretely. |
- Documentation of some functions is incomplete/ambiguous. I can’t give you a single thing you can do; it’d be slow, one-by-one effort” |
More application examples would be great. |
Use cases and general advertisement |
NumPy documentation is very good however, sometimes it would be nice to see more examples of particular function calls or references to external materials related to the content (e.g. Wikipedia pages) |
Basic documentation is good, but I would like more ultra-short examples for common (small) tasks |
New Features¶
50 participants shared their thoughts on new features to improve NumPy.
Click to expand!
Comments |
|---|
Not neccessarly I just only would like to see new features, a slight redesign of API would appeal to me, too, e.g. functions like numpy.apply_along_axis() I would prefer as methods for arrays as I believe it would make code more readable. |
Also, I would like to see some of the methods/functions existing in pandas, pandas.Dataframe.pipe() or pandas.Dataframe.first_valid_Index().” |
Export projects to different languages. (The comment was submitted in Spanish.) |
Support for Golang API |
Control (Transfer Functions) module, as Octave’s |
Add new features to the random module: MultiNormal test and Copulas” |
n-dimensional computational geometry |
Distributed computing |
Would be nice to implement more features for quantitative economics whilst continue to keep with competition (R, Matlab, …) with new features. |
I want to easily map a whole array |
More love for time series data manipulation. |
Parallel computing. (This comment was submitted in Mandarin.) |
Better handling of graphs, native sparse matrices. |
Nx2 arrays for computation geometry |
better image to numpy array tools (maybe together with opencv) |
Some pretty esoteric things relating to ufuncs on complex values |
NumPy must not stick only with Python but to extend their accessibility to other programming language also. |
It could benefit from more convenience features such as a one_hot function. |
Sampling from the generalised inverse gaussian distribution in numpy.random |
Tools for parallelization |
Hadamard matrix |
Customizable dtype system, new dtypes (e.g., complex32, bfloat16, etc.), improved support for typing, orthogonal ndarray indexing |
Not sure due to lack of experience but adding new features would be beneficial for programmers to use. |
Composable operations that behave like ufuncs and support in-place calculations. numexpr tried this some time ago but it is very limited. I often struggle with this when processing larger amounts of data with more complex computations. Moreover, masked operations could be expanded. |
More statistics |
In addition, the GPU mentioned above - I like to see more attractive printing options. In notebooks I am presenting, I tend to move data to pandas, even when not needed, because of the quality of the view. |
I don’t know :) I am usually gladly surprised when I see a new version. |
I’d likely to see more statistical methods in numpy, i.e., as those in SciPy. Or to be more correct, I’d like to see numpy’s speed in scipy. Or the other way around, i.e., nice to have numpy.var, numpy.std, but why not numpy.skew and numpy.kurtosis? |
Random specialized things like fast repeated matrix products (y =a@b@c@…@z where a-z are small square matrices), eigensolvers, least squared solvers, image processing |
Aggregation by group. (This comment was submitted in Japanese.) |
I would like to see a richer set of statistical features, such as ANOVA and multiple regression modeling. This is a common reason to have to port data over to R. |
better alignment with visualization libraries |
reduced row echelon form |
Native Rust interoperability |
- Make it easier to have custom dtypes (e.g. efficient string arrays, categorical arrays, columnar versions of structured arrays, etc). |
- Better Pandas interoperability (e.g. categorical arrays) |
- Ragged arrays” |
More cython interfaces. |
some random utils like equivalent of im2row from other languages |
* Method to identify null or None values, similar to Pandas.isnull() method. This will be helpful for masking/filtering. |
* Numpy.vectorize function can enhance good to great performance. Could we attain a real parallelization perhaps, similar to what Numba does (maybe I am asking too much) https://chelseatroy.com/2018/11/07/code-mechanic-numpy-vectorization/” |
Perhaps this already exists, but I would like to see some methods for generating slices from a 3D array at a user specified orientation. |
Shifting C backend templating to C++ templates. |
Distributed computation. |
Plugins/extensions as external Python libraries “ |
Ability to handle large data |
Adding new datatypes like ibm floats would be nice. Adding lazy evaluation out of the box would be also nice to have. |
I will have to use Numpy more extensively for that. |
Extensibility with dtypes and gufuncs |
Autodiff |
Other¶
9 participants selected “Other” as a top priority:
Click to expand!
Comments |
|---|
I would like the documentation to be more explicit and less reliant on jargon. Especially from the point of view of a novice/hobby programmer this would be such a great deal. |
Adding support for GPU and parallel operations would be great. |
My understanding is that work is underway to make APIs across the python scientific ecosystem consistent. I think getting the components to gel and work well with each other is high priority. |
NEP-35 style work - making it easier to work with dask and cupy |
On-ramping more under-represented people to contribute to the codebase. |
Integration with other languages by providing low level C library |
Continue with the deprecations and do an extensive code cleanup removing things rarely used to make a leaner codebase aiming to build numpy as a solid core for other applications. |
I think numpy plays a huge role as the central hub for python arrays. In that vein I think a high priority is improving the interop interface so other libraries can Just Work with numpy. This includes things like e.g. pushing forward with the HPy project to modernize the C interface. |
And of course, the numpy community still has plenty to do to improve equity and inclusion in the organization (and pydata in general)!” |
Packaging¶
13 participants shared their thoughts on how the packaging utilities in NumPy could be improved.
Click to expand!
Comments |
|---|
Compiling Numpy without using a package manager is a pretty daunting task, a least the last time I tried. |
Provide wheels for all architectures and interpreters possible |
Move away from numpy distutils. Improve ci and fix issues related to the support of new ishhardware (eg arm64 on linux and apple m1). |
Maybe explore the use of reproducible builds to improve security and limit the risk of shipping binaries tempered with compiler rootkits on pypi or conda-forge.” |
Sometimes numpy can be hard to install - especially on systems that do not have their own compilers. I’ve tried installing on windows and gotten confusing error messages that I later learned were because I didn’t have compiler settings created correctly. And once (a long time ago) on Linux, I needed to install system headers. I think less technical users having to resort to Anaconda to install a Python package is not a good user experience. |
Simple way to rebuild your package, once installed, (e.g. a script like “python -m numpy rebuild –library IntelMKL –options FMA”). |
More clear about the fact that the underlying BLAS/LAPACK could be from different sources in the docs! I spent days asking of meep/tensorflow alternatively ruining my numpy installation by imposing their version and me not understanding why” |
The current system is a bit of an archaic mess, with somewhat public APIs with poor documentation. Also, with distutils going away in Python 3.12, it’s an area that likely matters. Refactoring and simplifying the packaging system, and either depending on external tools (like setuptools, scikit-build, or other) or factoring out the build system into a separate package could greatly help. Also it needs documentation (such as on how to build a FORTRAN extension, for example). |
Numpy should be available linked against the Intel MKL for Windows systems such as the wheels distribute in the Gohlke repo. This would massively simplify maintenance of project that highly depend on the speed provided by Numpy+MKL. |
continued focus on helping keep (making it easy to keep) distros’ numpy packages up to date |
Packaging had improved over the years, but installing on Microsoft Windows must become even more transparent. |
All my answers are about keeping up what currently there is |
Better release information |
Performance¶
72 participants shared thoughts on why performance is a top priority and ideas on how it can be improved.
Click to expand!
Comments |
|---|
Allowing Numpy to access to GPU to parallel tasks |
It’s already pretty good, I don’t know how it can get better |
I mean this as “performance should be a top priority”. numpy already performs well- I think this should continue to be a priority. |
Specifically, performance on windows, though I’m not sure if this is feasible. |
The performance is mostly great. The survey forced me to select some priority order and hence I think performance, reliability and documentation are for my work the most important ones. In my experience numpy is fast, reliable and has clear documentation. |
Solicit algorithm optimization from the public. (The comment was made in Mandarin.) |
Paralelization. Tutorial on best practices. Advanced tutorials on numexpr and numba. |
Enabling the multi-threading via env variables for a ML stack consisting of NumPy, SciPy, SciKit-Learn and other higher-level libraries is very tricky in a production codebase (setting the env variable before NumPy is first imported etc.) and currently doesn’t work for our codebase at all (while it works on a trivial PoC code snippet). Detection and exclusion of hyper-threaded cores is missing. Dynamic vs. static thread count setting has undocumented but significant impact. All this matters in on-premise deployments a lot. |
Nothing to complain, but I highly value numpys performance |
There’s still a lot of Numpy code that could probably be easily multi-threaded, which would give a huge performance improvement on a lot of my code. I know that there are dedicated libraries out there but that significantly complicates installation and maintenance (in particular within companies with brain-dead download policies), therefore I try to keep imports to a minimum. |
multicore support for basic operations would be nice |
CUDA support. Support for AMD’s BLAS |
Using GPU and parallelisation |
In terms of speed Numpy is amazing, maybe I am more concerned in terms of RAM consumption, specifically for a numpy masked array |
Vector operation related. (The comment was made in Japanese.) |
Continue honing the low-level (C) code. |
Join forces with projects like JAX and Dask. Develop better interoperability with modern Fortran through f2py or LFortran. |
Developing NumPy for developers from underdeveloped countries. Developers from economically underdeveloped counties have less high powered PC configuration, thus creating NumPy to run on lower PC config. with high performance will be helpful for them. |
I think documentation on how to write faster numpy code would be helpful: vectorizing, etc. Add the ability to use units with calculations. |
Performance on Windows is worse than on Linux on the same computer |
Using SIMD code to leverage hardware vectorization. |
better facilities for using numpy with GPU’s/CUDA |
Reduce overhead |
make it faster |
Provide a min/max method to compute min/max in one go rather than from min and then max. |
How much processing can be handled in small computers and big data without implying the need of costly GPUs, memory/processors |
Developing smaller modules that allow a faster response in calculations. (The comment was made in Spanish.) |
Allow for multiprocessing without being more verbose. |
Numpy could use extended instruction sets or target GPU. |
When applying arbitrary Python code with broadcast. (The comment was made in Japanese.) |
Performance is good now but one of the main reasons I use |
Multi node MKL |
Ya guys r doing fine… just don’t change the syntax…. let it last as pristine as possible |
Spreading more in the Spanish language, sorry if I’m selfish! (The comment was made in Spanish.) |
CuPy being native so that large arrays, which run slow for me, which is probably a CPU issue, not a numpy issue. Though added GPU support would be fantastic. |
Make improvement in calculation speed. Some people from my field move to Julia because of that |
I’d love to have integrated profiling tools, giving hits to bottlenecks in matrix operations and suggesting alternatives. And a closer integration with Numba would be very nice too! |
SIMD instructions for modern processors (as you have been doing), more ambitiously, processing backends such as OpenCL and Vulkan. |
Numpy is the fundamental toolbox on almost thousands of software development chaintool. If some functionality can be improved to run faster, it will have tremendous implications in a vast array of applications. |
None in particular, but any performance gain can have huge impacts. |
There are functions such as np.unique that are incompatible with numba, so I want a function with narrowed functions. (The comment was made in Japanese.) |
Improve call overhead |
Enhanced vectorization, multithreaded/SIMD map feature |
- More use of SIMD operations - Maybe some integration with Numba for automatic “fusion” of operations? Not sure about this one… |
Automated performance tests. Perhaps some way of improving performance for the vectorize function if that is at all possible. |
Profile memory and report CPU and memory usage with VTune. |
Improve GPU support. |
Would love anything I can get to make my code faster ;) |
Honestly, numpy is amazingly performant. Could the overhead of talking with python be cut down somehow? |
I don’t think there are any easy answers. Supporting and pushing projects that make use of DAG and JIT is probably the best way forward. The challenge here is tht this is really outside of core NumPy. |
Better integration with CuPy (GPU), multithreaded computation, accessible options for tailoring your personal build (CPU architecture, BLAS library….) ideally with one simple and easy to use script to rebuild the package. Support for float16 |
Native optimizations for the Apple M1 chip |
Actually more docs on performance would be cool |
Extra compiled routines for a few key operations (like 2D regular binned histograms, AKA images). Mostly this is just something to keep in a priority list, since som many people depend on NumPy for compute-intensive codes. |
Operations on masked arrays can be pretty slow. |
I guess I don’t think NumPy underperforms, I just would like to see it do an even more awesome job. My models involve a lot of applying finite difference methods to PDEs and running them 10^6 times so any bit of performance helps! |
Vectorising all the APIs, universal function support. |
This is tough. I cannot think of anything off the top of my head, since NumPy is rather well designed in most aspects. |
Magically make my existing numpy code faster 🙂 |
Further weight reduction and speeding up of processing. (The comment was made in Japanese.) |
It’s already pretty good, but its main weak point is that it produces intermediate arrays—any tricks that can lead to more operator-fusion is appreciated! |
better support for AMD processors |
something like what julia is currently doing with llvm and simd |
Further JAX integration. Also with Scipy |
Some operations could take advantage of fusing of operators and this improve memory bandwidth of the code |
It can be improved if there are multiple people working at the maintainance of NumPy from wide range of knowledge and interests. |
- Optional TensorFlowesque chaining of operations to save memory bandwidth - Bespoke low-level code optimized to major architectures - Ability to offload code to accelerators (e.g. GPU), especially if this can be done in a way that’s transparent to the user |
Device placement |
Numpy is already very high performance, but performance matters a lot to me. I use numpy because the apis are great and I rarely have to think about performance. |
Most of my APIs import it, and therefore any improvements to imports will have a broad impact on my projects’ import times |
I would like an easy user story with GPU and multi-core setups. |
User-extendable dtypes |
Reliability¶
58 participants shared their thoughts on reliability and how it can be improved.
Click to expand!
Comments |
|---|
More than increasing it I was thinking in keeping it reliable. |
Ensure the API is backward-compatible. |
I think that numpy is reliable and this should continue to be a priority. |
Numpy is pretty reliable already, I just needed a second choice |
Added missing warning information and optimized for multi-threading. (This commend was made in Mandarin.) |
Several times (in 2020 and 2021) we had to pin an older version of NumPy in our requirements.txt because it was broken on Windows. We are packaging our on-premise variant of production code both for Linux and Windows. Such pinning may impact the dependent ML libraries in a hard to predict way and is a source of wasted time. |
Nothing to complain, but I highly value numpys reliability |
Make the Numpy API sustainable over time. |
Many scientific projects use it. (This commend was made in French.)” |
I’m not sure, but this is something to keep in check before it’s necessary |
Automated performance regression. See e.g ticket https://github.com/numpy/numpy/issues/18607 |
standard tests provided for each package to benchmark on our computers |
Less breaking changes |
Some statistical functions (e.g. quantile) does not seem to be 100% reliable. I am a bit concerned about the veracity & the precision of the results. |
I am aware that doing new stuff is cool, but I believe it would be amazing if a lot of efforts could be done to improve the reliability of the current Numpy functions. |
Most scientific programing (e.g. Scipy) relies on the precision and base functionality of Numpy, that’s why I believe reliability is critical. And benchmarks are not good: https://www.stochasticlifestyle.com/wp-content/uploads/2019/11/de_solver_software_comparsion.pdf” |
- Allow NaNs in integer arrays. |
- Find ways to ease the discomfort of using datetimes.” |
Better CI coverage. Use type hints to do static linting. |
It’s great, I just think that other stuff are of lower priority. |
Prioritizing reliability means that I value it more than having new features developed. |
Long term stability, avoid breaking changes |
Not aware of errors in it. Publish test cases and regression code. |
Simply keep numpy stable and reliable as it’s the core of many projects. |
Striving for excellent, trusted performance; bug or oversight related issue free. |
Make sparsity a first class concept |
As with performance, reliability is good now, but one of the main reasons I use |
Numpy never failed me but I understand it’s a lot of work to keep it running. |
Numpy is already very reliable! I believe some kind of visual introspection tool would be a nice addition, helping to address some of the “black box” problem of having dense Linear Algebra code that does not work as expected, helping the programmer to find mistakes made. |
For the same reason as before, the library is a fundamental cornerstone of several different tool packages for scientific and engineering, and it is of utmost importance that it provide the right answers. |
I have had issues with IIRC linear algebra on very large matrixes. I think there was something about least squared equation solving where I had to implement pieces by myself. Otherwiae, more useful error messages |
installing numpy is not really robust. I would love that to be fixed for all platforms |
Providing comparisons where the same results are obtained using Numpy and other tools (e.g., Matlab). |
Keep on with addressing bug reports, revieing PRs that fix bugs. |
Reduce and remove features by carving out non-core functionality into plugin modules and jettisoning them. Advanced software engineering training for core contributors. Analysis of defect-injection sites and processes. |
Systematic testing. It is currently rather ad hoc. |
No specifics. It is just something I know I care about - knowing that if I use a numpy calculation (that I can’t check myself) that it will be right. |
More automated tests of various platforms. |
I have no specific suggestions. My organization relies heavily on the reliability of the software we use. I suspect this is the case for many other users. Please never sacrifice reliability/integrity in favor of “new features.” The platform must be as rock-solid as possible. |
No need for oldest-supported-numpy package |
Focus on stability and fixing bugs, rather than adding new features. |
Fewer “surprises”. Maybe this really falls under better documentation. |
* Reduce existing bugs or caveats. |
* Consistency of API interfaces. Deprecate those interfaces that will result in confusion among the users.” |
Work on enabling portable reproducibility of the computed results and long term stability/repeatability/reproducibility for code snapshots that go with published scientific papers. |
I don’t have any ideas, just feel making sure the library is reliable is important. |
There are a lot of open issues on github, that might help. Also, i’ve sometimes encountered strange behaviours when reaching memory limits, but not sure if a lot can be done there. |
Just the healthy backlog of bugs |
We use numpy in our medical devices, having numpy behave in a reliable way makes it easier to upgrade to benefit from bug fixes, packaging or performance improvements without breaking existing code |
It’s already pretty good, but as a foundational library, reliability takes precedence over other things, like new features. |
The amount of numpy dependencies is huge. Do not break anything for as long as you can! |
continued focus on crash-free code with consistent results across platforms |
I don’t have any specific complaints, numpy is very reliable. Maintaining that is more important to me than some of the other items so I listed it above them. |
NumPy is generally very reliable, just I think the reliability is a must for a numerical library. Just please keep doing your excellent work :) |
Numpy has amazing apis and already covers most functionality I want to use. If it’s also super fast and super reliable, it becomes basically the best numeric library out there. |
Reliability is actually quite good; please continue to prioritize it |
An exhaustive test suit covering almost all aspects of Numpy can be developed. This can be used as a benchmark of Numpy reliability. |
It’s not about increasing, but to maintain its current reliability, performance, etc. |
Website¶
Finally, 9 participants selected the NumPy website as a top priority and shared their thoughts on how it could be improved.
Click to expand!
Comments |
|---|
User friendly UI |
The site should be better referenced and you should get there faster when you use a search engine to answer a question. |
Not sure, but something like “you might also interested in xxx” would help! Sometimes when I try to do something I never did I end up discovering that there’s an easy and straightforward way to do it, but it takes me forever to find out |
Front End… Try to make it user friendly |
More content in Spanish please. |
Even more examples and tutorials. |
Even more examples! |
I have trouble finding the right methods for doing what I need to do. |
Tutorials |
Summary¶
The following figure shows the relative frequency of selection for each of the listed categories1 at each priority level.
fig, axes = plt.subplots(3, 2, figsize=(12, 8))
for i, ax in enumerate(axes.ravel()):
priority_level = i + 1
cnts = np.sum(raw == priority_level, axis=0)[I]
ax.barh(np.arange(cnts.shape[0]), 100 * cnts / cnts.sum(), tick_label=labels)
ax.set_title(f"Priority: {priority_level}")
fig.tight_layout()
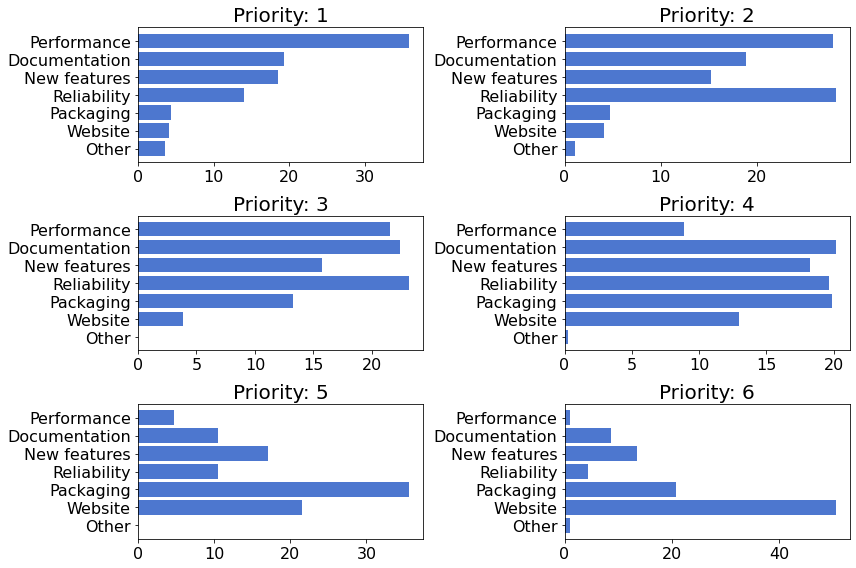
- 1
Excluding
Other, which was an optional category and therefore constitutes the majority of the “lowest-priority”.