
Analyzing the impact of the lockdown on air quality in Delhi, India#

What you’ll do#
Calculate Air Quality Indices (AQI) and perform paired Student’s t-test on them.
What you’ll learn#
You’ll learn the concept of moving averages
You’ll learn how to calculate Air Quality Index (AQI)
You’ll learn how to perform a paired Student’s t-test and find the
tandpvaluesYou’ll learn how to interpret these values
What you’ll need#
SciPy installed in your environment
Basic understanding of statistical terms like population, sample, mean, standard deviation etc.
The problem of air pollution#
Air pollution is one of the most prominent types of pollution we face that has an immediate effect on our daily lives. The COVID-19 pandemic resulted in lockdowns in different parts of the world; offering a rare opportunity to study the effect of human activity (or lack thereof) on air pollution. In this tutorial, we will study the air quality in Delhi, one of the worst affected cities by air pollution, before and during the lockdown from March to June 2020. For this, we will first compute the Air Quality Index for each hour from the collected pollutant measurements. Next, we will sample these indices and perform a paired Student’s t-test on them. It will statistically show us that the air quality improved due to the lockdown, supporting our intuition.
Let’s start by importing the necessary libraries into our environment.
import numpy as np
from numpy.random import default_rng
from scipy import stats
Building the dataset#
We will use a condensed version of the Air Quality Data in India dataset. This dataset contains air quality data and AQI (Air Quality Index) at hourly and daily level of various stations across multiple cities in India. The condensed version available with this tutorial contains hourly pollutant measurements for Delhi from May 31, 2019 to June 30, 2020. It has measurements of the standard pollutants that are required for Air Quality Index calculation and a few other important ones: Particulate Matter (PM 2.5 and PM 10), nitrogen dioxide (NO2), ammonia (NH3), sulfur dioxide (SO2), carbon monoxide (CO), ozone (O3), oxides of nitrogen (NOx), nitric oxide (NO), benzene, toluene, and xylene.
Let’s print out the first few rows to have a glimpse of our dataset.
! head air-quality-data.csv
Datetime,PM2.5,PM10,NO2,NH3,SO2,CO,O3,NOx,NO,Benzene,Toluene,Xylene
2019-05-31 00:00:00,103.26,305.46,94.71,31.43,30.16,3.0,18.06,178.31,152.73,13.65,83.47,2.54
2019-05-31 01:00:00,104.47,309.14,74.66,34.08,27.02,1.69,18.65,106.5,79.98,11.35,76.79,2.91
2019-05-31 02:00:00,90.0,314.02,48.11,32.6,18.12,0.83,28.27,48.45,25.27,5.66,32.91,1.59
2019-05-31 03:00:00,78.01,356.14,45.45,30.21,16.78,0.79,27.47,44.22,21.5,3.6,21.41,0.78
2019-05-31 04:00:00,80.19,372.9,45.23,28.68,16.41,0.76,26.92,44.06,22.15,4.5,23.39,0.62
2019-05-31 05:00:00,83.59,389.97,39.49,27.71,17.42,0.76,28.71,39.33,21.04,3.25,23.59,0.56
2019-05-31 06:00:00,79.04,371.64,39.61,26.87,16.91,0.84,29.26,43.11,24.37,3.12,15.27,0.46
2019-05-31 07:00:00,77.32,361.88,42.63,27.26,17.86,0.96,27.07,48.22,28.81,3.32,14.42,0.41
2019-05-31 08:00:00,84.3,377.77,42.49,28.41,20.19,0.98,33.05,48.22,27.76,3.4,14.53,0.4
For the purpose of this tutorial, we are only concerned with standard pollutants required for calculating the AQI, viz., PM 2.5, PM 10, NO2, NH3, SO2, CO, and O3. So, we will only import these particular columns with np.loadtxt. We’ll then slice and create two sets: pollutants_A with PM 2.5, PM 10, NO2, NH3, and SO2, and pollutants_B with CO and O3. The
two sets will be processed slightly differently, as we’ll see later on.
pollutant_data = np.loadtxt("air-quality-data.csv", dtype=float, delimiter=",",
skiprows=1, usecols=range(1, 8))
pollutants_A = pollutant_data[:, 0:5]
pollutants_B = pollutant_data[:, 5:]
print(pollutants_A.shape)
print(pollutants_B.shape)
(9528, 5)
(9528, 2)
Our dataset might contain missing values, denoted by NaN, so let’s do a quick check with np.isfinite.
np.all(np.isfinite(pollutant_data))
np.True_
With this, we have successfully imported the data and checked that it is complete. Let’s move on to the AQI calculations!
Calculating the Air Quality Index#
We will calculate the AQI using the method adopted by the Central Pollution Control Board of India. To summarize the steps:
Collect 24-hourly average concentration values for the standard pollutants; 8-hourly in case of CO and O3.
Calculate the sub-indices for these pollutants with the formula:
\[ Ip = \dfrac{\text{IHi – ILo}}{\text{BPHi – BPLo}}\cdot{\text{Cp – BPLo}} + \text{ILo} \]Where,
Ip= sub-index of pollutantp
Cp= averaged concentration of pollutantp
BPHi= concentration breakpoint i.e. greater than or equal toCp
BPLo= concentration breakpoint i.e. less than or equal toCp
IHi= AQI value corresponding toBPHi
ILo= AQI value corresponding toBPLoThe maximum sub-index at any given time is the Air Quality Index.
The Air Quality Index is calculated with the help of breakpoint ranges as shown in the chart below.
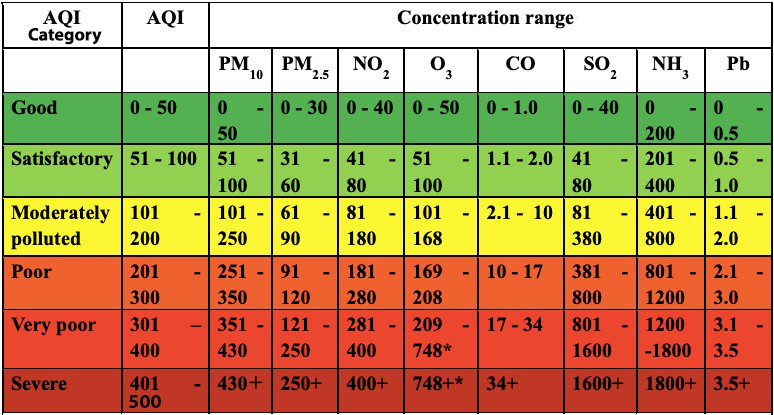
Let’s create two arrays to store the AQI ranges and breakpoints so that we can use them later for our calculations.
AQI = np.array([0, 51, 101, 201, 301, 401, 501])
breakpoints = {
'PM2.5': np.array([0, 31, 61, 91, 121, 251]),
'PM10': np.array([0, 51, 101, 251, 351, 431]),
'NO2': np.array([0, 41, 81, 181, 281, 401]),
'NH3': np.array([0, 201, 401, 801, 1201, 1801]),
'SO2': np.array([0, 41, 81, 381, 801, 1601]),
'CO': np.array([0, 1.1, 2.1, 10.1, 17.1, 35]),
'O3': np.array([0, 51, 101, 169, 209, 749])
}
Moving averages#
For the first step, we have to compute moving averages for pollutants_A over a window of 24 hours and pollutants_B over a
window of 8 hours. We will write a simple function moving_mean using np.cumsum and sliced indexing to achieve this.
To make sure both the sets are of the same length, we will truncate the pollutants_B_8hr_avg according to the length of
pollutants_A_24hr_avg. This will also ensure we have concentrations for all the pollutants over the same period of time.
def moving_mean(a, n):
ret = np.cumsum(a, dtype=float, axis=0)
ret[n:] = ret[n:] - ret[:-n]
return ret[n - 1:] / n
pollutants_A_24hr_avg = moving_mean(pollutants_A, 24)
pollutants_B_8hr_avg = moving_mean(pollutants_B, 8)[-(pollutants_A_24hr_avg.shape[0]):]
Now, we can join both sets with np.concatenate to form a single data set of all the averaged concentrations. Note that we have to join our arrays column-wise so we pass the
axis=1 parameter.
pollutants = np.concatenate((pollutants_A_24hr_avg, pollutants_B_8hr_avg), axis=1)
Sub-indices#
The subindices for each pollutant are calculated according to the linear relationship between the AQI and standard breakpoint ranges with the formula as above:
The compute_indices function first fetches the correct upper and lower bounds of AQI categories and breakpoint concentrations for the input concentration and pollutant with the help of arrays AQI and breakpoints we created above. Then, it feeds these values into the formula to calculate the sub-index.
def compute_indices(pol, con):
bp = breakpoints[pol]
if pol == 'CO':
inc = 0.1
else:
inc = 1
if bp[0] <= con < bp[1]:
Bl = bp[0]
Bh = bp[1] - inc
Ih = AQI[1] - inc
Il = AQI[0]
elif bp[1] <= con < bp[2]:
Bl = bp[1]
Bh = bp[2] - inc
Ih = AQI[2] - inc
Il = AQI[1]
elif bp[2] <= con < bp[3]:
Bl = bp[2]
Bh = bp[3] - inc
Ih = AQI[3] - inc
Il = AQI[2]
elif bp[3] <= con < bp[4]:
Bl = bp[3]
Bh = bp[4] - inc
Ih = AQI[4] - inc
Il = AQI[3]
elif bp[4] <= con < bp[5]:
Bl = bp[4]
Bh = bp[5] - inc
Ih = AQI[5] - inc
Il = AQI[4]
elif bp[5] <= con:
Bl = bp[5]
Bh = bp[5] + bp[4] - (2 * inc)
Ih = AQI[6]
Il = AQI[5]
else:
print("Concentration out of range!")
return ((Ih - Il) / (Bh - Bl)) * (con - Bl) + Il
We will use np.vectorize to utilize the concept of vectorization. This simply means we don’t have loop over each element of the pollutant array ourselves. Vectorization is one of the key advantages of NumPy.
vcompute_indices = np.vectorize(compute_indices)
By calling our vectorized function vcompute_indices for each pollutant, we get the sub-indices. To get back an array with the original shape, we use np.stack.
sub_indices = np.stack((vcompute_indices('PM2.5', pollutants[..., 0]),
vcompute_indices('PM10', pollutants[..., 1]),
vcompute_indices('NO2', pollutants[..., 2]),
vcompute_indices('NH3', pollutants[..., 3]),
vcompute_indices('SO2', pollutants[..., 4]),
vcompute_indices('CO', pollutants[..., 5]),
vcompute_indices('O3', pollutants[..., 6])), axis=1)
Air quality indices#
Using np.max, we find out the maximum sub-index for each period, which is our Air Quality Index!
aqi_array = np.max(sub_indices, axis=1)
With this, we have the AQI for every hour from June 1, 2019 to June 30, 2020. Note that even though we started out with the data from 31st May, we truncated that during the moving averages step.
Paired Student’s t-test on the AQIs#
Hypothesis testing is a form of descriptive statistics used to help us make decisions with the data. From the calculated AQI data, we want to find out if there was a statistically significant difference in average AQI before and after the lockdown was imposed. We will use the left-tailed, paired Student’s t-test to compute two test statistics- the t statistic and the p value. We will then compare these with the corresponding critical values to make a decision.

Sampling#
We will now import the datetime column from our original dataset into a datetime64 dtype array. We will use this array to index the AQI array and obtain subsets of the dataset.
datetime = np.loadtxt("air-quality-data.csv", dtype='M8[h]', delimiter=",",
skiprows=1, usecols=(0, ))[-(pollutants_A_24hr_avg.shape[0]):]
Since total lockdown commenced in Delhi from March 24, 2020, the after-lockdown subset is of the period March 24, 2020 to June 30, 2020. The before-lockdown subset is for the same length of time before 24th March.
after_lock = aqi_array[np.where(datetime >= np.datetime64('2020-03-24T00'))]
before_lock = aqi_array[np.where(datetime <= np.datetime64('2020-03-21T00'))][-(after_lock.shape[0]):]
print(after_lock.shape)
print(before_lock.shape)
(2376,)
(2376,)
To make sure our samples are approximately normally distributed, we take samples of size n = 30. before_sample and after_sample are the set of random observations drawn before and after the total lockdown. We use random.Generator.choice to generate the samples.
rng = default_rng()
before_sample = rng.choice(before_lock, size=30, replace=False)
after_sample = rng.choice(after_lock, size=30, replace=False)
Defining the hypothesis#
Let us assume that there is no significant difference between the sample means before and after the lockdown. This will be the null hypothesis. The alternative hypothesis would be that there is a significant difference between the means and the AQI improved. Mathematically,
\(H_{0}: \mu_\text{after-before} = 0\)
\(H_{a}: \mu_\text{after-before} < 0\)
Calculating the test statistics#
We will use the t statistic to evaluate our hypothesis and even calculate the p value from it. The formula for the t statistic is:
where,
\(\mu_\text{after-before}\) = mean differences of samples
\(\sigma^{2}\) = variance of mean differences
\(n\) = sample size
def t_test(x, y):
diff = y - x
var = np.var(diff, ddof=1)
num = np.mean(diff)
denom = np.sqrt(var / len(x))
return np.divide(num, denom)
t_value = t_test(before_sample, after_sample)
For the p value, we will use SciPy’s stats.distributions.t.cdf() function. It takes two arguments- the t statistic and the degrees of freedom (dof). The formula for dof is n - 1.
dof = len(before_sample) - 1
p_value = stats.distributions.t.cdf(t_value, dof)
print("The t value is {} and the p value is {}.".format(t_value, p_value))
The t value is -11.257207138594937 and the p value is 2.1045046602069924e-12.
What do the t and p values mean?#
We will now compare the calculated test statistics with the critical test statistics. The critical t value is calculated by looking up the t-distribution table.
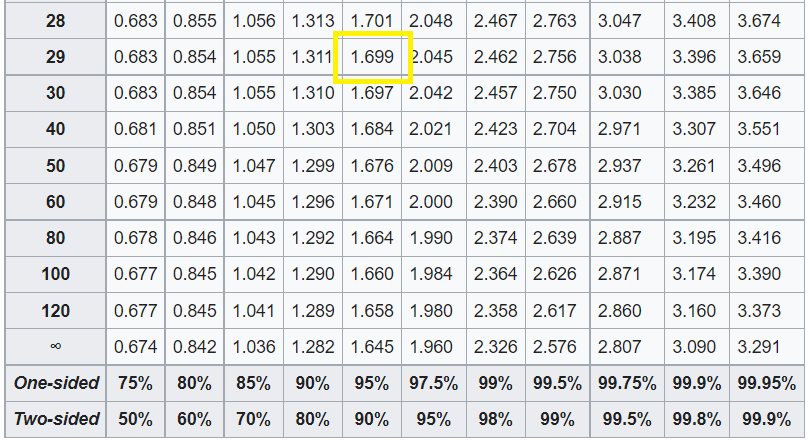
From the table above, the critical value is 1.699 for 29 dof at a confidence level of 95%. Since we are using the left tailed test, our critical value is -1.699. Clearly, the calculated t value is less than the critical value so we can safely reject the null hypothesis.
The critical p value, denoted by \(\alpha\), is usually chosen to be 0.05, corresponding to a confidence level of 95%. If the calculated p value is less than \(\alpha\), then the null hypothesis can be safely rejected. Clearly, our p value is much less than \(\alpha\), so we can reject the null hypothesis.
Note that this does not mean we can accept the alternative hypothesis. It only tells us that there is not enough evidence to reject \(H_{a}\). In other words, we fail to reject the alternative hypothesis so, it may be true.
In practice…#
The pandas library is preferable to use for time-series data analysis.
The SciPy stats module provides the stats.ttest_rel function which can be used to get the
t statisticandp value.In real life, data are generally not normally distributed. There are tests for such non-normal data like the Wilcoxon test.
Further reading#
There are a host of statistical tests you can choose according to the characteristics of the given data. Read more about them at A Gentle Introduction to Statistical Data Distributions.
There are various versions of the Student’s t-test that you can adopt according to your needs.