Priorities¶
fname = "data/2020/numpy_survey_results.tsv"
column_names = [
'website', 'performance', 'reliability', 'packaging', 'new_features',
'documentation', 'other'
]
priorities_dtype = np.dtype({
"names": column_names,
"formats": ['U1'] * len(column_names),
})
data = np.loadtxt(
fname, delimiter='\t', skiprows=3, dtype=priorities_dtype,
usecols=range(72, 79), comments=None
)
# Discard empty data
num_respondents = data.shape[0]
unstructured = data.view(np.dtype('(7,)U1'))
data = data[~np.any(unstructured == '', axis=1)]
glue('num_prioritizers', gluval(data.shape[0], num_respondents), display=False)
We asked survey respondents to share their priorities for NumPy to get a sense of the needs/desires of the NumPy community. Users were asked to rank the following categories in order of priority:
for category in sorted(column_names[:-1]):
print(f" - {category.replace('_', ' ').capitalize()}")
- Documentation
- New features
- Packaging
- Performance
- Reliability
- Website
A write-in category (Other) was also included so that participants could
share priorities beyond those listed above.
Overview¶
Of the 1236 survey participants, 940 (76%) shared their priorities for NumPy moving forward.
To get a sense of the overall relative “importance” of each of the categories, the following figure summarizes the score for each category as determined by the Borda counting procedure for ranked-choice voting.
# Unstructured, numerical data
raw = data.view(np.dtype('U1')).reshape(-1, len(column_names)).astype(int)
borda = len(column_names) + 1 - raw
relative_score = np.sum(borda, axis=0)
relative_score = 100 * relative_score / relative_score.sum()
# Prettify labels for plotting
labels = np.array([l.replace('_', ' ').capitalize() for l in column_names])
I = np.argsort(relative_score)
labels, relative_score = labels[I], relative_score[I]
fig, ax = plt.subplots(figsize=(12, 8))
ax.barh(np.arange(len(relative_score)), relative_score, tick_label=labels)
ax.set_xlabel('Relative Borda score (%)')
fig.tight_layout()
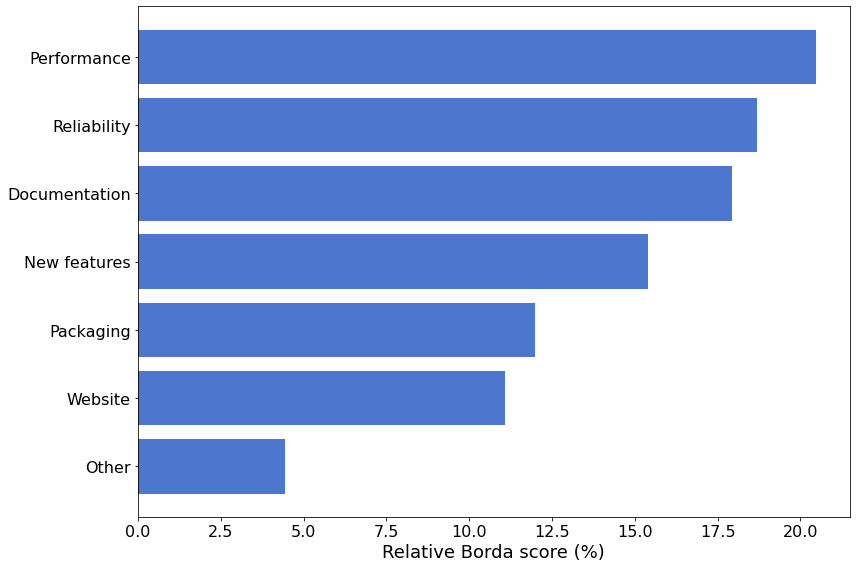
In Top Priorities we will take a closer look at how things are prioritized.
Top Priorities¶
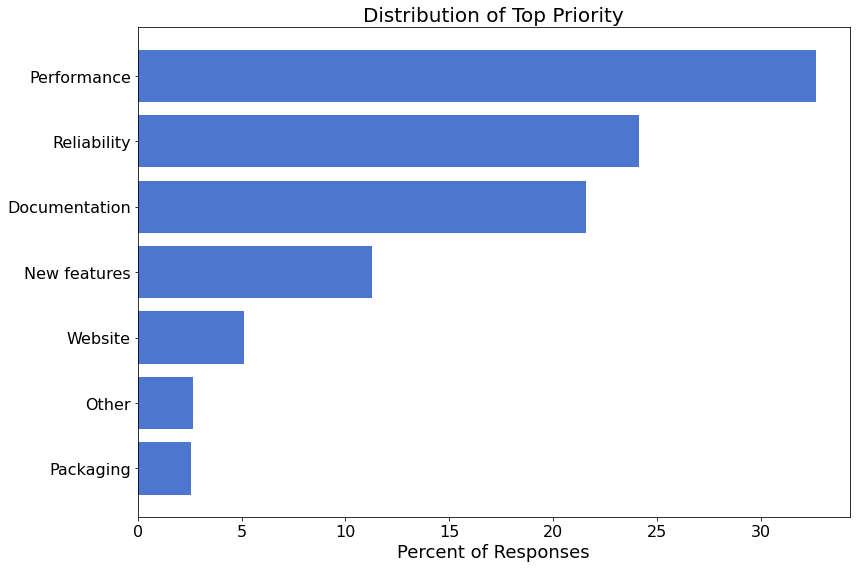
The following figure shows the breakdown of the top priority items.
# Prettify labels for plotting
labels = np.array([l.replace('_', ' ').capitalize() for l in column_names])
# Collate top-priority data
cnts = np.sum(raw == 1, axis=0)
I = np.argsort(cnts)
labels, cnts = labels[I], cnts[I]
fig, ax = plt.subplots(figsize=(12, 8))
ax.barh(np.arange(cnts.shape[0]), 100 * cnts / cnts.sum(), tick_label=labels)
ax.set_title('Distribution of Top Priority')
ax.set_xlabel('Percent of Responses')
fig.tight_layout()
Details¶
We asked respondents who shared their priorities to provide specifics on their top two priorities. For example, if a user ranked “Performance” as a top priority, they were asked to share any specific thoughts on how performance could be improved. The responses for each of the categories are provided below.
categories = {
"docs", "newfeatures", "other", "packaging", "performance", "reliability",
"website",
}
# Load the text responses for each category
response_dict = {}
for category in categories:
responses = np.loadtxt(
f"data/2020/{category}_comments_master.tsv", delimiter='\t', skiprows=1,
usecols=0, dtype='U', comments=None
)
responses = responses[responses != '']
response_dict[category] = responses
# Generate nicely-formatted lists
for category, responses in response_dict.items():
gen_mdlist(responses, f"{category}_comments_list.md")
# Register number of responses in each category
for k, v in response_dict.items():
glue(f"num_{k}_comments", v.shape[0], display=False)
Documentation¶
170 participants shared their thoughts on how documentation could be improved.
Click to expand!
Comments |
|---|
The reference manual is too much programmation-oriented. For me there is a lack of a presentation which is more mathematically-oriented. |
Better cross-linking and more links to Python and C-level source code |
Most functions have excellent documentation and I can tell that there’s a lot of attention given to docstrings. Some functions however lack a single application example. Sometimes I get a much quicker grasp on a function by just looking at the examples as opposed to reading through verbose descriptions of the numerous arguments. Especially in cases I don’t even end up using the function, it is much less frustrating when there are examples so that I immediately see that it is not what I’m looking for. |
Tbh the documentation is already probably some of the best of any library I use but specifically it would be great if it was a little easier to get into the Numpy source code. As it’s quite a large and mature project, it can be tricky to know where to start with it and how much of say the Python C-API it’s necessary to know about to feel comfortable. It’s maybe too much work for someone to do but what I’ve found amazingly useful in the past are guides where someone builds up a ‘minimal version’ of a project so you can see the core of the library (like this fort SQLite https://cstack.github.io/db_tutorial/) - it’s something I thought about trying to do with Numpy at some point (just the core array structure, no linear algebra etc) |
Providing more stand alone examples of common tasks. Often I read docs and find an example of what I am trying to do, but then need to read several other layers of docs to understand the example. |
yes, i think documentation plays a key role in sowing a seed inside learner and it would be really great if a user can find a better way in understanding the analogies and codes comprehensively used in this library |
Better examples |
I always find difficulty doing things in numpy way and has to do it in python way. Not sure what can be done. |
More simple and intermediate usage examples, and clearer documentation and usage of new confusing random number generator changes. |
More concrete examples. Though to be honest. StackExchange probably serves that purpose pretty well. |
More basics for beginners |
I guess more “beginner” stuff. |
More tutorials and examples! |
More examples |
Add longer, narrative tutorials or case studies |
More examples. Often the examples are very minimalistic (e.g. numpy.fft.fft). Having more examples helps using functions. |
More examples in the documentation |
“Simple English” explanations of how functions work. |
Try to make it easier to constructively find information, now it is sometimes “hidden” in extra tutorials |
I don’t think there’s anything to improve, But I think it should continue to be focused to be as consistent as possible :) |
Tutorials for example. |
Jupyter notebook examples |
how to use obscure features like striding, C-API etc |
Have a complete and organized index of functions. Optionally give more examples of using options that drastically change behavior (eg axis =). (Original in French: Avoir un index complet et organisé des fonctions. Éventuellement donner plus d’exemples d’utilisation des options qui modifient radicalement le comportement (par exemple axis=).) |
More examples for each non-trivial feature |
Better search facility |
More examples of usage of reach tool in different contexts |
More examples or how-to guides. |
Extend code examples at the function level. They are very helpful. |
Documentation of less major functions and more examples, more on performance optimization. |
I regularly work with structured arrays to read binary data dumps, and a 1:1 C-structure to structured array dtype would be very helpful. I’m specifically thinking of how to translate a C union into a structured array. Otherwise, python is gaining traction at my company, so documentation is the most important thing for us. |
Examples for intermediate uses |
See above. Documentation always helps, but numpys is pretty good anyway. |
It is good, but sometimes it can be hard to find functions that I suspect that NumPy has. The doctrees have been greatly improved but drilling down to the functions can be confusing. Additionally, lots of functions have good details if you are an expert in the topic but are not so good if you are not. A good example is the filter design functions. scipy.signal.butter has an argument called “analog” it’s description is unhelpfully “When True, return an analog filter, otherwise a digital filter is returned.” What is the difference? why might I care? The code samples for scipy.signal.butter are another good example, they use the library very differently than I might when I use it. (this is more typical: https://stackoverflow.com/a/12233959/4492611) This is not to say that the docs are not excellent, they are just the main way that I interact with NumPy and the topic I care the most about. |
* giving more examples for different situations instead of making one for multiple methods. * also, plus one weird example might widen people’s horizon |
improve the structured overview so that idiots like me don’t try to program stuff that is just a small subset of np.einsum |
The NumPy library is very large, and because of fairly strict backward-compatibility guarantees, there are many different ways to achieve a particular task. I think that the documentation could be improved with an informal style guide that helps new and old users sort out what the ‘modern’ NumPy way is. An alternative (if a style guide would be too contentious) is to provide a collection of examples of ‘modern’ NumPy being used to accomplish common tasks and avoid gotchas. For example, a linear algebra collection might include examples of the use of 1d/2d ndarrays as opposed to the outdated matrix type, the use of @ as opposed to np.dot, etc. |
Taking scikit-learn as an example, maybe more tutorials on how to do things and documentation explaining the theory and concepts behind the functions and implementations. |
More examples in the documentation would be awesome, sometimes I found myself using functions that solved my problems but the utility of it did not came from documentation, but from a colleague showing it to me |
The NumPy documentation is already excellent. The only problem I have is that it sometimes feels hard to figure out all the features that exist. I am not sure how to overcome this exactly. Maybe some more use-cases where a user is guided through a complete problem set is helpful (I know that this also already exist, maybe more of that for different use cases). |
I will first say that in my view numpy is a gold standard in self-generated documentation and everyone involved in the project should be very proud of the state of the documentation. I have found some cases where more examples would be useful. I have a background in numerical physics and I find some of the documentation of complex numerical algorithms to be lacking, although the only examples I can think of now are in scipy. Where a complex numerical algorithm is concerned I don’t think it is enough to document the API. There are always limitations and edge cases where the algorithm will not perform well, or could even return incorrect results. The documentation could do more on this front. |
More examples and recommendations, I would copy pandas. (Original in Spanish: Más ejemplos y recomendaciones, copiaria a pandas.) |
Organising documentation will surely help a lot. Good examples are Docker or Tensorflow documentation. Another improvement is to add more guides for developers that are interested in contributing to NumPy. |
Certain scientific doc’s are ok, but not always referencing good papers/sites. |
NumPy, to me, had and sometimes has a steep cliff: I can easily understand the basic use of a function, but actually wrapping my head around how to use the function on a dataset in a useful way in a complex function can be difficult. I don’t think there’s necessarily an easy solution for this, but more varied examples in documentation could help. |
inclusion of in depth examples |
- documentation between numpy and scipy (and different versions) is a bit confusing sometimes - documentation in some cases is just not enough to understand what a function does - sometimes I’m not sure if I just cannot find the correct method I am looking for or if it does not exist entirely |
I think adding some high-level tutorials, especially for the more obscure parts of NumPy: - Stride tricks - Structured Arrays and complicated dtypes - Buffer protocol integration (especially w/ 3rd party libraries or custom C/C++ codebases) - Docs on how to get better performance (w/ pointers to 3rd party libraries like Cython or Numba) |
more documentation in Spanish. (Original in Spanish: mas documentacion en español.) |
Expand the connection between current documentation and basic mathematical models. Currently in many sections of the documentation there is an extract of the concepts used (as in fft) but it would be nice to have the reverse process: A documentation that from the mathematical models can reach the related numpy functions. (Original in Spanish: Ampliar la conexión entre la documentación actual y los modelos matemáticos de base.Actualmente en muchas secciones de la documentación hay un extracto de los conceptos usados (como en fft) pero estaría bien tener el proceso inverso: Una documentación que desde los modelos matemáticos pueda llegar a las funciones de numpy relacionadas.) |
I am sometimes confused over the exact working of the more seldomly used arguments of a function even after reading the docs. More examples and longer explanations would help. Also, numpy has many functionalities and I often find it hard to identify what I need for a certain problem. |
Add more examples on the use of numpy in specific areas (differential equations in physics, mathematical models of biological systems, etc). (Original in Spanish: Agregar más ejemplos sobre el uso de numpy en áreas específicas (ecuaciones diferenciales en física, modelos matemáticos de sistemas biológicos, etc).) |
Documentation of all the algorithms/methods should have appropriate citations and a variety of examples (many of them do already, but this can still be improved) |
Videotutorials |
All functions should be typed so tools like pyright can give better live documentation to the user. |
Please add more step-by-step tutorials (and direct links to them from official documentation). Examples are the great way to understand some new concepts |
Sometimes it is difficult to find the documentation and sometimes you will find documentation of functions from previous versions that are not known to be older, so it would be good to specify which functions are current and which are not. Also sometimes it is difficult to know how to search certain functions. (Original in Spanish: A veces es difícil encontar la documentación y a veces se encuentra documentación de funciones de versiones anteriores que no se sabe que son anteriores, por lo que sería bueno especificar cuáles funciones son actuales y cuáles no. También a veces es difícil saber como buscar ciertas funciones.) |
Tutorials and for some people, translations. (Original in Spanish: Tutoriales y para algunas personas, traducciones.) |
Putting more examples of how to use the functions |
It is important to have information in a native language, especially when learning. (Original in Spanish: Es importante tener información en una lengua nativa sobre todo cuando se está aprendiendo.) |
It tends to be criptic. I usually need to go to other sources to learn |
Translation to multiple languages |
More tutorials beginners, with very simple ideas, very simple terms, with lots of explanations |
Some features such as array_function or array_ufuncs are poorly documented for more complicated use cases. While the documentation is fine to provide a simple understanding, to get a more complete understanding I read full implementations from dask or cupy. Also some less ``mainstream’’ interfaces sometimes lack examples that would greatly facilitate the meaning of options. A recent example that comes to mind is lgmres (can’t think of a numpy right in this instance). |
More examples and tutorials. |
The docs are dense for new users. Provide more examples and applications, including video when possible, and worksets, possibly in notebooks? |
Better and clear documentation for many methods missing. |
Documentation isn’t always clear on what to do and some terms are very full of jargon. |
I would like to see more extensive examples |
I actually think your documentation is very good, especially when combined with stack overflow answers. But I was required to pick something! |
can be useful to have multiple (consistent and integrated) documentation systems that target specific users. e.g. language level specification vs gentle introduction including concepts. |
Docstrings of numpy functions do not all match in style. |
Although not really anyone’s fault, old deprecated commands (especially on the SciPy documentation) are everywhere. Streamlining the numpy.random documentation to clarify trade-offs would be helpful. I also think that many beginner’s are unaware of a lot of the many useful commands, so having some easy way to find new commands (like numpy.roll) would be great. There have been many times that I have written code one way, then learned of a superior (cleaner / more performant) way a year later. I think the numpy.where command is a good example. |
Examples - Lots |
Many of the high level documentation pages in the numpy documentation are incomplete. For example, the documentation on dtypes does not list every possible dtype and doesn’t give a full description of things like the string dtype specification. |
Easy to understand how to use Numpy in Japanese. (Original in Japanese: Numpyの使い方を日本語でわかりやすく整備.) |
Types, better navigation |
more How Tos |
One simple thing is update the formatting - I think some simple stylesheet tweaking may make the docs themselves a bit more aesthetic ;) More cross-references between components (e.g. “See also” linking np.random.uniform to np.random). Some examples on reference pages are great, but some pages are missing them. Also, it would be excellent if the existing NumPy tutorials could be linked (as permalinks / versions) from the documentation when possible. I’m thinking MATLAB-level documentation quality (which TBH is a high bar!). |
documentation is the most important thing about anything. It allows everyone to read the data and useful information about the project ang get to know more technically. |
I think including links to more sophisticated uses of numpy, using common idioms, might be helpful |
As someone who has been introducing peers to using Python as a scientific tool, questions about NumPy are often raised (e.g. how to do particular things, “gotchas” when implementing specific functions, or more general interest in a “cookbook” of various minimal working examples of it being used). While the NumPy documentation (specifically, that available through the manual) goes some way to addressing this (especially as a quick reference for function arguments/outputs/references!), there is always room for improvement: One particular aspect of this could be in the examples provided for “less trivial” examples where users may trip up on certain details in the implementation. Another possibility could be adding additional sections to the “Explanations” and “How Tos” pages to cover common Q&As from e.g. Stack Overflow etc (although I see that this is only a fairly recent addition as per NEP 44, and look forward to seeing how it progresses!) |
Documentation on using on embedded devices (like for example how to call from C++, etc.) |
Make documentation easier to understand, and written in plain language. |
Make it more like scikit-learn docs |
I want more execution examples. (Original in Japanese: 実行例を増やして欲しい.) |
Perhaps the current docs with format Overview->Functions->examples could be more explicit. When you find yourself looking for np.fft.rfft, it is not always clear what you want, and moving between the three is not always intuitive (I use the top banner to move up, moving down is a little awkward. Overall though, numpy documentation is light years ahead of a lot of projects that I have used. |
more case based tutorials |
More “vignette” style examples. Just generally more examples, both straightforward, and within the context of a real use case. |
I would like to see more examples given, perhaps with some reference regarding performance. |
Possiblity add more useage examples to less commonly used functions? |
- Documentation can be hard to find. For instance, say I go to learn about vectorization. This page (https://numpy.org/doc/stable/) has at least six different links that one might follow to find relevant documentation. Picking one, Tutorials (https://numpy.org/doc/stable/user/tutorials_index.html), gives another set of links with no hint as to their contents. Finally, I have to guess that my topic would be considered “NumPy Basics”. I think this navigation system should reworked. - Also, lots of documentation pages require a non-trivial understanding of NumPy to parse. |
giving more elaborate examples |
It might be nice to have more real world examples/use cases regarding what you can do with some of the algorithms within numpy. |
It would be great to have some: 1. More beginners tutorials 2. Performance optimizations guidelines 3. More usage examples. 4. Make some online sandbox to test examples with different versions 5. Right now most of questions can be answered using google. Probably, most popular must be kept in documentation. 6. We need some Slack/Discuss platform to discuss |
Reference documentation is already good, but more tutorials and longer examples would be useful. |
More extensive examples. |
More elaborate examples and better error messages. |
A gallery of examples for the different use cases, much like you’d see for a vis library. |
I actually think the numpy documentation is generally good, but making sure documentation is current, well-explained and in as many languages as possible should always be a high priority for an open source projetct as important as numpy. |
It always amazes me how much numpy can do. I only recently found out that there are financial functions included in the library. I find it really hard to find most of these things out until I’m specifically looking for something, and then eventually find my way back into numpy through 3rd party platforms (e.g. StackOverflow telling me I should have been using numpy for this all along). Tutorials and worked examples make great reference material, the scikit-learn community is one of the places that I continue to draw a lot of inspiration from. |
More examples. |
The old “EricsBroadcastingDocument” should in my opinion be part of the core documentation for how broadcasting works, it’s extremely good and the figures help A LOT. |
more example code |
nice clear examples and guides |
Additional examples Better “discontinued in future” error messages: these tend not to offer any help in how to replace them, though I migth misremember and this was Pandas fault. |
More examples. There already are numerous examples and the documentation is generally excellent, but in terms of examples it is not yet at Mathematica levels. |
If you do provide the option to inherently parallelize certain functions, the documentation to use those features needs to be written. Otherwise, I think the documentation is fine. |
The documentation is very good and reliable imo. I would like more detailed narrative docs for the technical parts and the descriptions of algorithms) |
More concrete examples from different areas where numpy is being used. Also rating them as starter to experienced |
Fixing/updating inconsistencies |
Maybe more worked examples |
Related, a problem often arises when users of other packages (like pandas) fall back on really slow design patterns that could easy be optimized with numpy. More documentation for best practices integrating numpy into a pandas-centric workflow could users who don’t think about optimization regularly. |
IT can be hard to fully grasp the details about what a function does and how it interacts with other parts of python. |
I think more/clearer examples could be effective some don’t fully explain the functions |
More examples. |
Tutorials |
I want detailed documentation on minor functions. (Original in Japanese: マイナーな機能にも詳しいドキュメントが欲しい.) |
The Numpy documentation could add detailed examples for each function, details in the sense more explanation about input and output. |
Documentation is often unclear or incomplete. I think also some older versions of numpy have functionalities renamed which can be confusing. |
I would like you to include some graphical examples, sometimes it is difficult to extrapolate the math. (Original in Spanish: Me gustaría que incluyera algunos ejemplos gráficos, aveces es difícil extrapolar la matemática.) |
Insert more usage examples and raise some points that, although they are clear to those who have been using them for the longest time, still confuse new users like the cases of the views of the arrays when there is slicing. (Original in Portuguese: Inserir mais exemplos de uso e levantar alguns pontos que embora sejam claros pra quem é usuário há mais tempo, ainda confunde novos usuários como os casos das views dos arrays quando há o fatiamento.) |
Try to provide different examples of use for each function. |
I’m a brand new numpy user. I want to be able to find answers to my questions. |
I feel that np has pretty good documentation out there, but it’s often hard to find the right documentation for what you’re looking for. For instance, there are often several functions that are closely related and it’s hard to know which is the right one to use (it’s even harder to remember without needing to look it up each time!). Perhaps additional ways to group together pieces of documentation with a high-level commentary that says “here’s the one you should generally use unless you’re in this case…” would help. |
I like the plans in NEP 44. The current (1.20.dev0) “absolute basics” and “quickstart” tutorials repeat a lot of the same content, and could probably be consolidated. The “absolute basics” material has 26 section headings, which makes it hard to follow. I really like the way new front page of the website highlights the main concepts of “vectorization, indexing, and broadcasting” and then lists some of the subpackages than NumPy offers. Perhaps that’s an outline that our intro docs could follow? I also wonder if multidimensional arrays should be introduced part-way through the new user tutorial so they can see some basic array operations sooner? |
More (and more thorough) code examples. A HOWTO (like Python’s – https://docs.python.org/3/howto/index.html) that details recommended solutions to common problems. |
searching for numpy functions in duck duck go/google often returns docs for older versions of numpy first. fix SEO/remove older pages so that newest pages show up at the top. |
Use case notebooks |
Easier to navigate index |
It would be nice to have a small visual refresh for NumPy’s docs (the new website is great!). The pandas project has a really nice new theme. Also, as a developer, I really like NumPy’s docstyle and would like to learn more about tooling for enforcing NumPy docstyle in my own packages. pandas has really nice docstyle enforcers in their CI, maybe I should try those in my own project. |
I still think completeness and specificity in the documentation is the weakest link in numpy. I think users should not have to consult source to verify specifics of the underlying maths of some functionality but currently that is sometimes required |
add best practice and/or performance comparison of optimal/sub-optimal ways to use each functions |
Keep up the good work. Numpy/Scipy documentation is first rate. |
Streamlining (directing users more clearly to different parts of the documentation: tutorial, user guide, API reference) and modernizing the design. Obviously, improve the writing on many sections. |
More tutorials. Lots of examples in almost all docstrings. |
The documentation is already very good. For beginners more example code and/or visual explanations for cocepts that are hard to understand may be useful. |
The high level documentation like tutorials and narrative docs on advanced topics are not in good shape, and there isn’t enough of it. |
The API document design feels old. I want you to design the same as the project top page. (Original in Japanese: APIドキュメントのデザインが古臭く感じる。プロジェクトトップページと同じようなデザインにしてほしい.) |
Expansion of Japanese documents. (Original in Japanese: 日本語ドキュメントの拡充.) |
Like statsmodels, please enrich the examples with a mathematical background and a notebook. (Original in Japanese: statsmodelsのように、数学的な背景とnotebookによる例を充実させてほしい.) |
More Examples that explain what things do and how they work Visual Explanations, especially in everything that manipulates ndarrays |
The documentation could be more comprehensive, with case studies, for example. Simpler tutorials on “basics”, or “what to do” with Numpy could also be covered. There are many basic users who don’t understand where Numpy ends and where Scipy starts. (Original in Portuguese: A documentação poderia ser mais abrangente, contando com estudos de caso, por exemplo. Tutoriais mais simples sobre o “básico”, ou “o que fazer” com o Numpy também poderiam ser abordados. Há muitos usuários básicos que não entendem onde acaba o Numpy e onde começa o Scipy. ) |
I want annotations on newly introduced functions and methods. (Original in Japanese: 新規導入された関数やメソッドに注釈が欲しい.) Add ‘introduced-version’ notes to new functions or methods. |
I think it is good to set up a project to translate documents into each language. (Original in Japanese: 文書の各言語への翻訳プロジェクトを立ち上げるのが良いと思います.) |
Creation of various kinds of educational material, contemplating different levels of expertise and experience. |
The new website is a nice improvement. The documentation presented by it should have a high priority as it is the basic way users learn how to incorporate NumPy’s functionality into their projects. |
1) If I google for some numpy function, all the top hits are referring to version 1.17 instead of the latest version, and there is no easy way to directly go to the latest version. 2) It is fairly common that I feel that the documentation only covers very simple examples, so the complicated usage is not obvious. |
Stronger documentation standards and automated docstring checking and validation, c.f., pandas. For example, how are parameters referenced in doc strings, |
NumPy feels like it is in a relatively good place. What gaps remain should be filled as soon as possible especially examples should be used extensively. |
Documentation is the core of any project. Any new comer would look towards the documentation for better understanding of the software/open-source project. Hence documentation should be given an equal amount of priority as well. |
Overall I find the documentation very good and comprehensive. Two areas where the documentation may improve is in: 1. Containing more “typical usage” guides for some of the functionality in NumPy. 2. Better explaining subtle details that may cause a lot of frustration if unknown, possibly via references to other sources. |
Making great strides, but more examples for various disciplines would help attract users. Some documentation is devoid of practical examples. |
Documenting the (limited) portion of NumPy that users should actually use |
Documentation is improving well already, stay on track :-) |
In general the docs are good, but the small examples illustrating a function are sometimes a bit cryptic. A short sentence describing what’s happening could help / / As a dev it’s also helpful when a parameter is tagged with eg “new on 1.14” so I know whether I can use it depending on our dependency constraints |
Numpy docs are completely functional and do the job. However, between the time the numpy project began and now better documentation solutions have come online. Numpy docs have a strange previous/next topic interface that don’t make sense without context. A full featured scrollable table of contents on the left (a la readthedocs) and even better fonts (I’m always bothered by the main function font and spacing with the black/yellow contrast). / / My personal favorites for how documentation could look like would be Julia and Bokeh. |
Including more use/edge cases in the docs as examples, possibly drawing from common uses in stack overflow, for instance. |
Just anecdotal: I found that a combination of tensordot, moveaxes and diagonal solved a specific problem for me. But finding out what to assign to the parameters axes, axis1 and axis2 was literally an exhaustive search. I wrote loops trying every possible combination and compared the result to the correct one. A bit of prosa and examples would have helped to understand what is happening. |
Latex |
The documentation is not lacking, but comments on what the examples are doing in some packages, especially pointing out where a function call is made for speed or memory optimization would make finding the sample code I’m looking for a more smooth experience. |
While I do like the documentation and I’ll be honest, I should probably look at it more than just messing about or defaulting to stackoverflow (so take my words with a grain of salt!), I think as I stated to the previous question, really focusing on how people can work optimally with NumPy and not just what the features are would be amazing. |
Ensure every parameter is documented at sufficient level. Many params are left by the wayside |
More examples. |
I think the documentation is really good. But it could be better, especially in providing context for why I should use one function vs another with similar functionality |
Alot more easy-to-understand & use tutorials for what can be done using NumPy & some of the newer tools that use it, like ML, ….. |
Ability to change version (e.g., from v1.19 to v1.18) without leaving the webpage. |
Research and design ways to make learning and applying numpy more effective. Seek funding to research and implement these learning processes. (Original in Spanish: Investigar y diseñar formas de hacer mas efectivo el aprendizaje y aplicación de numpy. Buscar fondos para investigar sibre estos procesos de aprendizaje e implementarlos.) |
The documentation could be improved to perform operations with images of more than three bands. (Original in Spanish: Se podría mejorar la documentación para hacer operaciones con imagines de mas de tres bandas.) |
Several functions lack good documentation. The only way to know their behavior is to test it manually which can be time consuming. |
New Features¶
75 participants shared their thoughts on new features to improve NumPy.
Click to expand!
Comments |
|---|
Not quite sure, but they’re the life blood that really draws in new users AND re-engages the existing base. |
I’d love to see support for automatic differentiation (via AutoDiff as in Jax for example) land in NumPy. |
If programmers in stackoverflow can’t find a way to solve his task with numpy and it appears often, this task must send to NumPy to make new functions and possibilities |
Automatic differentiation |
I do not know Numpy well, but I know that a great competitor of numpy is Matlab, because it has many functions for engineers in an easy way, that’s why many remain in Matlab and do not migrate to python. Ease of rolling number models, differential equations, optimization and visualizing the results with just a few lines of code is what keeps some engineers from experiencing the potential of NumPy. (Original in Spanish: conosco Numpy profundamente, pero sé que un grande competidor de numpy es Matlab, porque tiene muchas funciones para ingenieros de forma facil, por eso muchos siguén en Matlab y no migran para python.. facilidades de rodar modelos números, de ecuaciones diferenciales, optimización e visualizar los resultados con pocas lineas de código es lo que hace que algunos ingenieros no experimenten del potencial de numpy.) |
easier operator overloading of numpy arrays, e.g. to change ‘+’ to direct sum and ‘*’ to tensor product |
Not really sure actually, just certain there is more for you to add |
Distributed computation Cuda support |
GPU support Different upscaling/donwscaling for ndim arrays |
Standard Error |
Take over Biopython to make it better A lot of analysis pipelines for biological big data is restricted to R. Would be nice if it can be done in Numpy. |
Support for physical units |
Adequate frequency filtering |
Wavelet support. |
GPU support |
Better support for handling large scale data, lazy loading, reading multiple files |
More control over low level functioning and documentation of what the function does in an unobtrusive but encouraging way |
Add suport for Homogeneous transformations. These are 4x4 matrices that contain information about position and orientation of objects. They are very popular in robotics and it would be very nice to have support for that in numpy. I need to build this matrices from Euler angles, or get the euler angles from them, and also y need to be able to do differentiaton an integration operations with 6D velocity vector. |
Nothing specific. I think numpy is fantastic, but if I was to pick anything to make it better, it would be more stuff. |
Lifting the array dimension limit would be nice. |
NumPy on CUDA |
* an interface to access copy or the original array easily. can’t be sure from time to time. this needs to simplified. |
I often use numpy to run simple physics models in a vectorised manner, i.e. operating on a numpy array to compute many solutions at once. I find it difficult to write code that can accept a single float as well as a numpy array, often getting type errors. I also have cases where the code may bifurcate in behaviour into two cases. In these cases I have to compute difference things and store them in different parts of the array, which is a quite manual process. Possibly I don’t know all the features that are already there! |
Develop/Promote utilities around |
Laplace transforms and modules for control. (Original in Spanish: Transformadas de Laplace y módulos para control.) |
Optimisation |
Support for type annotations |
GPU support |
Named arrays (like pytorch named tensors) |
Supporting modern fortran (particularly derived type and coarray) in f2py; Specifying dtype using type annotation (PEP 484) |
Nan value for int arrays (sorry I know that is not numpy’s fault)… new dtypes |
more utilities for machine learning, for example interfaces for pytorch and tensorflow. |
- Better support for generators, and other streaming-like techniques for minimizing memory usage - Better support for user-space parallelism (something like multiprocessing.Pool.map and variants would be nice) |
Expanded tensor algebra would be cool. |
Algebraic topology algorithms would be very useful. Geometric objects as well |
Native GPU support (like CuPy, but better coverage of Numpy-related operations), better serving for robotics project (like e.g export to ONNX feature) |
More functions for Signal processing. New functions. |
rational number support for exact linear algebra calculations |
An easier way to define new ufuncs, and finalization of the array_function interface. |
I would like a better way of addressing specific axis in a multidimensional array. Right now I’m tampering with numpy.s_ and direct calls to getitem, but I’m not satisfied with that. It is also not usable in numba compiled code and this limits me. |
Some way to deal with auto detecting upper and lower limits of data (e.g calculating a mean of an array containing a ‘10<’ value). An object with upper and lower error bounds included and functions to deal with them (e.g getting errors on log values, propagation of errors etc). |
Named axes, named axis based broadcasting, performance diagnostic and inspection tools |
Automatic differentiation |
Function for findingen nearst indcies |
Marking missing data without using NaN, i.e. a NA value. |
Sparse matrices Ragged arrays |
Type system improvements A high-level API name-space like numpy.api |
Extend the functional programming subpackage. |
Easy data plotting |
more linalg functions. |
NEP-37 or successor improvement |
I’d like to see more linear algebra, either wrappers around existing C or Fortran or entirely new development |
Better support for classes that inherit from NumPy |
Being a core element in designing API for external projects extending arrays |
One feature that came up on twitter is the ability to estimate trends in time series that have serially-correlated noise. There are nice C++ packages available (for example Hector http://segal.ubi.pt/hector/) , but such a function in numpy or scipy would be very useful. |
I am very new to numpy so perhaps this question isn’t appropriate. Why can’t there by strings in a numpy array? |
The ability to index multi-dimensional arrays with a scalar index such as that returned by argmin and argmax without resorting to unravel_index function. This would clean up a lot of code and allow direct indexing with argmax/argmin results. |
Automatic differentiation outside of JAX, which might still be too tied to the Google ecosystem/way of doing things. |
Pursuing development related to NEP18 |
Features I would use if available (have written own code to implement): - Constrained spline fits that preserve concavity. - Translating FORTRAN-formatted text files with floating point values with exponents that are written without the ‘E’ separator. |
A function to keep only the unique numbers of an array and eliminate the repeated ones, but without preserving the order. (Original in Spanish: Una función para conservar solo los números únicos de un array y eliminar los repetidos, pero sin conservar el orden.) |
Named arrays |
Functions that work weights such as the average, extend these functions with percentiles, std, kurt, skew, etc. (Original in Spanish: Funciones que trabajen pesos como el average, extender estas funciones con percentiles, std, kurt, skew, etc.) |
Integration with other numeric GPU librareis - e.g pytorch/mxnet |
High-order spectrum analysis Bispectrum/Trispectrum. (Original in Japanese: 高次スペクトル解析 バイスペクトル/トライスペクトル.) |
A function to perform calculations in multiple loops with the same memory and performance as C language. (Original in Japanese: 多重ループでの計算をC言語と同程度のメモリ、パフォーマンスで行う機能.) |
GPU support with simple commands |
Lightweight JIT python-markup lang similar to halide-lang but only genreate stack call, caching, localisation and loops. Still count on normal compiled C functions that serve sclalers, SIMD vectors, also it should support GPU, and threads. The idea behind it is to reduce the memory and CPU caching journey, just one memory load & store |
- Easier ways to create fast implementations of recurrence relations, which typically are implemented using loops. - Custom stride implementations. I’m regularly dealing with data structures for spherical harmonics, which naturally would be indexed with two indices, where one is always positive and the other is positive or negative, smaller in magnitude than the first. Similar to how a “normal” array is mapped to a linear index using stride[0]*idx[0] + stride[1]*idx[1], my data can be mapped to linear index using idx[0]**2 + idx[1]. Currently I have to choose between easy implementations using “normal” arrays which give me ease of indexing and broadcasting at the cost of storing a lot of zeros, and custom implementations using algorithms working directly on the linear stricture or wrapping them in classes. None of these two custom solutions give me access to the really nice broadcasting in numpy. I realize that this is a massive change to how numpy works, but I think it could simplify quite a lot of scientific calculations in data structures which are not “rectangular”. |
Add static types to NumPy |
Better sparse / large matrix management. Though I suppose this is part of scipy, it’s such important area that therehould be serious thoughts about how the overall sparse infrastructure can be improved / extended / made faster. |
More variety of mathematical functions, can be implemented in numpy. |
Features concerning better integration/interoperability within PyData ecosystem. |
continued progress on various protocols proposed in recent NEPs for supporting compatibility with third party libraries implementing the NumPy API. |
Incorporation of various routines/functions from Math 77 Library, e.q. DIVA |
Other¶
21 participants selected “Other” as a top priority:
Click to expand!
Comments |
|---|
I think the project is excellent and the organization and planning that they have been carrying out is very good. (Original in Spanish: Creo que el proyecto es excelente y la organización y planificación que han venido llevando a cabo es muy buena.) |
Static typing. Being able to check dtypes and dimensions statically with Mypy would be nice, but even rudimentary static typing support improves documentation (especially with Sphinx’s autodoc feature). The ideal would be a static typing language powerful enough to describe conformable arrays: e.g., my_func(a: m by n, b: n by k) but somehow saying that both arrays have a dtype that can be safely cast to float32. |
The only really high-priority issue for me is othogonal indexing, all other priorities pale in comparison. |
Not really missing stuff for what I do, that‘s why I selected, that I‘m currently not interested in contributing. Numpy is generally quite fine. |
To me, a GPU backend is the single and most important objective that Numpy should aim for. |
uarray and unumpy |
I’d like to have a way to tell mypy which ndim/shape/dtype is expected, and I’d like for mypy to be able to find some errors with such information. In a dream world, that would work with |
Because there seems to be no plan for a NumPy Version 2, I think that a roadmap and timeline to consolidate and clean up the NumPy API would be very helpful. This ties in to the informal style guide proposed above. |
There’s a few things that have been staged for “2.0” for many MANY years… the fact it’s been this long I believe indicates a lot of problems - I think numpy as a whole needs to identify and resolve the issues that are hamstringing them so horribly. |
Micropython support for numpy, perhaps on a module to module basis would be VERY useful |
Type hinting for ndarrays supporting size in order to allow autocompletion. |
Is there a numpy tutorial? |
Having to write out |
Work with other projects like Numba, Cython and Pypy to create a JIT. |
The new numpy nditer C API is not yet well supported by Cython. In fact, it would be super nice, to have a high-level Cython interface to this, such that I could use nditer within Cython (perhaps even within nogil), but without needing to care about the bloody C details. Not sure if that is possible at all, but it would be cool. |
Numpy is used in many code bases, so breaking backwards-compatibility is hard. There are however some inconsistencies in numpy which could be fixed to make it a better library. I wish numpy was more lenient on breaking changes at the cost of increasing the major version. |
Helping CPython refactor their C-API should open up opportunities for accelerating all other Python code. But this is only feasible if big projects like Numpy and scipy are compatible. This seems like an area where the new funding work group could help arrange funding for both Numpy and CPython |
Defining and improving high-performance interop with other libraries - e.g. PyTorch/Tensorflow/cuPY |
Reactivity and first impression for new contributor would be good. The team is super friendly but unless you are already well versed, it can be easy to get lost amount all open PRs. |
The one general area I currently experience the most issues with in NumPy is custom array-like types and the possible extension to custom dtypes. NEP 18 opened the way for a lot of great inter-library array-like type compatibility (especially for my favored use case of unit-aware calculations), but there is still progress to be made. Two examples are NumPy masked arrays not working properly with other array-like types that wrap them and continued progress being made for units-on-dtype arrays (rather than subclasses or wrapped arrays). |
Related to the above, I think one of the biggest concerns related to the scientific Python ecosystem (and, given it’s position in that ecosystem, NumPy itself) is fragmentation of scientific Python computing tools as a result of the introduction of many new array libraries. It’s not clear what more the NumPy community could be doing in this regard, and the work that is already being dedicated towards interoperability is very valuable. I would just like to reiterate the importance of this work and think the fragmentation of the ecosystem into multiple ecosystems based on different underlying array libraries would be detrimental to scientific Python as a whole. |
Packaging¶
24 participants shared their thoughts on how the packaging utilities in NumPy could be improved.
Click to expand!
Comments |
|---|
work on a packaged distribution like anaconda, but independent. |
I think it’s more of a general python packaging thing. Everything feels so fractured between conda and pip and apt-get (for example) that so many people I know run everything in a container and I feel like that’s just kicking the can down the road, wrt dependencies. |
1. conda is horrible for windows. Need something better for packaging. 2. More explicitly detailed error messages when install fails. |
provide individual feature specific installation instead all at one. Provide wrapper for all programming languages with standardized output such as JSON, xml, BJSON or other format. |
It has gotten much better than it was in the past, occasionally still see compile-time issues. |
I would love to have a distribution for numpy as independent of the OS as possible. So numpy can be executed anywhere. |
wheels for more platforms, like aarch |
Propose new packages with which simulations and models can be carried out in different areas of science, seek collaborations with people who can contribute to each of the packages. (Original in Spanish: Proponer nuevos paquetes con los cuáles se pueda realizar simulaciones y modelos en distintas áreas de ciencia, buscando colaboraciones con distintas personas que puedan contribuir a cada uno de los paquetes.) |
Ability to distribute only selected submodules of numpy (with pyinstaller) |
Better integration with setuptools |
Supply conda packages for new Numpy releases. |
plotly |
Ensure it is easy to install on all major OSes with pip and conda. |
arm64 wheels |
It’s pretty good right now. I put it up high on my priority list to indicate that none of the lower priority items should be allowed to endanger simplicity of installation. NumPy is too fundamental for computational science. |
Building from source could be made easier. The documentation is a bit scarce on that, making it difficult to find all the nobs that can and/or should be set. Also some sort of dependency on what Cython version should be used for which Numpy version would be helpful. |
Splitting numpy up into smaller packages, making applications using numpy smaller if they don’t require everything Help make something like conda-forge for regular Pypi packages be a thing. This will help smaller projects leverage the same best practices when it comes to creating packages with compiled code |
Some portions of NumPy’s build system could be broken out to small, reusable packages (like the multithreading builder). I’d like to see a few more ManyLinux2014 special arch’s supported (like PowerPC), though the one I’m most interested in, AARCH64, is now included which is great. |
pandas |
fftpack scipy.signal |
Easy to install high performance on any platform |
I’m not quite up to date with the new developments but remember it being a quite haphazard in the past (~2018/2019) with how it picks up dependencies via environment variables. The documentation was thin and it would be good to offer some advice regarding the fact that the pip/conda versions are only targeted to the base x86_64 instructions and should be avoided if performance is important. Intel-numpy is a workaround but it’s not mentioned in the numpy docs and a more general statement in the numpy docs would be more helpful imo (for any x86/arm/etc vendor) |
Distribution in terms of blas vs mkl, this issue is nontrivial for those unfamiliar |
Packaging looks ok to me |
Performance¶
184 participants shared thoughts on why performance is a top priority and ideas on how it can be improved.
Click to expand!
Comments |
|---|
I dont know enough what goes under the hood in NumPy, but still at least for me it is the top priority |
As NumPy is a library that is widely used both professionally and academically, it is certain to guarantee high performance and reliability. (Original in Portuguese: Como NumPy é uma biblioteca de vasto uso tanto em âmbito profissional como acadêmico, é certo garantir alta performance e confiabilidade.) |
Since NumPy operations are at the core of so many programs, any performance improvement will have a significant impact on many applications. NumPy is by no means slow, but optimizing its performance would be nice. |
Give |
- slow on small arrays - better integration with pypy - why not a jit / or integration of numba - more transparent access to GPU (even though it’s quite good already) |
GPU support |
Parallel support with numba, vectorization of functions and speed improvements, possible implementation with something like arrow |
many functionalities can be sped up using numba, it would be good if this gap could be closed |
by improving user-base interaction by continuous updates of features by emphasizing on key learning objectives by working on tutorials |
Proper and dynamic support for vector extensions across the entire library, i.e. current versions of AVX etc. numpy should auto-detect the capabilities of CPUs and choose the fastest option for every operation. |
Many projects are addressing performance issues around data manipulation. As a core component, maintaining performance is important. |
More parallelization and GPU support |
Mostly I think Numpy is very performant - the changes to the fft backends are greatly appreciated. I just think that maintaining this performance would be good - making use of multi-threaded operations would be good, but I know this is outside of scope for NumPy generally and I use other libraries with a NumPy-like API when I need this. |
Some operations take too long time. |
No particular place - I just think that as the existing np code is already quite well documented, etc. Performance is the most important aspect of a scientific/numerical library. |
Open to this improving however possible. |
Facilitate the use of multiple threads or processes for operations that require high computing power. (Original in Spanish: Facilitar el uso de múltiples hilos o procesos para las operaciones que requieran alto poder de computo.) |
It should always be a priority. It is for me what makes numpy great. It is fast! |
I want the ability to use the GPU. |
As manually added, I think GPU-processing mit help. I‘m in the field of image algorithm development so mostly work on image data (image sequences as I‘m working on digital cinema technology) Performance isn‘t that bad btw. just the thing that can‘t be improved to much. |
I actually select Others & Performance. As I’m using NumPy extensively for image processing, being able to directly address the GPU without requiring CuPy, for example, is extremely important if not critical. |
I believe that the numba project is very promising, and I would really love to see better cooperation between numba and numpy. |
Make it easier to use numba, dask, cython |
You guys are doing a great job, more connection to c++ And other high performance languages by promoting and explaining functionality in the documentation and media outlets, understanding and learning deeper abstractions by using numpy |
NumPy to be competitive performance with compiler-based tools that encourage less elegant programming styles |
parallel processing, utilizing specialized hardware (optionally) |
I get complaints about numpy vs matlab perfomance, mostly from people who’ve never used numpy. I know numpy is about as fast as Matlab, but haters gonna hate and taters gonna tate. |
Improve computational efficiency, especially for large arrays. (Original in Japanese: 提高计算效率,尤其针对大数组.) |
I code optimization solvers that have to do many small matrix-vector multiplications as part of the function, as in they can not be folded into some higher matrix operation, etc. I realize that this is a rather niche use case but is there anyway to bring down the calling overhead? For example a Ax with being a 5x5 is effectively no different in cost to A being a 30x30 on my machine. I think a small matrix optimization would do wonders. Also default linking to something other then MKL |
Perhaps an integrated integration with numba, so when you call a function on an array you could specify a how=numba type parameter |
Potentially include the use of GPUs. |
Specify arrays of fixed size so that certain functions run faster. I work a lot with small matrices, mostly for linear algebra stuff, so it would be nice to have functions optimized for certain sizes of arrays. |
Nothing in particular. I think as one of the go-to libraries for scientific computing Numpy should strive to maintain and improve the performance of its underlying functions, for current and future features. |
Could NumPy run on GPUs? |
Numpy is key for the Machine Learning.. Need Performance is the key factor |
more use of parallel computing |
Ability to automatically hand off certain operations to Intel MKL, Blitz, … libraries when available on the system and faster. |
I don’t have any ideas on how to improve it but it seems to me that it is always the most important thing and why it is used. I would love to collaborate on whatever development priority is taken. (Original in Spanish: No tengo ideas de como mejorar pero me parece que siempre es lo más importante y por lo que se lo usa. Me encantaría colaborar en cualquier prioridad que se tome de desarrollo.) |
I know NumPy already has a lot of vectorization and paralelization, but maybe including automatic paralelization using GPUs or coprocessors. Probably similar to what JAX does but built in in some core components of NumPy. |
By testing, indexing with numpy took much longer than the same function but with numba’s njit decorator. Perhaps you could adopt certain improvements that are invisible to the user. (Original in Spanish: Haciendo pruebas, el realizar un indexing con numpy se demoró mucho más que la misma función pero con el decorador njit de numba. Tal vez se podría adoptar ciertas mejoras que sean invisibles al usuario.) |
I just wanted to express that the most important thing for me would be the improved performance whenever possible. Probably incorporating parallelism in linear algebra libraries would be a good idea not that complicated to execute. (Original in Spanish: Lamentablemente no se me ocurre como solo quise expresar que lo más importante para mi sería que mejoren cada vez que pueden el rendimiento. Probablemente incorporar paralelismo en las librerías de álgebra lineal sería una buena idea no tan complicada de ejecutar. ) |
Use a lighter implementation closest to the function calls on cython. But without changes on the code, something easy to enable and disable. Using decorators maybe? |
Default inter-core parallelization options. (Original in Spanish: Opciones de paralelizacion entre núcleos por defecto.) |
I don’t have any suggestions, I just think that performance should be prioritized. |
More explanation on how to write more performant code |
I think numpy performance is spectacular, but I believe it should continue to be a focus. |
I have few good thoughts about this, I just believe that performance is most important. |
if ndarray was displayed how a matrix is displayed in matlab or R, it would be much more convenient |
I came from IDL and when I write the same algorithm in IDL it is almost always faster. Part of that is that I understand how to write to take advantage of the parts of IDL that are fast more than I do with NumPy, but even when I use the community-accepted best option, it is usually slower. |
Ways to perform array selection based off criterion for the indices and data value at the index simultaneously. |
Develop a portable binary file storage format for use from different languages (C, C++ and Fortran) Borrow ideas from pandas and incorporate in numpy. Pandas is slow compared to numpy but more robust that numpy. |
Use of GPU for some calculations |
Performance on the overall library is really good. It’s just that as my priorities go, it is the most important. |
There are certain tasks that require multiple passes of arrays that simply don’t need to do so, due to numpy’s heavy leaning into masks for certain queries. Numba of course helps mitigate a lot of these, but that’s a crutch for an obvious design flaw in numpy at it’s core. |
There is not much to improve, I put it there as it should always be the highest priority when changing/adding code and features |
Make everything even faster :) |
Make it easier to new users to access high performance code by means of jit or something similar. |
The performance of numpy is very important, as important as documentation and reliability. (Original in Spanish: El rendimiento de numpy es muy potente y esa potencia debería de ser igual como en documentación y fiabilidad.) |
It is important to measure the execution time looking for opportunities for improvement. (Original in Spanish: Es importante medir el tiempo de ejecución buscando oportunidades de mejora.) |
Improving performance through parallelism. (Original in Spanish: Mejorando el rendimiento por medio de paralelismo.) |
More support for parallel programming, CUDA or vectorization of custom functions. |
Parallel computing, improved algorithms |
GPU support |
Use code acceleration (GPU, TPU) similar to PyTorch and JAX. (Original in Russian: Использовать различные ускорения кода (GPU, TPU). Например как в PyTorch, JAX.) |
Performance is great. It should just stay a priority. |
I have used numpy as the basic library in many large research projects, performance is usually more than adequate. A challenge has been to profile large programs using numpy. |
Make it “Faster”! |
Fix Memory usage, restrictions and support on various platforms. |
JIT compilation, easy parallel / GPU support |
improve memory-access critical operations |
Native distributed, multi-threaded numpy. |
I guess I’m really looking at Numba and Dask for this… |
Improved speed, intuitive function design. (Original in Japanese: 速度の向上、直感的に操作できるような関数の設計.) |
The performance is quite good for my uses - I just think it should be maintained |
It’s already good but it can be made even better. |
To process and handle large distributed data. |
gpu support |
Logic that processes large numbers of calculations as constraints. (Original in Japanese: 大量計算を拘束に処理するロジック.) |
the race for better technology is always won by performance and reliability. That’s why I kept them in higher priority. |
Add Numba like JIT support. A specific set of IR can be purposed. |
Support to Gpus |
Adding GPU support for accelerated matrix operations |
Further improvements in multicore and multithreading. Packages to support hpc usage |
I use NumPy because it is very fast at most tasks. |
General speed improvements. |
e.g. Put np.min and np.max in one func |
Complex expressions may create temporary arrays behind the scenes. Would be nice if clever coding in the interior of numpy eliminated this. |
It is perfect. |
NumPy is outdated in terms of leveraging new hardware instructions and there is a lot of room for improvement. |
Goes together with ‘New Feature’ below: I would like a better way of addressing specific axis in a multidimensional array. Right now I’m tampering with numpy.s_ and direct calls to getitem, but I’m not satisfied with that. It is also not usable in numba compiled code and this limits me. |
I don’t have many ideas on the topic. I know that there have been already a lot of work on performance, and that more SSE/AVX vectorized implementations are on the way. I imagine things can always be improved somewhat given enough effort of benchmarking, profiling etc. |
Plus easy to optimize the programs. (Original in French: Plus facile optimiser les programmes.) |
GPU |
Explicit standardization of core API so other tools can be swapped in as backends for parallel or GPU computing |
making use of GPU |
Integrate new features from Intel MKL & BLAS libraries. Optimize performance on new processors with high core counts like AMD’s Threadripper CPUs. |
Maybe via Numba. |
Automatically take advantage of multi cores where feasible |
Better Sync with DL based frameworks. |
NumPy differential equation solving is slow. |
Automatic detection of GPU, support for multithreading |
Heterogenous ops |
More documentation on best practices for performance, tips and tricks etc, would make it easier to get the performance that may already be there but currently requires a lot of extra knowledge to obtain. |
Would be great if Numpy had native GPU support, although CuPy essentially makes most applications possible. Would be great to have more options for distributed array computing. |
Make use of GPU acceleration (e.g. allow use of alternative underlying Fortran code with added OpenACC directives, even if only for some common operations) |
Continue to find most computationally efficient methods of executing code. |
Community organizing around nep-18 |
You might be able to provide a separate option to inherently parallelize certain functions, and/or provide examples on using numpy with other packages that might boost performance. |
I don’t think, performance is an issue as of now. It is just, that I think (in general) numpy is in a state where I don’t have much to complain about and performance gains are always nice… |
Reduce memory consumption. (Original in Spanish: Reducir el consumo de memoria.) |
Faster code is always helpful |
Parallelization, GPU |
Add GPU Support |
NumPy should use numba. |
Numpy is really fast, and I don’t have a ton of experience in making it faster. However, I always fall back on numpy for code optimization and I think it is an important place to focus resources. |
expanded randomized linear algebra routines |
Automatic execution on GPUs |
I primarily use NumPy to analyze large data sets. Loading those data sets (up to 2GB of csv files) with NumPy is not the most time efficient and eats up a lot of memory. |
I have no knowledge on this subject, but believe NumPy’s main usefulness to the scientific community is high performance. This should continue to be a priority. |
Enable gpu support wherever it can be used |
One specific problem (which is not purely numpy related) I have is the difficulty to parallelize my Python codes, given the ease in other languages like Julia and C++ |
Provide benchmark suite that we can run on platforms at our disposal. Python, owing to its nature (e.g. OpenCV interfaces), is slower compared to same set of operations on other platforms. This handicap makes it a tougher “sell” in mainstream IT departments. |
Performance should always be top priority. |
I’m not sure. Just make sure it performs well. |
Make sure it works as efficiently as possible. |
Performance is the key value prop for numpy versus pure Python implementations of algorithms. |
The performance concerns are mainly around masked arrays, which can be extraordinarily slow. |
Identify areas where current algorithms are highly sub-optimal or where there are advanced algorithms that perform much better. I think of numpy and scipy together here. For example, numpy median filters are much slower than implementations in other languages such as IDL, and are far slower than optimal algorithms. The last time I tested, the numpy histogram algorithm was very slow. |
The work on vectorization sounds great. There are also some parts of NumPy that could be optimized (like 2D regular binned histograms). As far as I know, the Windows NumPy does not yet include the expression fusing that Unix does, which would be nice. (Most these are just light-weight suggestions, I work further down from NumPy usually, but since so much relies on NumPy, performance gains can affect a huge community) |
1. The core of Numpy written in C should use the new hpy API so that it would be possible for PyPy (and other Python implementations) to accelerate Numpy code. 2. It should be clearly mentioned in the website / documentation that to get high performance, numerical kernels have to be accelerated with tools like Transonic, Numba, Pythran, Cython, … See http://www.legi.grenoble-inp.fr/people/Pierre.Augier/transonic-vision.html |
I work in HPC so I am always thinking about performance. Many functions are already fast but more speed is always better. :) |
I don’t have any specific thoughts, but faster is better :) |
I’d love to see NumPy as the de facto array computing API, with other packages voluntarily choosing to allow interoperability. |
In general, I’m pretty happy with the current state of NumPy, so general performance gains of numeric routines and aggregations still be a great way to continue to improve NumPy. |
It would be really nice if the FFT in NumPy were “best in class.” Typically FFTW performs better than KissFFT (which I think is the basis for NumPy) but there are licensing issues so FFTW itself can’t be used. |
I’m very impressed with the direction of performance - keep on rocking! |
Improve interoperability with numba & cupy. |
Very large data set performance |
Improve support for intrinsics / SIMD instructions. |
Integration of acceleration by GPU natively. (Original in Spanish: Integración de la aceleración por gpu de forma nativa.) |
I found the performance of NumPy fantastic. |
Guides and recommendations or use cases on how to perform the functions in a parallelized way. (Original in Spanish: Guías y recomendaciones o implementaciones para realizar las funciones de forma paralelizada.) |
parallelization, SIMD |
There are increasing opportunities for processing large amounts of data. I hope it will be a little faster. (Original in Japanese: 大量データの処理の機会が増えてきています。) 少しでも早くなることを期待します |
Create standard benchmarks so they can be evaluated. (Original in Japanese: 標準ベンチマークを作成して、評価できるようにする.) |
Increase processing speed. (Original in Japanese: 処理速度を早くする.) |
Speed up of vectorized functions. (Original in Japanese: ベクトル化した関数の速度向上.) |
Jit compiler (numba/torchscript like maybe) to allow “kernel fusion” e.g. make for i in x: for j in y: for k in z: some complex operation per matrix entry fast. |
Numpy has great performance; however, the project is “old”. Perhaps a reformulation in the basic code would bring an even better performance. (Original in Portuguese: Numpy tem ótima performance; contudo, o projeto é “antigo”. Talvez uma reformulação no código básico traria uma performance ainda melhor.) |
Parallel computing support, memory saving, or organizing documents to do them. (Original in Japanese: 並列計算の支援、省メモリ、あるいはそれらを行うためのドキュメントの整理.) |
Improve the use of partner libraries or reformulate the code, aiming at high performance and preparation for use in quantum computing. (Original in Portuguese: Melhorar o uso de bibliotecas parceiras ou códigos reformulados, visando performance elevada e preparação para uso em computação quântica.) |
Make it faster and more efficient |
Doing performance benchmarks with other libs that does the same (maybe even in other languages). |
Improve algorithms implementations with latest research |
After getting done from SIMD optimizations, I was thinking about to add direct support for OpenCL & Cuda |
Speed especially with very large arrays |
No specific thoughts on how to improve - just that I believe performance is a cornerstone of what makes NumPy so valuable and widely used (in conjunction with the expressive array syntax). IMO it is important for NumPy to maintain high performance to prevent ecosystem fragmentation with the introduction of many new array computation libraries (e.g. PyTorch). |
More widespread usage of multithreading. |
It is not really necessary to improve performance and reliability in any specific way. But it is important that you maintain them and keep good performance as it was before. |
Benchmark against Julia. |
I think there are ideas about using more vectorisation (with SIMD instructions), which seems interesting. More generally better performance with respect to use of multiple CPUs and memory allocation is always good to take. |
Numpy in already extremely fast. But as more and more data is coming, Numpy has to be faster in many operations |
Include ARM compliance and performance testing as a priority (with a view to macOS but also recent super computer usage). |
Increase use of vector instruction (AVX, Neon …) Make numpy more friendly to JIT compiler like numba |
faster small arrays |
Allow SIMD access from all platforms, move to more modern glibc beyond manylinux2014 |
continued work on SIMD acceleration of ufuncs, etc. |
Make it go faster and better. Benchmarked optimizations. |
Integrate simd and task-based multithreading (e.g. tbb) throughout |
Keep doing what you are. I don’t think performance is broken as it stands. |
I dont have specific targets, just anything that makes it generally faster is helpful in nearly all scenarios |
NumPy is becoming the de facto way of handling data, it should strive to be the best possible tool. |
Exposing C APIs for more modules, to be used via Cython |
Multiple low-level backends (eg MKL) with dynamical switching. OpenMP low-level parallelism |
Compare the python library random to numpy.random. there are certain scenarios where one is better than the other. For instance, if you want to generate multiple random numbers random.uniform is better; but numpy.random.sample is superior for sampling from a list. It’d be nice to have numpy superior at all times |
Scaling out, compatibility with other libraries or data types |
Build a stronger, highly active community. I would like to see seminars and conferences like tensorflow |
Do multi threaded or multi processing calculations wherever possible without or with very few user interaction. |
There isn’t a performance shortfall, but continuing to optimize the library and say optimized is always important. |
I am just a user of NumPy (and a big fan!), but what I see with performance is: / 1. People not efficiently using NumPy so that they think NumPy is too slow, just because their code is not optimized. This is why documentation and presenting the most optimized solutions is so important. / 2. I tried messing around with CuPy and I had some graphic card issues, so my experience is limited, but is it crazy or out of scope to want GPU support in NumPy for some things? |
I’m always interested in improved performance. It doesn’t require any work from me but I still benefit from it |
The linear algebra module could see some improvement, (not my area of expertise, so I’m not sure how it could be improved). |
I’d love to see support for accelerators and massive parallelism (via XLA as in Jax for example) land in NumPy. |
Speed up computation process. Currently, we need other packages like Numba, NumExpr, or Cupy. It will be interesting to have speed without any additional packages. |
Reliability¶
115 participants shared their thoughts on reliability and how it can be improved.
Click to expand!
Comments |
|---|
If you want people to use the library, reliability is a top priority. |
As NumPy is a library that is widely used both professionally and academically, it is certain to guarantee high performance and reliability. (Original in Portuguese: Como NumPy é uma biblioteca de vasto uso tanto em âmbito profissional como acadêmico, é certo garantir alta performance e confiabilidade.) |
I think reliability must be a top priority, no matter what. Being correct must be more important than any other aspect of NumPy. I believe that NumPy does a great job in this respect. I selected reliability as a top priority to keep seeing this. |
TBH I just gave this a very high priority because that is the aspect of the code I maintain I’ve been most focusing on lately, so I think it’s a crucial selling-point for any library. I don’t have a suggestion off the top of my head as far as numpy is concerned. I find most of the error messages I usually encounter are very helpful and I rarely find myself scratching my head over some error that looks unrelated to what I’m actually trying to do. That said, I do believe that issues related to user experience should be given a very high priority as numpy is the core package that everyone uses in my branch (astrophysics) and its behaviour inspires many lesser developers who need an example for excellence. |
Expanded testing features |
Improvements in the documentation so that people use the correct functions for their intended purpose. |
numpy still has a few inconsistencies originating its early days. Those should be cleaned up. |
Adopting property-based testing. See eg https://doi.org/10.25080/majora-342d178e-016 |
Again as a core component of the pydata ecosystem, reliability and API consistency is mandatory and numpy is known for that reliability, I would try to make sure it’s sustainable. |
It’s already amazing. Please keep it that way by careful and measured pace of development, focusing on testing and bug fixes. |
Sometimes the errors are too obscure |
I think NumPy is very reliable, I just think that it is important to maintain this reliability! |
Never had problems so far but I think it is super important. |
Open to this improving however possible. |
Same as performance. Reliability should always be top priority. as the core of many widely used python libraries, if numpy stops being reliable, it would be a big issue. |
Making sure it keeps compatibility with latest releases of e.g. matplotlib and pandas. |
I would like to make Numpy as an easy to install and use in any machine without any hurdles. we can provide an API alternative to run Numpy server in cloud to access anywhere without installation. Include more features to assist developer needs. |
Unification of some functions that do almost the same thing; harmonization of optional parameters. (Original in French: Unification de certaines fonctions qui effectuent presque la même chose ; harmonisation des paramètres optionnels.) |
I think it is already quite reliable, but that is a feature I value highly |
I have no reason to think that NumPy is unreliable, but reliability is always important |
It is fully reliable, keep it this way. Do not break backwards compatibility. |
Maintain the high level! |
Reduce bugs. (Original in Japanese: 减少bug.) |
Add type annotations for all input and output data. |
Numpy creates the foundation for many critical machine learning and deep learning. Should be bug free in their key functions |
I have no idea but it seems to me that it is a strength that you have to have. I would love to collaborate on whatever development priority is taken. (Original in Spanish: Tampoco tengo ideas pero me parece que es un fuerte que se tiene que tener. Me encantaría colaborar en cualquier prioridad que se tome de desarrollo.) |
It is difficult for a non-expert user to understand the precision of floating numbers and alike. Keep in mind that very often the users of NumPy don’t have any background in software development. (Original in Spanish: Es difícil para un usuario no experto darse cuenta sobre precisión de números flotantes o similares. Considerar que muchas veces gente que no viene del área de la computación entra al mundo de numpy.) |
NumPy is already very reliable. I just wanted to highlight that this quality standard should be maintained when implementing new features or increasing performance, i.e, reliability & new features fast / performance increase. |
I don’t have any suggestions, I just think that reliability should be prioritized. |
Nothing in particular, simply that it should be a priority over most other things. |
Reliability of numpy is good. Just need to sustain it. |
Improve the visibility of current tests and add test capacity to show numerical stability between versions. The main idea would be to have easy ways to trace from strange behavior in my user tests to tests of the numpy components that I am using so that I can quickly discriminate the source of the problem. (Original in Spanish: Mejorar la visibilidad de los test actuales y añadir capacidad de test para mostrar la estabilidad numérica entre versiones. La idea principal sería tener formas fáciles de trazar desde un comportamiento extraño en mis test de usuario a los tests de los componentes de numpy que estoy empleando para poder discriminar rápidamente el origen del problema.) |
Currently, I have no issues with the reliability of NumPy, but this feature should be one of the main targets in future development. Furthermore, the interoperation between NumPy and many other modules/packages like Pytorch and Tensorflow should be guaranteed. |
Numpy is reliable right now, but I find it important that it continues to be. |
For scientific and academic work, reliability is key. When a calculation takes several hours/days to compute, NumPy has to work reliable. And it already does – at least I never had problems. However, this should always be taken in consideration when changing/adding code or features. |
Make an arrange more exact, for example if I put numpy.arrange (-1,1,0.001), sometimes it can reach values of 0.5000000001 or 0.499999999, instead of 0.5 so sometimes the arrange is not so exact, it is not something so urgent, but it would be good if they could be more exact in certain operations. (Original in Spanish: Hacer más exacto un arrange, por ejemplo si pongo numpy.arrange(-1,1,0.001), a veces puede llegar a valores de 0.5000000001 o 0.499999999, en vez de 0.5 por lo que a veces los arrange no son tan exactos, no es algo tan urgente, pero sería bueno que pudieran ser más exactos en ciertas operaciones.) |
Make the API as backwards compatible as possible. |
Numpy one of the most reliable packages I am using. I never had a problem upgrading to a newer version and can’t remember ever facing a numpy bug. Thanks lot for this quality. |
Reliability is currently sound. Am merely suggesting that reliability remain a priority. |
Just keep up the good work |
Truthfully, I am very happy with NumPy as it is right now. I have no complaints! But I couldn’t say that in the previous slide. So, if I had to pick a priority, reliability is in general my highest priority because we use NumPy in production. |
Specifying the shape/strides of arrays can be very important for using NumPy arrays from C++ using pybind11. If you are not very careful about types, unnecessary copying occurs. Although NumPy usually allocates C-style arrays, having a guarantee ahead of time (when creating the first array) would avoid help avoid excessive memory usage. |
Don’t break anything ;-) |
Reliability seems good as well, but its one of those things that requires continue maintenance |
Masked arrays do not always perform as expected. I had to rewrite some of my code to not use masked arrays because I was getting incorrect results. This might have been a documentation issue or a limitation in masked arrays so I didn’t report it as a bug although it might have been. |
Able to support and load multiple platforms |
Stabilize the API |
numpy is already very reliable but maintaining this reliability is important when updating the package (I had a hard time ordering things because numpy already does everything I need it to + more, is relatively easy to use, and has some of the best documentation I have ever seen) |
I use numpy for my calculations. I want to know that they are correct. |
The reliability is already good. New developments should not ruin that. |
I count on that numpy work as expected in my work and free time |
Just continue doing the excellent work on reliability that the core team has been doing so far. |
Stay as it is. (Original in French: Rester comme ce l’est.) |
make apis more consistent to reduce accidental bugs |
The ranking was tough for me to do. I should say, I ranked reliability as a high priority not because I thought numpy was not reliable, but because I view that reliability is absolutely critical. |
Stable API for GPU |
No regressions please |
Talk to community to create new test cases from real-world applications. |
Make sure small version changes don’t break existing features of the package. |
Elevation to quad precision where loss of precision is detected |
Communication of any changes that are not backwards compatible. Keeping strong testing standards to ensure new features don’t break existing code. |
I have no issues currently, and ensuring that exhaustive testing is performed for future changes will ensure this stays true |
Fewer breaking changes. Reproducibility of NumPy-based work is not great. |
Long term stability and backward compatibility |
I’ve never had reliability issues with the parts of numpy I use. I use mainstream hardware. But I perceive numpy as being in a foundational place in the stack, so reliability is crucial and difficult to maintain. Keep on the good work in prioritizing it. |
Interpreting reliability as reproducibility, avoid numerical differences between different platforms (eg processors). (Original in Spanish: Interpretando fiabilidad como reproducibilidad, evitar diferencias numéricas entre distintas plataformas (p.ej. procesadores).) |
More consistency |
I think clarifying a lot of the c like behaviour and edge cases could help. Possibly runtime warning for view vs copy |
None, I am not well versed in computer science but believe reliability should be a high priority in general. |
It’s good. Just don’t trade new feature for quality ! |
Expand on NEP 18 please, as the clarity of the NumPy API is crucial for the libraries that build off of it |
Technical support is hard on both sides of the fence. The need for technical support should be minimized by providing stable solutions with a traceable log of current status. |
I want to know that I will not encounter problems with it. |
Reliability (in the sense of presenting a long term stable API in particular) is something that needs to be improved in numpy. |
In my mind, reliability means decreasing the chance that unexpected errors or wrong results can occur due to e.g. rare data cases, or a user’s subtle misunderstanding of function semantics. I don’t consider myself knowledgeable enough on np’s internals or development to really suggest specific plans for how to improve reliability, but I imagine that better documentation can help prevent users’ from doing operations they don’t realize are “unsafe”. Also more built-in checking could be added, though of course this needs to be balanced against performance impact. As another enhancement that partly touches reliability, I would appreciate better support for missing data. This is a common cause of runtime errors that are not immediately noticed in development, both directly in my code and when passing data to other libraries. (I would especially appreciate missing data functionality that integrates well with pandas and similar parts of the ecosystem.) Another very different idea would be to enhance support for static type checking, via offering a more official distribution of type annotations and eventually a full-featured type system such that checkers could enforce data types and shapes. |
Nothing specific here – but attention to reliability is always a good idea. |
I don’t have any specific advice, NumPy already seems highly reliable, but as a core package for most of my stack I think reliability is critically important to maintain. |
Keep up the great standards! |
Keep tackling bugs as they pop up. |
Critical business decisions can be based on pipelines using Numpy. As such, (numerical) reliability should always be the top priority. |
Reliability is very good and that should stay and not be compromised by moving other things up in priority. That is why I put it on position 1. |
The reliability is something I’m interested in it, because different versions of NumPy may not be compatible. |
Just like it is done today (unit testing) |
Inconsistencies in the dtypes. (Original in Spanish: Inconsistencias en los dtypes.) |
I am happy that the content is highly reliable. I am happy that the documents can be provided in Japanese, but I would like you to do so while maintaining reliability. (Original in Japanese: 内容的な信頼度が高いと嬉しい. 日本語での文書提供が可能だと嬉しいが、信頼度を保ちながら行って欲しい.) |
Fix bugs! |
Make tree-structured page of reference doc. (Original in Japanese: ツリーで構造化されたリファレンスページの作成.) |
Assess security aspects in software development to avoid malicious use of open source. (Original in Portuguese: Avaliar aspectos de segurança nos códigos desenvolvidos para não permitir fácil invasão ou uso malicioso de código aberto.) |
Make sure it is accessible |
Having multiple kind of automated tests and a high coverage codebase. |
Making sure bugs are quickly addressed and fixed, improving the usability on windows and other platforms |
Reliability goes hand in hand with API consistency. Recent version made some expressions just harder, especially when object arrays are involved. Some rules are convenient, but not consistent - e.g., it is not obvious len(numpy.array([[1,2,3],[1,2,3]]).shape) != len(numpy.array([[1,2,3],[2,3]]).shape). |
I’m not sure how reliability could be improved, but I believe reliability must remain a very high priority for NumPy. |
Reliability is already excellent. It remains a top priority. Tests coverage is key, naturally. |
Numpy is doing a great job in terms of stability and reliability, not sure how to increase it, it just seems an important point for a package that is at the root of all the scientific python ecosystem. |
I find numpy quite reliable — I just think this needs to remain true above all other potential changes. |
By making it available to more and more programming languages |
NumPy generally sets itself high standards on things like backward compatibility and a deprecation process for changes. Keep this up please. |
Nothing out of the ordinary, I feel that NumPy is in a good place right now with regards to its reliability. |
testing, testing and probably testing. The number of architectures is growing in the HPC world, amd64 has competitors with arm64 and ppc64le. Ensuring reliability on those platforms is of crucial importance. |
Reinforce the commitment that NumPy will remain open to everyone, considering changes to license terms as recently proposed would cause concerns as to future reliability of NumPy for a large portion of the industry. For me personally, I would not anymore contribute to NumPy, as the essence of OSS would be killed. |
I find NumPy to be very reliable. Given its position at the core of the Scientific Python ecosystem, I would like to see NumPy keep the same level of reliability in the future. |
reduce the API surface and dtype quirks |
Bug fixes. More unit tests. Most of my code contributions were necessary because of lack of code coverage. They were corner cases, but obvious ones for the most part. |
Increase testing, instrumented fuzzing |
ensure that version release don’t impact code within numpy. |
Reducing scope: clarifying switch APIs are supported and deprecating/removing edge behavior (e.g., indexing) |
Keep doing what you are. Continue to maintain good backwards compatibility (we test against versions back to 1.14) |
I haven’t noticed any problems with reliability – I just think it’s more important than the rest. |
Again nothing new here as well, Numpy is reliable and I hope it stays that way |
Facilitate the publication of issues, and find ways to finance the solution of these issues. (Original in Spanish: Facilitar la publicación de issues, y buscar formas de financiar la solución de estos issues.) |
Be robust to multiple runtimes (eg multiple OpenMP implementations) in the same interpreter. This does happen, and leads to subtle breakage. |
Numpy is already pretty reliable :) I guess being as explicit as possible with error strings is always helpful. I also found that if i happen to be stuck with a numpy array with the object dtype (a large array was saved within a list of lists) then it can get pretty messy to go back to ndarray. I had to recursively call np.vstack on the sub-arrays, even though everything was a float. |
NumPy is becoming the de facto way of handling data, it should strive to be the best possible tool. |
Some tiny changes matter (string representations for instance). When they change, some tests start to fail. |
Website¶
Finally, 40 participants selected the NumPy website as a top priority and shared their thoughts on how it could be improved.
Click to expand!
Comments |
|---|
fonts are too small on Firefox, lot of white space. |
ReadTheDocs, but not with the default skin |
The new design at numpy.org looks great so just carry on with that really. I think in general, numpy doesn’t really get the credit it deserves due it being such a core part of so many other scientific libraries so I like the case studies |
NEP 28 — numpy.org website redesign :) |
Last time I checked the front page it was impossible to get to the actual documentation. But it has changed since I last checked. |
General improvement of the readability of the Numpy Reference, e.g. something like the new Pandas reference. |
Material UI, easier search, hide old versions from google |
- search results on documentation are unreliable / do not give what I was looking for - merge scipy and numpy documentation or make it clearer wich one I need for what - add more stuff here: https://numpy.org/doc/stable/user/howtos_index.html |
More intuitive directory. More extensive examples per function, trying to make use of most of the arguments of the function. I think the new Pandas web looks pretty good and would be a good match of style for numpy too, but in any case content is a priority over style. |
Use animations to explain what some commands do, such as handling arrays. (Original in Spanish: Usar animaciones para explicar que hacen algunos comandos, como por ejemplo el manejo de los array.) |
Make the documentation part of the website look more modern. Have better, more readable fonts and better organizational structure. Make it less white. It hurts the eyes. |
make it easier to keep an overview of different sections and navigate between them (maybe by enlarging the top bar). |
Please enhance the tutorials. (Original in Japanese: チュートリアルを充実させてほしい.) |
Fewer clicks to reach the documentation. |
While the internet has a lot of other sources for looking up key features/implementation details/tutorials on the how and why NumPy does things, as a fairly fundamental package (especially in the scientific community!) it would be very helpful to have a single centralised source of information (+ a “cookbook” of sorts for useful non-one-liners) with a user friendly way of navigating to relevant information (as per NEP 28). This would be especially useful for newer users (or even newcomers to Python!), and I think that a strong website would help showcase the functionality and utility befitting such a fundamentally useful tool! |
Site map and navigation aids |
Not sure, but I really like the new changes :) |
Higher priority on examples over strict API documentation. |
Make documentation site redesign otherwise I can not miss feeling that it is very old tools that it is abandoned. Make proper search. Currently, it shows titles only |
Updated documentation page that’s easier to navigate. For example: a table of contents that remains visible while you scroll down the page. |
Integrate online documentation into new website branding better. |
I really like that numpy switched into its own domain recently, and the new homepage. The documentation doesn’t seem to fit with the new website though: a consistent theme would be really nice. Getting started with numpy took me a long time originally (mostly since I didn’t have a strong background in linear algebra, the whole point of a multidimensional array didn’t click with me immediately). |
nice clear examples and guides |
The search function could use improvement; when searching for functions (ie np.repeat) as “repeat” it’ll return the named function later than expected; additionally it will return various results above it which can be confusing to new users. |
A website which has modern look and feel works on all screen sizes. |
New front page numpy.org looks great! |
Maybe making it more modern will attract interest. Make it easier to find docs, then always relying on Google. |
API documentation Getting started with numpys more advanced features Common performance pitfalls section, with examples |
The new front page looks fantastic. The “documentation” and “learn” sections provide so many different places to start learning that I’m not sure where to direct new Python users. I understand this is being improved under NEP 44. |
Better search, easier navigation into submodules |
add best practice and/or performance comparison of optimal/sub-optimal ways to use each functions |
The recent redesign is very good, but it has to be polished. |
When you search “numpy” on google.co.jp, please do something that the official page comes up high in search results. (Original in Japanese: 日本語でnumpyとGoogle検索をしたとき、公式ページが検索結果上位に来ない点をどうにかしてほしい。) |
There are no specific suggestions, but at the moment I’m having difficulty finding the explanation of the function I am looking for. (Original in Japanese: 具体的な案はないが、現状では探している機能の説明にアクセスしづらいと感じている.) |
A lot of documentation with a lot of tutorials would be good. (Original in Japanese: チュートリアルが豊富なドキュメントが多いと良い.) |
I think it would be good to be able to browse the website in multiple languages. (Original in Japanese: 多言語でのウェブサイト閲覧が可能にするのが良いと思います。) |
Clone tensorflow, or similar. |
More examples / Ensure examples demonstrate breadth of features / Possible code execution on site? |
More documentation. |
The numpy documentation looks dull and boring. It needs a fresh look. |
Summary¶
The following figure shows the relative frequency of selection for each of the listed categories1 at each priority level.
fig, axes = plt.subplots(3, 2, figsize=(12, 8))
for i, ax in enumerate(axes.ravel()):
priority_level = i + 1
cnts = np.sum(raw == priority_level, axis=0)[I]
ax.barh(np.arange(cnts.shape[0]), 100 * cnts / cnts.sum(), tick_label=labels)
ax.set_title(f"Priority: {priority_level}")
fig.tight_layout()
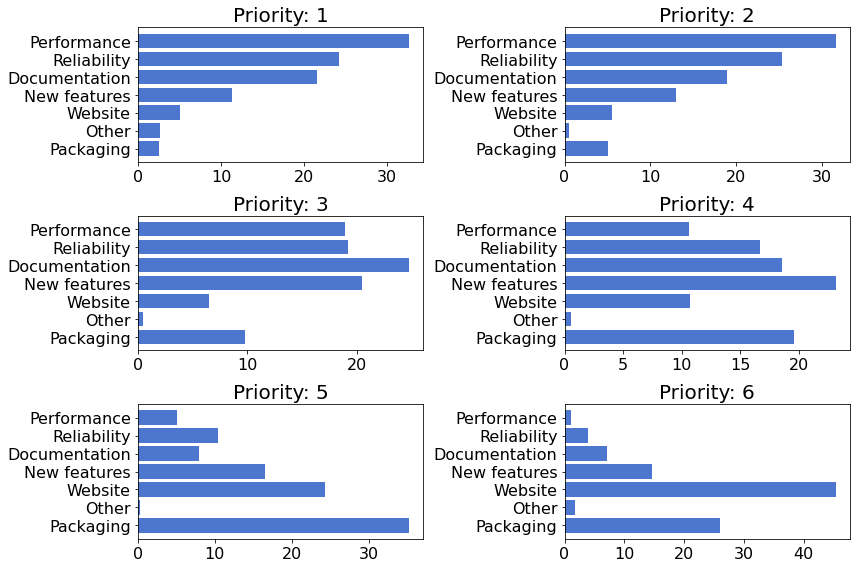
- 1
Excluding
Other, which was an optional category and therefore constitutes the majority of the “lowest-priority”.